一、对于LLM的两种期待
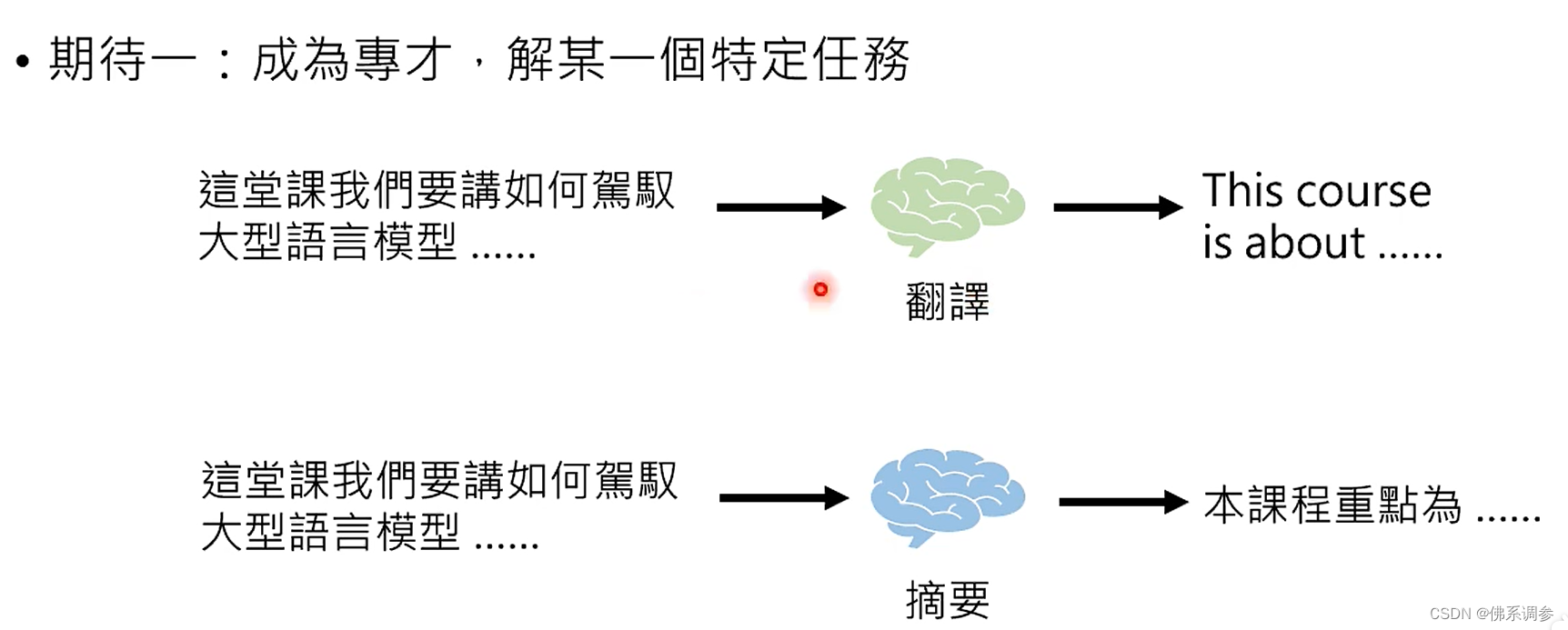
1. 成为专才,能够解决某一个特定任务。例如翻译,生成摘要
成为专才的好处: 专才在某一个任务上有机会赢过通才,例如目前chatGPT的文本翻译性能不如专门的谷歌或者腾讯的专门翻译模型
2. 成为通才
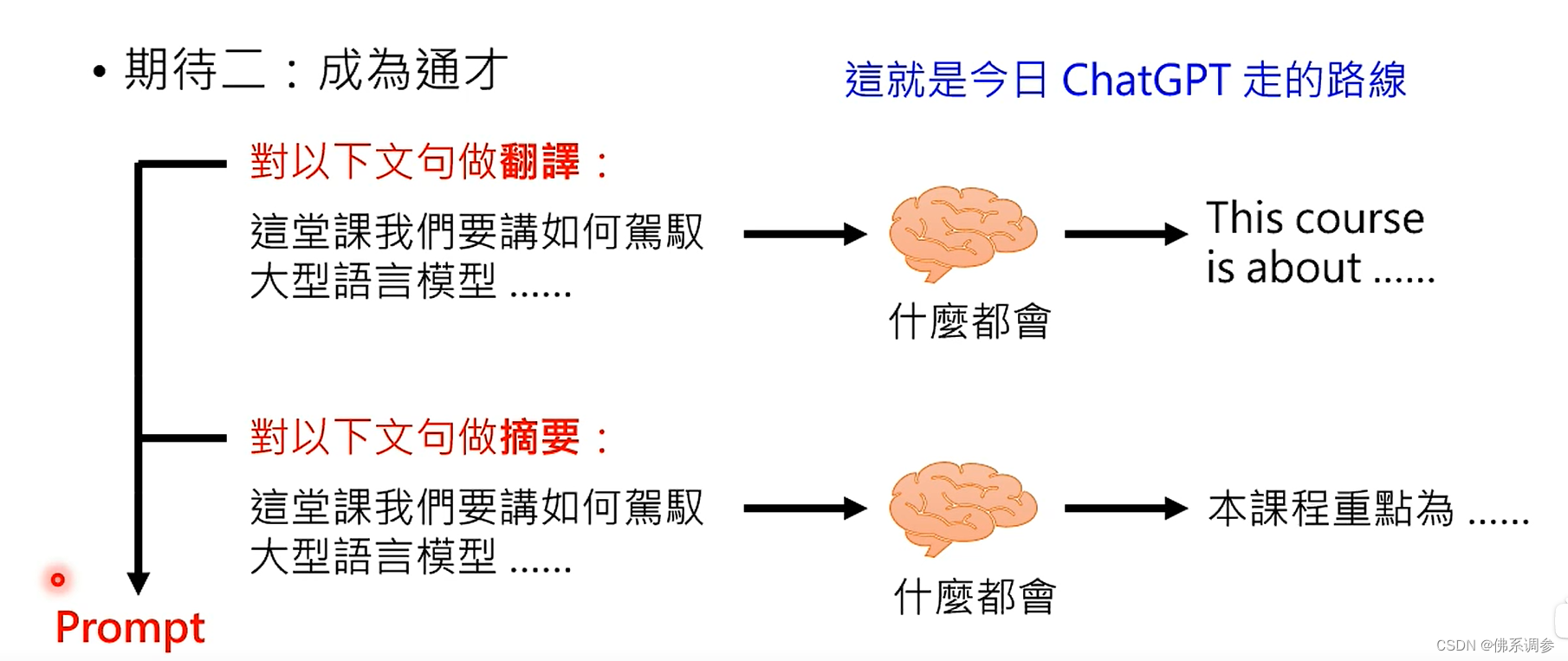
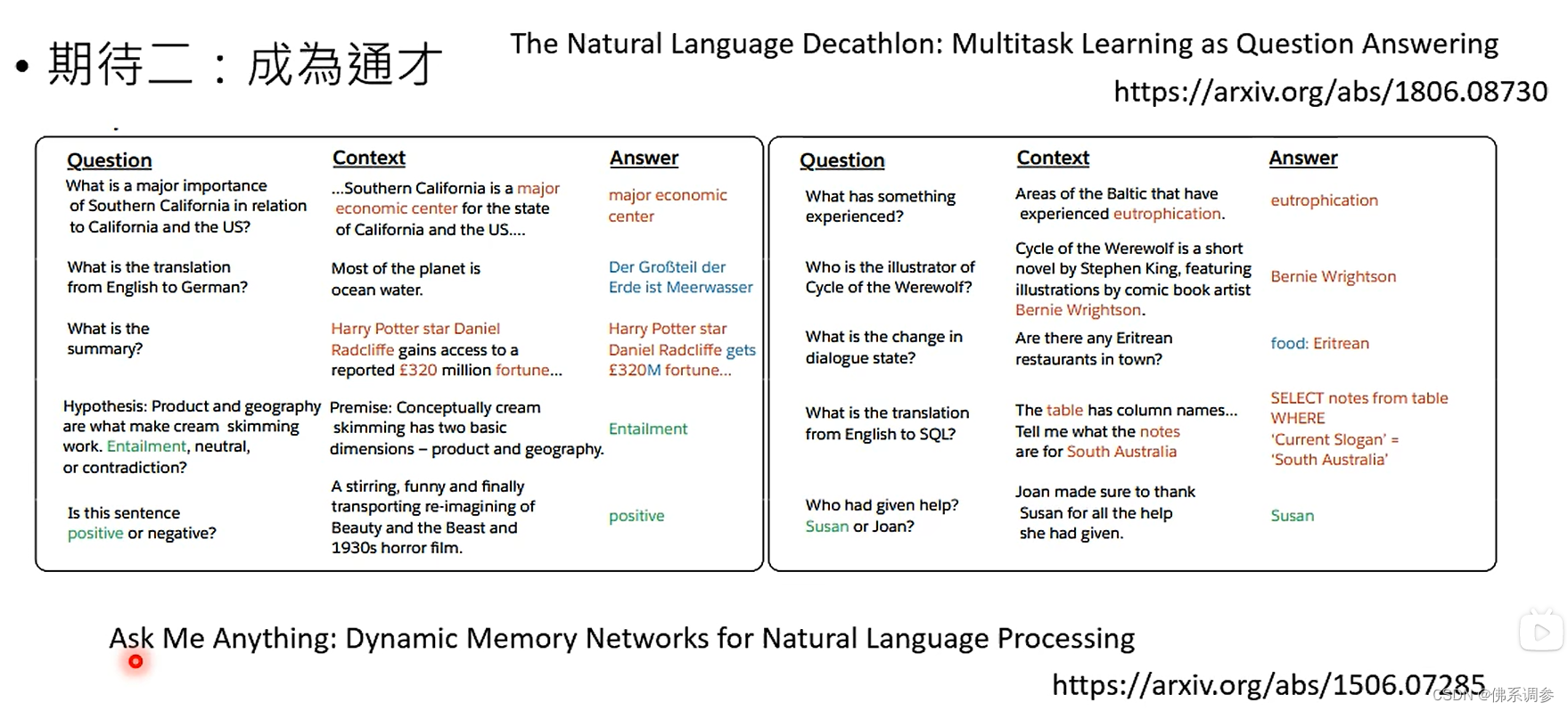
