目录
文章目录
- 目录
- Basic Ethernet NIC 设备组成
- SmartNIC 设备组成
-
- 1. Basic NIC
- 2. 添加 DMA Engine 功能
- 3. 添加 Filter Engine 功能
- 4. 添加外部 DRAM 到 Filter Engine
- 5. 添加 L2/L3 Offload Engine 功能
- 6. 添加 Tunnel Offload Engine 功能
- 7. 添加 Deep Buffering 外部存储
- 8. 添加 Flows Engine 功能
- 9. 添加 TCP Offload Engine 功能
- 10. 添加 Security Offload Engine 功能
- 11. 添加 QoS Engine 功能
- 12. 添加一个 Programmable Engine 功能
- 13. 添加一个或多个 ASIC 板载处理器
- DPU 设备组成
Basic Ethernet NIC 设备组成
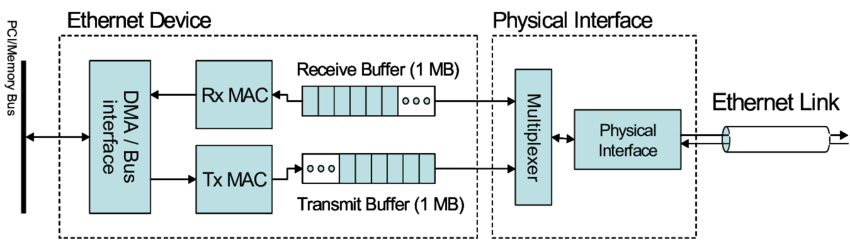
Physical Interface(物理链路连接器)
Physical Interface(物理链路连接器)负责将双绞线网口(电口)或光模块(光口)或连接到网卡上。一个 Physical Interface 通常具有多个 Ethernet Ports。
- 电口:一般为 SFP、QSFP 等,例如 RJ45(Registered Jack,注册的插座)实现了网卡和网线的连接。
- 光口:一般为光纤连接器。
数据中心常见的网卡速率和接口类型:
- 1GbE 千兆网卡:通常使用基于 RJ45 接口的电缆,如 Cat5e、Cat6 等。
- 10GbE 万兆网卡:通常使用基于 SFP+ 接口(10GbE)的光缆。
- 25GbE 网卡:通常使用基于 SFP28 接口(25GbE/10GbE)的光缆。
- 100GbE 网卡:通常使用基于 QSFP28 接口(100GbE/40GbE)的光缆。
PHY(物理层调制解调器)
PHY(Physical Layer Modem,物理层调制解调器),TCP/IP 物理层实现,负责将计算机产生的数字信号转换成可以在物理介质上传输的模拟信号。例如:CSMA/CD、模数转换、编解码、串并转换等。
-
硬件层面表现为 PHY 芯片,定义了数据发送和接收所需要的电与光信号、线路状态、时钟基准、数据编码、连接速度,双工能力等。并向数据链路层提供了 IEEE MII/GigaMII(Media Independed Interfade,介质独立接口)标准接口,用于连接 MAC 和 PHY 传输控制面和数据面的数据。此外还具有 PCS(Physical Coding Sublayer,物理编码)、PMA(Physical Medium Attachment,物理介质附加)、PMD(物理介质相关)、MDIO(Management Data Input/Output)等子层。
-
软件层面执行 CSMA/CD(Carrier Sense Multiple Access/Collision Detection,载波监听多路访问/冲突检测)协议。CSMA/CD 协议具有 “冲突检测“ 和 “载波监听“ 功能,能够检测到网络上是否有数据在传送,如果有数据在传送中就等待,一旦检测到网络空闲,再等待一个随机时间后将送数据出去。
PHY 和 Physical Interface 之间还具有一个 Transformer(变压器),具有提高传输距离、波形修复、电气隔离、抗干扰、防雷等作用。变压器使网卡的芯片组与外部隔离,增强了抗干扰能力,也提供了重要的保护作用。
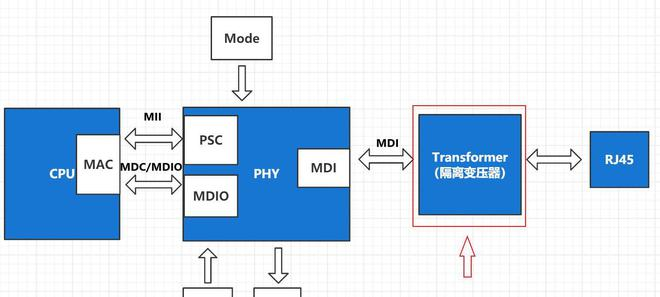
MAC(介质访问控制器)
MAC(Media Access Control,介质访问控制器),TCP/IP 数据链路层实现,负责控制与物理层进行连接的的物理介质。

