一、PostgreSQL explain介绍
PG的explain工作原理是基于表和索引的统计信息,这些统计信息主要存储在系统表pg_statistic,也可以通过视图pg_stats来查看统计信息,包括表的列,行数,distinct值、null值等。统计信息一般是在vacuum或者analyze的时候进行更新。
下面是一个简单的例子:

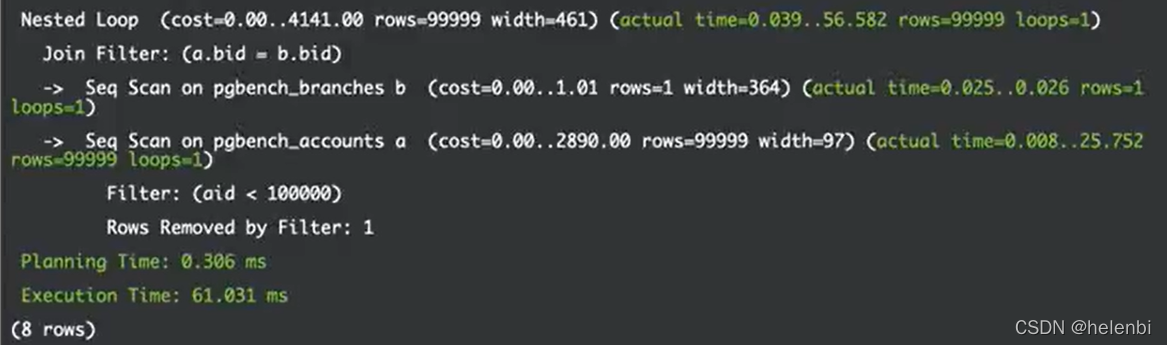
通过explain可以查看SQL查询的计划以及基表的扫描方式、基表的估计行数和估计cost以及多表的连接顺序、连接方式和连接的估计行数和估计cost。上面的例子表a和表b都是使用顺序扫描,估计的行数分别是1和99999,两者通过嵌套循环进行连接,连接后估计行数是99999。
explain的语法结构:
EXPLAIN [ ( option [, ...] ) ] statement
EXPLAIN [ ANALYZE ] [ VERBOSE ] statement
where option can be one of:
ANALYZE [ boolean ]
VERBOSE [ boolean ]
COSTS [ boolean ]
SETTINGS [ boolean ]
BUFFERS [ boolean ]
TIMING [ boolean ]
SUMMARY [ boolean ]
FORMAT { TEXT | XML | JSON | YAML }可以通过使用EXPLAIN的ANALYZE选项来检查优化器估计值的准确性。通过使用ANALYZE选项,EXPLAIN会实际执行该查询,然后显示真实的行计数和在每个计划结点中累计的真实运行时间,还会有一个普通EXPLAIN显示的估计值。
EXPLAIN的BUFFERS选项可以和ANALYZE一起使用来得到运行时shared buffer读写次数, BUFFERS提供的信息帮助我们标识查询的哪些部分是对 I/O 最敏感的。

二、通过explain查找问题
1. 定位比较糟糕的统计信息
通过explain analyze查看估计rows和实际执行的rows的差别,比如下面的例子中,实际执行的行数要远小于估计的行数,因此说明现有的统计信息已经过时,需要使用analyze进行更新以得到更准确的统计值。统计信息更新后,估计行数和实际执行行数比较接近。估计行数的多少决定了表的扫描方式以及多表的连接方式。所以优化器是根据统计信息给出查询计划的。
比如下面的例子中,统计信息更正前使用顺序扫描,更正后使用索引扫描。

2. 定位内存不够用
实际执行中如果内存不够就会使用disk产生IO操作,性能会极大的降低。通过explain analyze可以查看内存是否够用。下面的例子中我们可以看到sort排序使用了2664KB的外存。将work_mem扩大后排序使用内存,提供效率。

3. 定位索引定义不匹配问题
通过explain可以查看索引定义是否和查询条件一致,比如下面的例子中,索引的定义是aid列的substring(filler,1,1),而查询条件是left(filler,1)。