成为通才的好处:
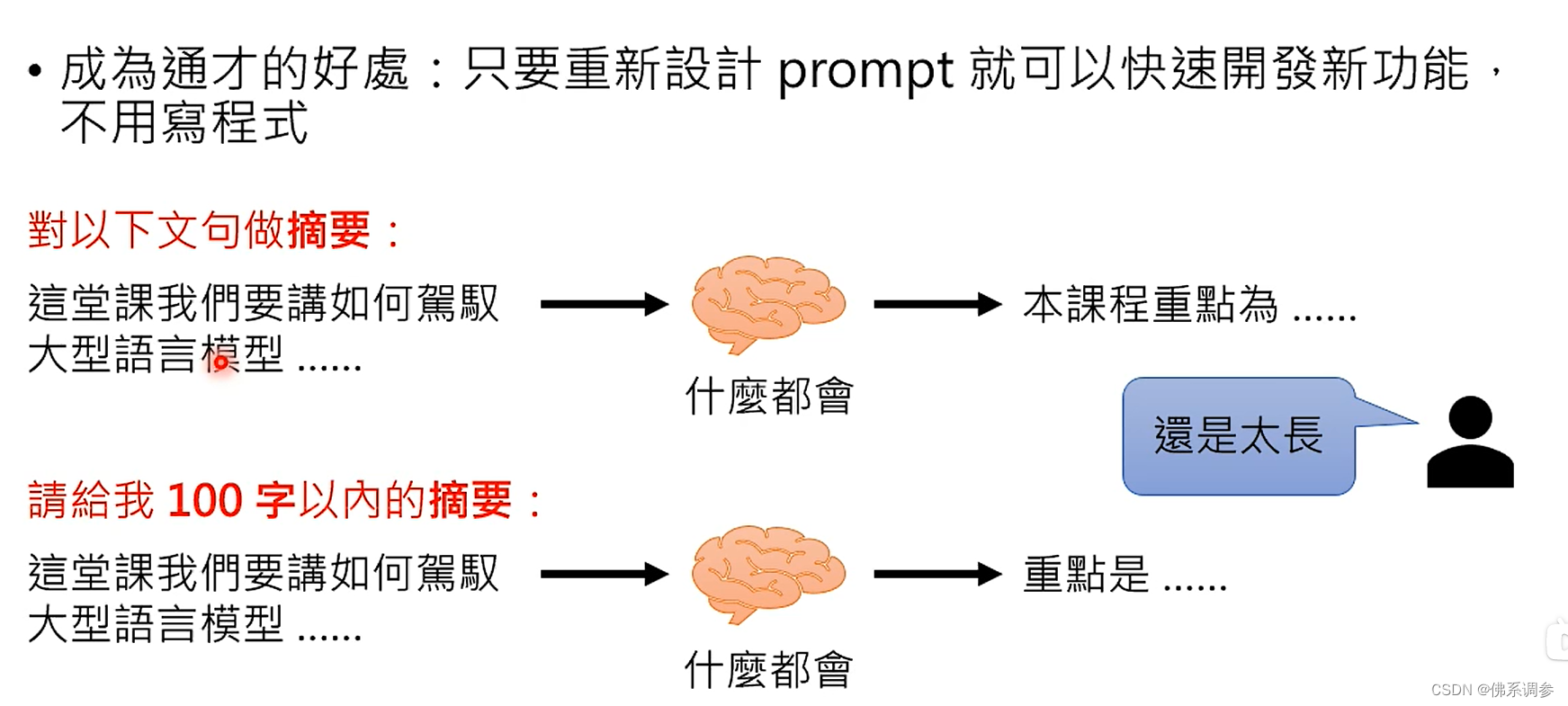
只需要重新设计prompt就可以快速开发新功能,不用重新写程序
二、实现方法
1.成为专才的做法
1.在模型基础上增加新的输出层(head)
2.然后采用参数微调Finetune方式进行训练, 需要标注好的数据
- 一种方式是也需要对大模型的参数进行梯度更新
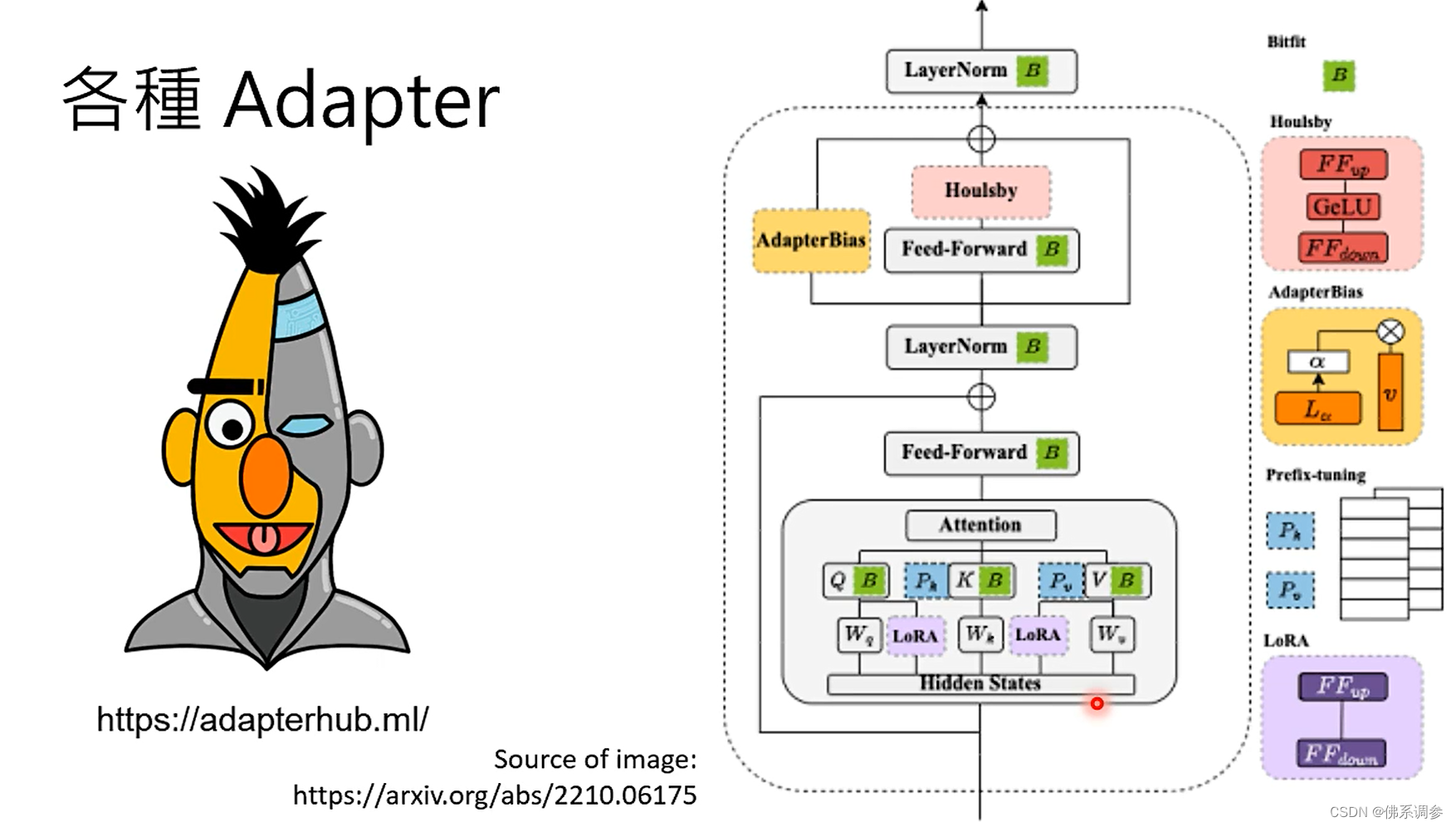