-
硬件层面表现为一块 MAC 芯片,每个 Ethernet Ports 都具有一个全球唯一的 MAC 地址,就是 MAC 芯片的地址。另外, MAC 还具有对应的 Rx/Tx Queues 用于缓存接收/发送的 Frames。
-
软件层面遵守 IEEE 802.3 Ethernet 协议,完成物理介质 Bit stream 和操作系统 Ethernet Frames 之间的转换,以及完成 Frames CRC 校验。还会控制 PHY 具体执行 CSMA/CD 协议。
先进的 MAC 芯片还会提供数据链路层面的 Packet Filtering 功能。例如:L2 Filtering、VLAN Filtering、Host Filtering 等。
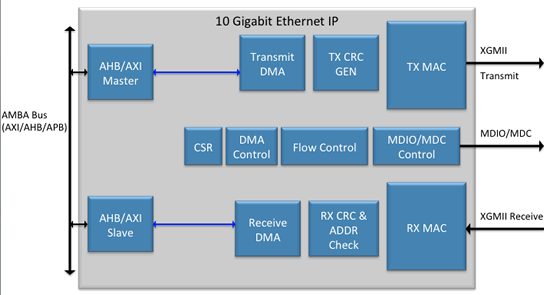
Ethernet Controller(以太网控制器)
Ethernet Controller(以太网控制器)是网卡的核心部件,相当于计算机的主机(CPU + Memory),提供了主要的控制面功能,并通过 Driver(驱动程序)与 Linux 操作系统进行交互。具有以下功能:
- 设备初始化、启动、停止、重启等操作接口。
- DMA Control;
- Flow Control;
- 定时与控制电路(Programmable Logic Array);
- 中断处理;
- 等。
Bus Interface(总线接口)
Bus Interface(总线接口)是网卡和计算机主板之间的连接器,实现 CPU 和 NIC 之间的交互。主要包括 DMA Interface 和 PCIe Interface 这两大类型。
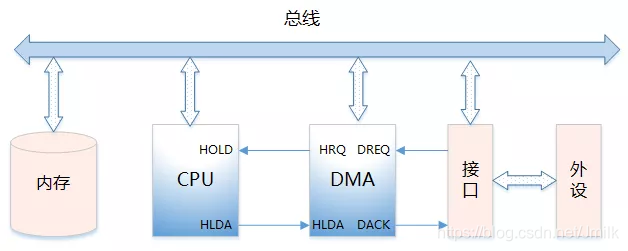
DMA Interface
DMA Controller 的功能:
- 向 CPU 发出 HOLD(保持)信号,提出 Bus(总线)接管请求。
- 当 CPU 发出允许接管信号后,负责对 Bus 的控制,进入 DMA I/O 模式。
- 通过对 Main Memory 进行寻址以及修改地址指针,实现对 Memory 的读写操作。
- 向 CPU 发出 DMA 结束信号,CPU 恢复正常工作模式。
DMA Interface 的信号类型:
- DREQ(外设请求信号):I/O 外设向 DMA Controller 发起请求。
- DACK(DMA 响应信号):DMA Controller 向 I/O 外设的响应信号
- HRQ/HOLD(DMA 请求信号):DMA Controller 向 CPU 发出,要求接管 Bus。
- HLDA(CPU 响应信号):CPU 响应允许 DMA Controller 接管 Bus。
PCIe Interface
PCI-E 外设接口标准历经了 PCI,PCI-X 和 PCI-E 三个阶段,发展了近 30 年的时光。PCI-E 的最终目的是为了替代并统一 PCI、磁盘、网卡、显卡等外设的接口,解决计算机内部数据传输的瓶颈问题。
最新的 PCI-E 标准是 Intel 提出的新一代的外设总线接口,采用了目前业内流行的点对点串行连接。比起 PCI 以及更早期的计算机总线的共享并行架构而言,每个 PCI-E 设备都有自己的专用连接,不需要向整个总线请求带宽,而且可以把数据传输率提高到一个很高的频率,达到 PCI 所不能提供的高带宽。
-
PCI-E(Peripheral Component Interconnect Express,PCI Express,PCI-E,快速外设组件互连)设备