三、查看explain计划比较友好的在线工具
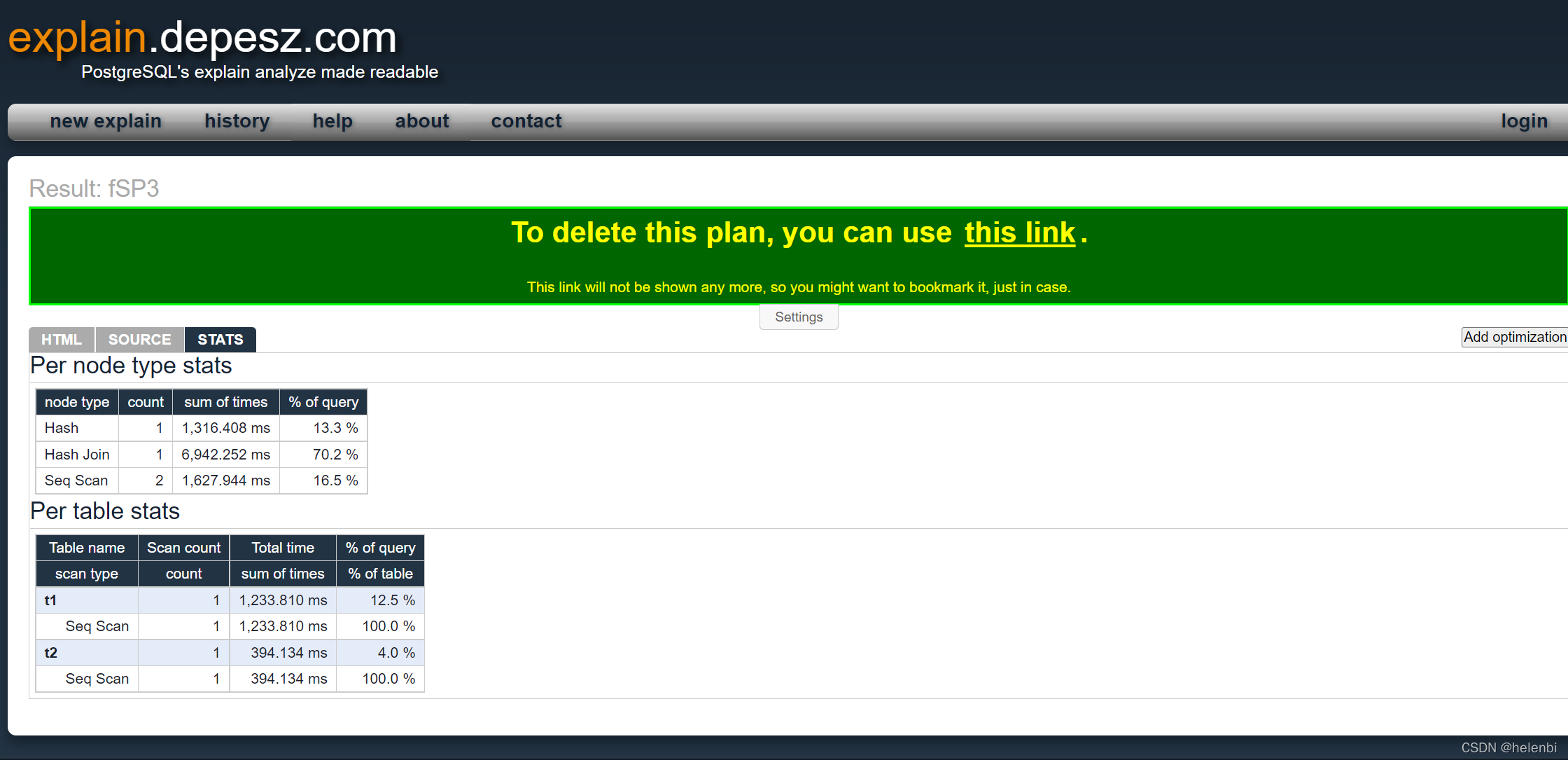
1. explain.depesz.com
比较详细的显示估计和实际执行行数,每个节点的执行时间等。

2. explain.dalibo.com
很方便的查看表的连接方式和连接顺序

