【GNN/深度学习】常用的图数据集(图结构)
文章目录
1. 介绍
近年来,深度学习越来越关注图方向的任务,通过利用图神经网络去挖掘现实中各种可以利用图来表示事物(社交网络,论文引用网络,分子结构)等等,来学习更好的表示,去实现下游任务。
- 图数据是由一些点和一些线构成的,能表示一些实体之间的关系,图中的点就是实体,线就是实体间的关系。如下图,v就是顶点,e是边,u是整张图。attrinbutes(feature)是信息的意思,每个点、每条边、每个图都是有信息的。

2. 图数据集
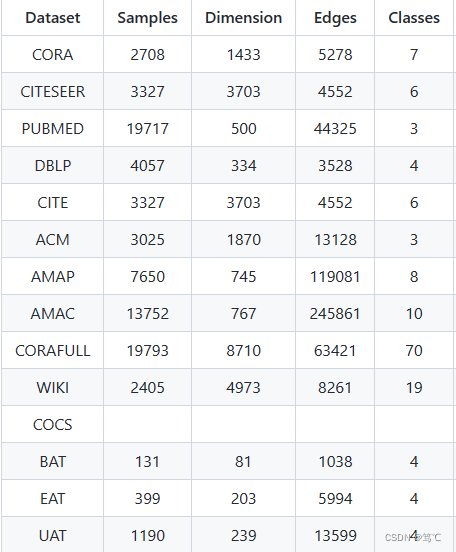
下面我们就来介绍深度学习中常用的图数据集:Cora、Citeseer(Cite)、Pubmed、DBLP、ACM、AMAP、AMAC、Corafull、WIKI、COCS、BAT、EAT、UAT。
每个数据集都包括:
- label(图节点的真实标签)
- feat(图节点的自身属性)
- adj(图结构对应的邻接矩阵)
数据集的下载链接附在后文。
2.1 Cora
Cora数据集包括2708份科学出版物,分为7类。引文网络由5429个链接组成。数据集中的每个出版物都由一个0/1值的词向量描述,表示字典中对应的词是否存在。这本词典由1433个独特的单词组成。
2.2 Citeseer
Citeseer数据集包含3312份科学出版物,分为六类。引文网络由4732个链接组成。数据集中的每个出版物都由一个0/1值的词向量描述,表示字典中对应的词是否存在。这部词典由3703个独特的单词组成。
2.3 Pubmed
Pubmed数据集包括Pubmed数据库中有关糖尿病的19717篇科学论文,分为三类。引文网络由44338个链接组成。数据集中的每个出版物都由字典中的TF/IDF加权词向量描述,该字典由500个唯一的单词组成。
2.4 DBLP
DBLP数据集是来自dblp网站的作者网络。如果是共同作者关系,则两个作者之间有一条边。作者将研究内容分为四个方面:数据库、数据挖掘、机器学习和信息检索。我们根据每个作者提交的会议来标记他们的研究领域。作者特征是由关键字表示的词袋中的元素。
2.5 ACM
这是来自ACM数据集的论文网络。如果两篇论文是同一作者写的,那么两篇论文之间就有一条边。论文特征是关键词的词袋。我们选取在KDD、SIGMOD、SIGCOMM、MobiCOMM上发表的论文,按研究领域分为数据库、无线通信、数据挖掘三类。
2.6 AMAP & AMAC
A-Photo和A-Computers提取自Amazon共购图,其中节点表示产品,边表示两种产品是否经常共购,特征表示用bag-of-words编码的产品评论,标签是预定义的产品类别。
2.7 WIKI
维基百科(WIKI)是由世界各地的志愿者创建和编辑的在线百科全书。该数据集是由整个英文维基百科页面组成的单词共现网络。该数据包含2405个节点,17981条边和19个标签。
2.8 COCS
Coauthor-CS和Coauthor-Physics是基于微软学术图的两个包含合著关系的学术网络。图中的节点表示作者,边表示合著关系。在每个数据集中,作者根据研究领域分别被分为15类和5类,节点特征是论文关键词的词袋表示。
2.9 BAT
数据来自国家民航局(ANAC) 2016年1月至12月。它有131个节点,1038条边(直径为5)。机场活动是由相应年份的降落和起飞总数来衡量的。
2.10 EAT
数据来自欧盟统计局(Eurostat) 2016年1月至11月。它有399个节点,5995条边(直径为5)。机场活动是由相应时期的降落加起飞的总数来衡量的。
2.11 UAT
数据来自美国交通统计局2016年1月至10月。它有1190个节点,13599条边(直径为8)。机场活动是通过相应时期通过机场(到达和离开)的总人数来衡量的。
2.12 Corafull
Corafull数据集包括19793个节点、每个节点含有8710维的表示;并含有63421条边,包含70个类别。
3. 如何读取文件
解压之后,放在项目文件下的dataset下,之后便可以利用如下函数进行读入。
def load_graph_data(dataset_name, show_details=False):
"""
- Param
dataset_name: the name of the dataset
show_details: if show the details of dataset
- Return:
the features, labels and adj
"""
load_path = "dataset/" + dataset_name + "/" + dataset_name
feat = np.load(load_path+"_feat.npy", allow_pickle=True)
label = np.load(load_path+"_label.npy", allow_pickle=True)
adj = np.load(load_path+"_adj.npy", allow_pickle=True)
if show_details:
print("dataset name: ", dataset_name)
print("feature shape: ", feat.shape)
print("label shape: ", label.shape)
print("adj shape: ", adj.shape)
print("undirected edge num: ", int(np.nonzero(adj)[0].shape[0]/2))
print("category num: ", max(label)-min(label)+1)
print("category distribution: ")
for i in range(max(label)+1):
print("label", i, end=":")
print(len(label[np.where(label == i)]))
featur_dim = feat.shape[1]
return feat, label, adj
4. 下载链接
5. 参考
【1】https://github.com/yueliu1999/DCRN