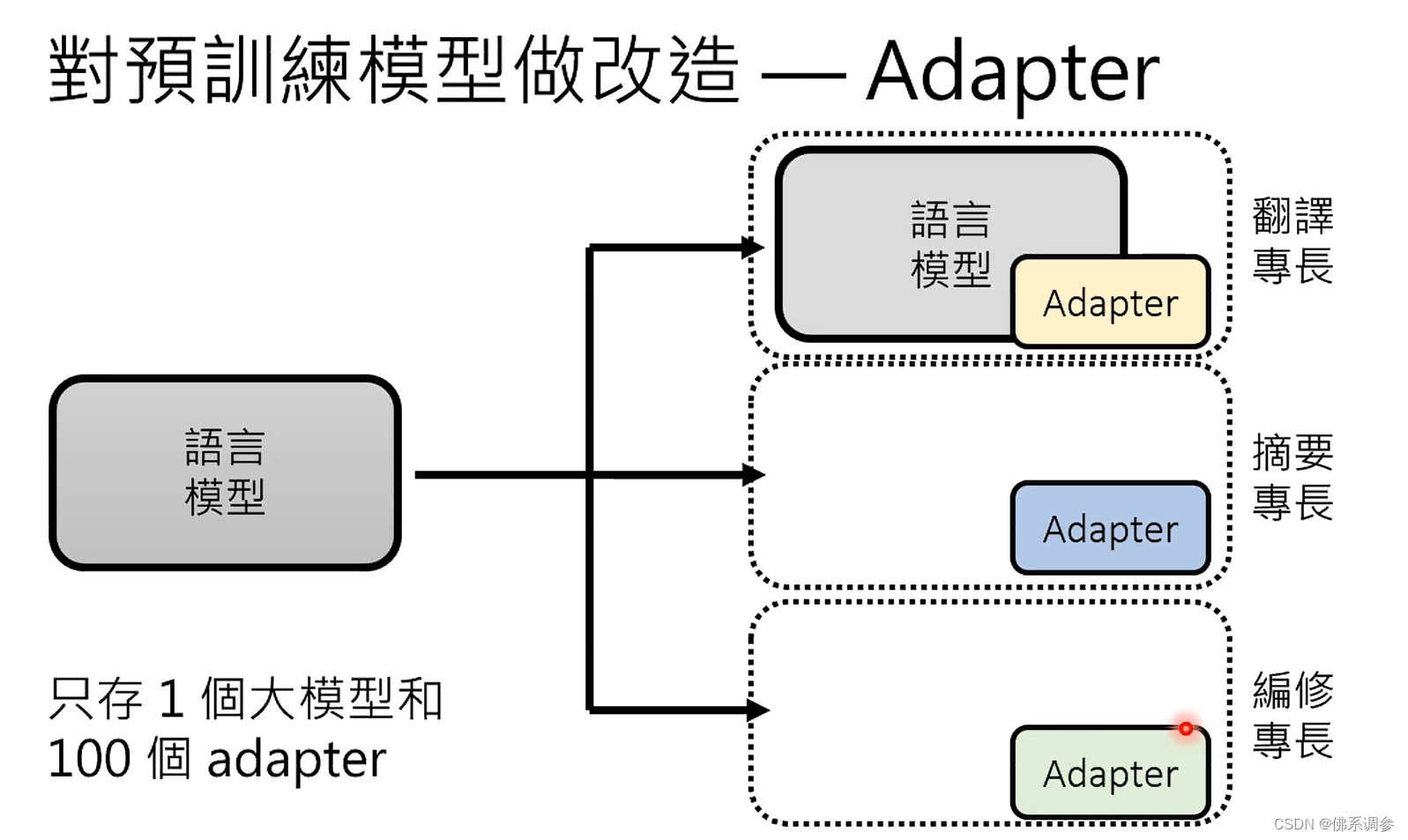
- 另一种方式,采用新增的Adapter,可以插在网络的各种位置,只需要对Adapter参数进行微调,大模型本身其他部分的参数是固定不动的。
各种Adapter 在https:/adapterhub.ml/中可以查看。下图中为对Transformer中可以添加的几种Adapter示例
2. 成为通才的做法

-
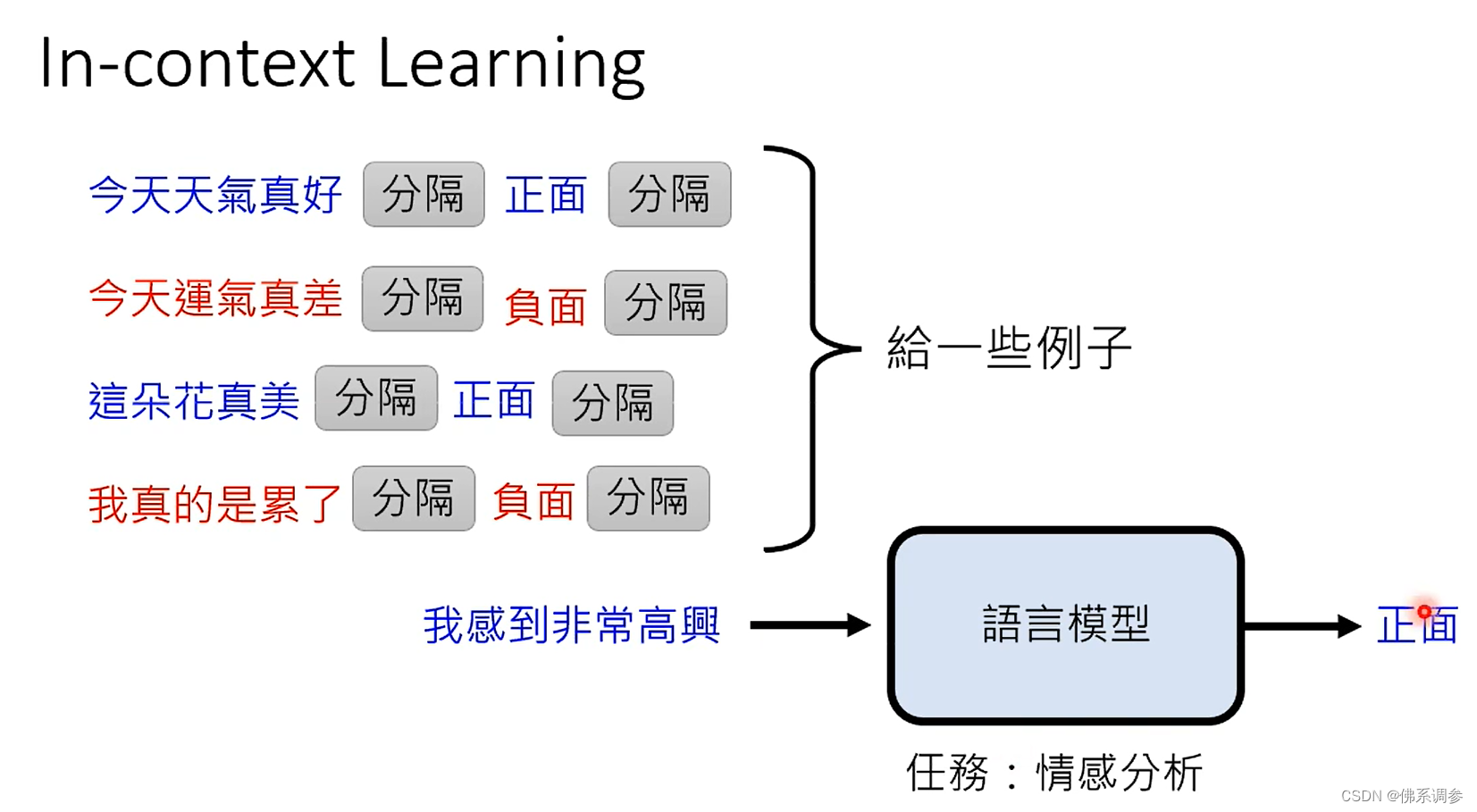