-
PCI-E 设备的接口类型

-
PCI-E 设备的体积类型
- LP(半高)
- FH(全高)
- HL(半长)
- FL(全长)
- SW(单宽)
- DW(双宽)
-
PCI / PCI-E 插槽:PCI-E 支持对 PCI / PCI-X 的软件兼容,但主板上的接口插槽却不兼容,因为 PCI-E 是串行接口,针数会更少,插槽会更短,PCI-E 插槽的长度跟信道的数目有关。

SmartNIC 设备组成
Basic NIC 是一个 PCIe 设备,它仅实现了与以太网的连接,即:实现了 L1-L2 层的逻辑,负责 L2 层数据帧的封装/解封装,以及 L1 层电气信号的相应处理;而由 Host CPU 则负责处理网络协议栈中更高层的逻辑。即:CPU 按照 L3-L7 层的逻辑,负责数据包的封装/解封装等工作;
随着网络速率从 1Gbps、10Gbps、25Gbps、100Gbps 的发展,网络速率需求和 CPU 计算能力的差距持续扩大,激发网络侧专用计算的需求。也伴随着 NIC 片上芯片计算能力的发展,工业内陆续提出了各种各样的 Hardware Offload 方案,将各种 CPU 的 workload 卸载(Offload)到外设扩展卡上进行处理。
最初的方式就是增加 NIC 的 workload 处理能力,例如:现代 NIC 普遍实现了部分 L3-L4 层逻辑的 offload,例如:校验和计算、传输层分片重组等,以此来减轻 Host CPU 的处理负担。甚至有些专用 NIC,例如:RDMA 网卡,还会将整个 L4 层的处理都 offload 到了硬件上。
- TSO(TCP Segmentation Offload)
- GSO(Generic Segmentation Offload)
- LRO(Large Receive Offload)
- GRO (Generic Receive Offload)
随着 NIC 具备了一定计算能力,也称之为智能,所以这类 NIC 被分类为 SmartNIC。
SmartNIC 通过在 NIC 上引入 ASIC、FPGA 或 SoC 芯片来加速(处理)某些特定的流量,从而加强网络的可靠性,降低网络延迟,提升网络性能。
简而言之,SmartNIC 就是通过从 Host CPU 上 Offload(卸载)工作负载到网卡硬件,以此提高 Host CPU 的处理性能。其中的 “工作负载” 不仅仅是 Networking,还可以是 Storage、Security 等等。

以 FPGA 来实现 Smart NIC 举例,了解到底有什么 workload 是可以 Offload 到 Smart NIC 上进行处理的。并且,使用 FPGA 可以根据需要轻松添加、或删除这些功能。
示例 1 到 13 说明了可以添加到 Basic NIC 的处理元素,以创建功能更加强大的 Smart NIC。
1. Basic NIC
采用多个 Ethernet MAC 芯片和一个用于与 Host CPU 连接的 PCIe Interface。Host CPU 必须主动处理所有的 Ethernet Packets。

2. 添加 DMA Engine 功能
添加 DMA Controller 和 DMA Interface,将 NIC Memory 直接映射到 Main Memory ZONE_DMA。Host CPU 可以直接从 Main Memory 读取 Packets,而不再需要从 NIC Memory 中进行 Copy,从而减少了 Host CPU 的工作负载。

3. 添加 Filter Engine 功能
Packets Filter 模块提供 L2 Filtering、VLAN Filtering、Host Filtering 等功能,可以进一步减少了 Host CPU 的工作负载。

4. 添加外部 DRAM 到 Filter Engine
为 Packets Filter 添加用于存储 Filter Rules 的 DRMA 存储器,进一步增强 Packets Filter 的功能和灵活性。

5. 添加 L2/L3 Offload Engine 功能
添加 L2 Switching 和 L3 Routing 功能,卸载数据面转发功能,进一步减少 Host CPU 的工作负载。

6. 添加 Tunnel Offload Engine 功能
将 VxLAN、GRE、MPLSoUDP/GRE 等 Host Tunnel 数据面功能卸载到 SmartNIC,进一步减轻 Host CPU 进行隧道封装/解封装的工作负载。

7. 添加 Deep Buffering 外部存储
添加 Deep Buffer(深度缓冲)专用存储器,用于构建支撑 L2/L3/Tunnel Offloading 的差异化 Buffer Rings。

8. 添加 Flows Engine 功能
针对 vSwitch / vRouter 虚拟网元的 Fast Path 提供 Traffic Flows 模块,另外配置一个 DRAM 存储器,可以处理数百万个 Flow Table Entries。