In-context learning(也就是Prompting)
就是在推理时给模型一些示例作为输入,让大模型知道要完成的任务是什么样的
简单来说,就是模型在不更新自身参数的情况下,通过在模型输入中带入新任务的描述与少量的样本,就能让模型”学习”到新任务的特征,并且对新任务中的样本产生不错的预测效果。
注意:并不是在训练时候给出这样的示例,因为并没有根据这些示例对大模型参数进行更新(另一个角度理解没有对大模型参数进行更新:大模型预训练好之后参数不动了,但是要完成的任务很多,且任务是各式各样)
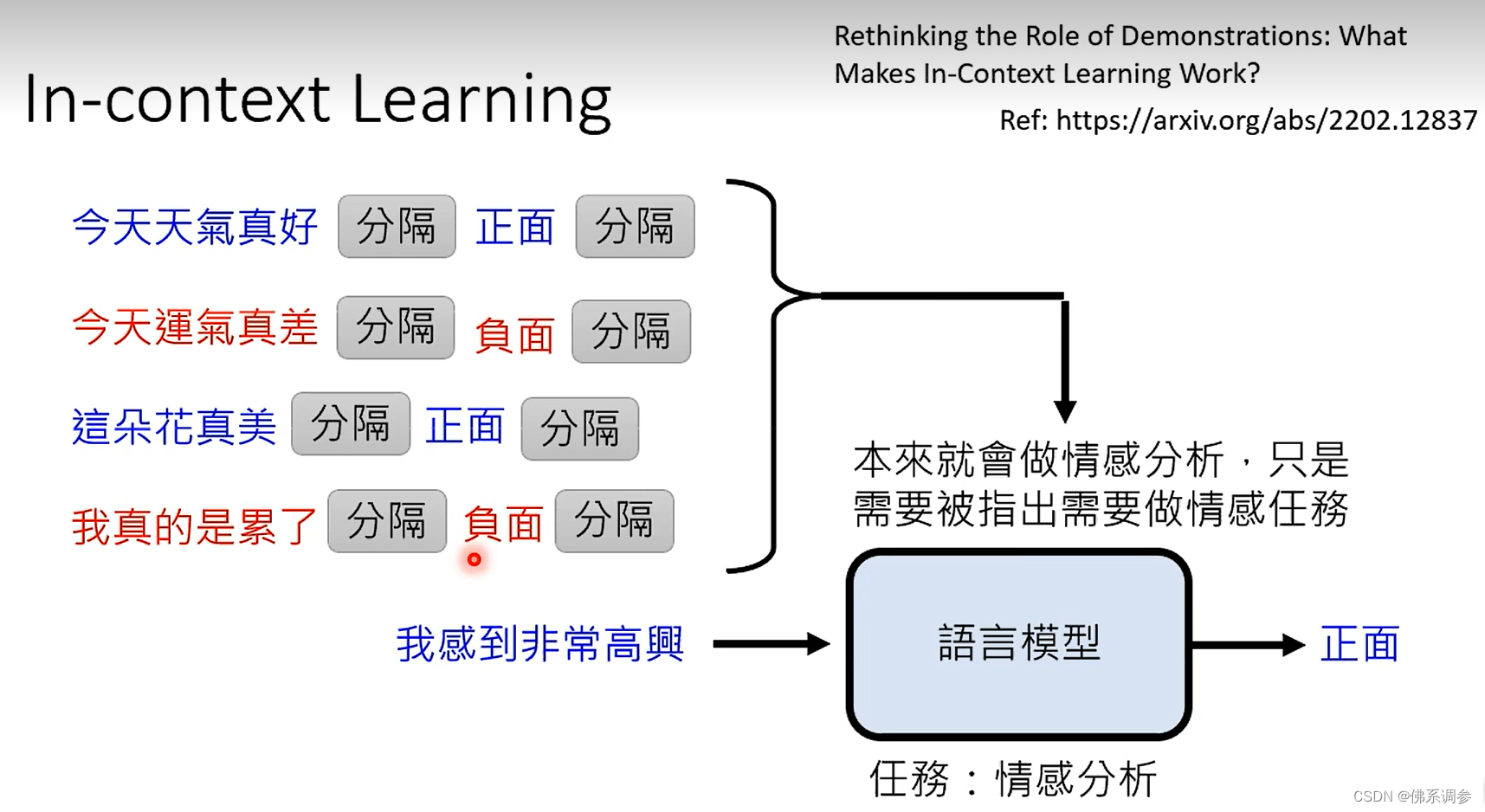
有一篇论文对in-context learning进行了研究
- 对输入示例语句其中的label(正面或者负面)进行了随机,表明输入时即使给的示例的label是错误的,模型的预测性能也没有降低太多。表明Label其实不重要?(但是另外一篇论文研究表明,示例label错误的比例越高,模型性能越低,并且模型参数量越大的话性能降低的越多,这样前面工作的结论可能是因为采用的模型比较小)
- 将输入示例语句其中第一个分隔符之前的语句替换为不同场景/任务的句子,模型性能降低很多,表明示例任务的相关性很重要
- 给出的示例的数量也不是越多越好,越多的话性能反而可能会降低。一般4个或者8个就够了。
- 推论:大模型本来就有做某种任务的能力(比如情感分析),只是需要被指出需要做的任务的种类(比如情感分析),而输入的示例语句就是起到这样的作用(唤起大模型的能力)。
Learning In-context learning
其实也可以做 Learning In-context learning,就是在训练过程中采用In-context learning,做到真正的learning(模型参数进行了更新)

-
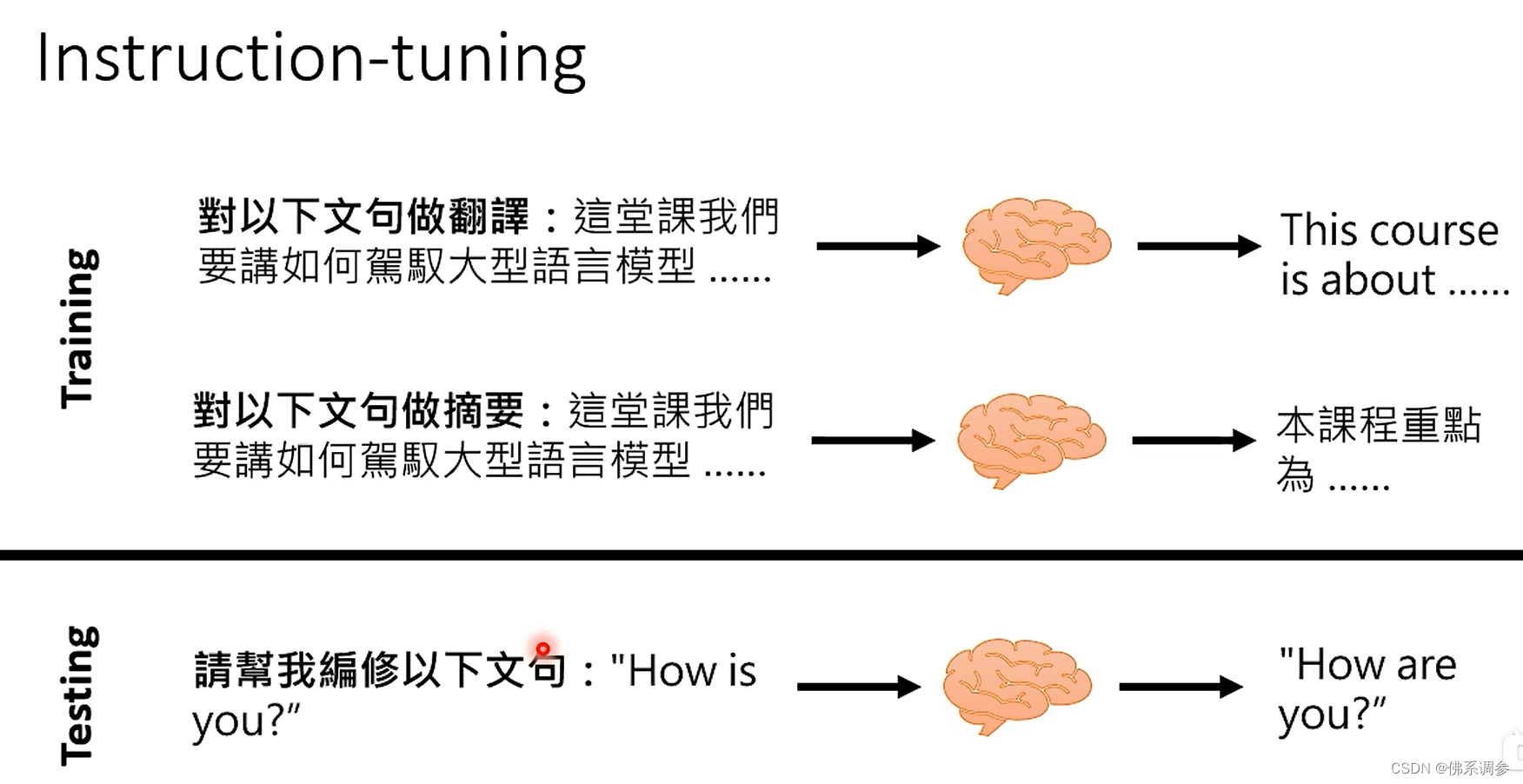
Instruction-tuning(指令微调)
做法:给出问题的描述
它的核心思想是尽可能收集不同类型的自然语言处理任务(包括理解和生成),并使用自然语言设计对应的任务指令,让模型试图理解不同任务的指令与特性,最终通过语言模型生成的方式完成不同任务的训练
注意:在训练和推理过程中都会用到指令微调,因此需要构建指令微调的训练集
-
chain of Thought(CoT)Prompting
思维链prompting
做法:在给模型示例的时候,顺便给出推论的中间过程

zero-shot-CoT
动机:很多时候没有解题的过程,因为解题的过程是人写的
做法:机器在回答之前加上一句 let's think step by step.,这样机器的推理能力就会提升了