9. 添加 TCP Offload Engine 功能
卸载全部或部分 TCP 协议功能,减轻 TCP 服务器的 Host CPU 工作负载。

10. 添加 Security Offload Engine 功能
卸载 TLS 此类加密/解密功能,针对相应的 Traffic Flow 可以选择开启/关闭 TLS 加速。

11. 添加 QoS Engine 功能
添加 QoS Engine 功能,卸载 TC 等流量控制模块,可以实现 Multi-Queues 和 QoS 调度功能。

12. 添加一个 Programmable Engine 功能
添加 P4 RMT(Reconfigurable Match Tables,可重配置 Match-Action 表)此类 Programmable Engine,提供一定的可编程 Pipeline 能力。

13. 添加一个或多个 ASIC 板载处理器
添加用于管理面和控制面的 CPU 处理器,提供完整的软件可编程性。

DPU 设备组成
失效的摩尔定律
从前半导体技术高速发展,处理器芯片的性能每 18 个月就能翻倍,算力提升和软件需求处在一个供需平衡的状态。但近几年半导体技术的发展已经逼近物理极限,集成电路越来越复杂,单核芯片的工艺提升目前止步于 3nm。
一个可行的方式是通过多核堆叠来提升算力,但是随着核数的增加,单位算力能耗比也会显著增加,而且堆叠无法实现算力的线性增长。例如:将 128 核堆叠至 256 核,但总算力水平也无法提升到 1.2 倍。计算单元的工艺演进已经逼近基线,每 18 个月翻一番的摩尔定律已经宣告失效。2016 年 3 月 24 日,英特尔宣布放弃 “Tick-Tock” 研发模式,未来研发周期将从两年周期向三年期转变。
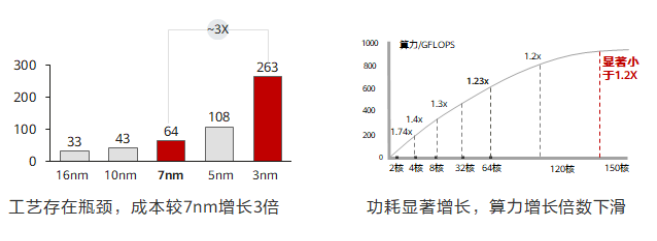
一边是失效的摩尔定律,但另一边却正在发生着 “数据摩尔定律” —— IDC 数据显示,全球数据量在过去 10 年的年均复合增长率接近 50%,并进一步预测每四个月对于算力的需求就会翻一倍。
可见,算力的供需关系已然失衡。
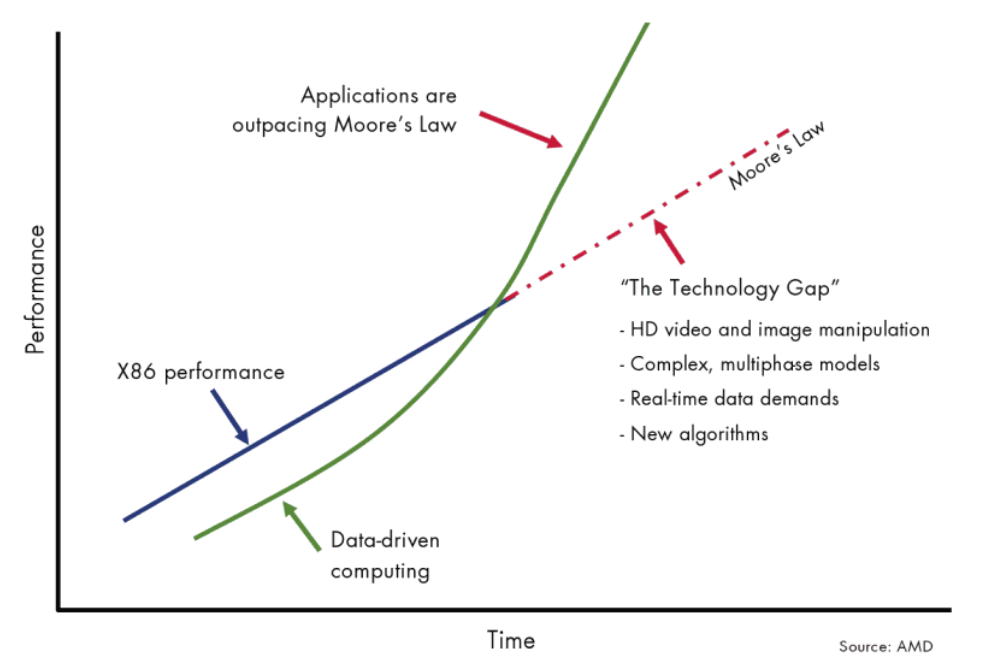
单从网络的角度出发,可以使用 RBP(Ratio of Bandwidth and Performance growth rate,带宽性能增速比)描述这一供需关系。RBP=BW GR/Perf. GR(网络带宽增速 / CPU 性能增速)。
2010 年前,网络的带宽年化增长大约是 30%,到 2015 年增长到 35%,然后在近年达到 45%。相对应的,CPU 的性能增长从 10 年前的 23%,下降到 12%,并在近年直接降低到 3.5%。在这三个时间段内,RBP 指标从 RBP~1 附近(I/O 压力尚未显现出来),上升到 RBP~3,并在近年超过了 RBP~10。CPU 算力增速几乎已经无法应对网络带宽的增速。
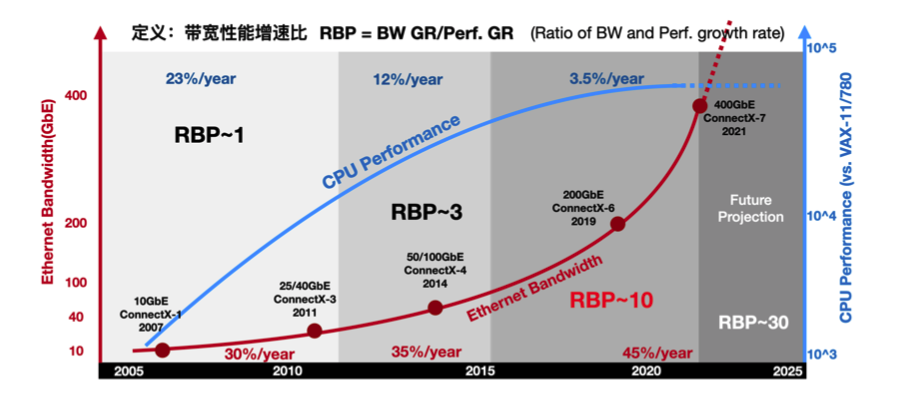
沉重的数据中心税
在 10GbE 和 25GbE 场景中,传统 NIC 的表现让人可以接受,DPDK 等高性能数据面转发技术只是会占用部分 CPU 资源。但在逐渐普及的 40GbE 和 100GbE 场景中,CPU 就会出现阻塞。
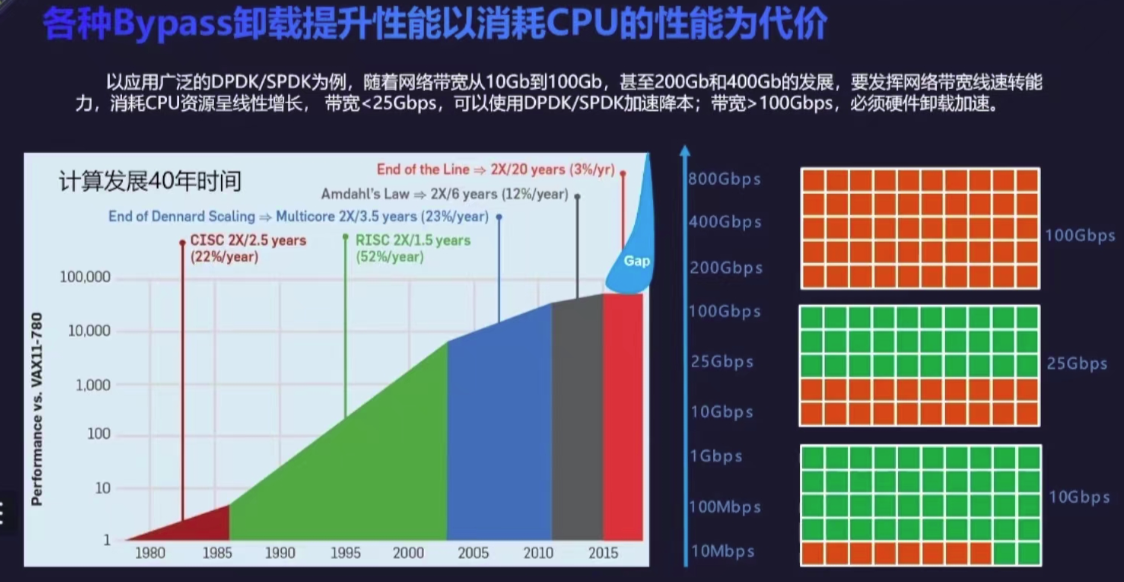
根据 Fungible 和 AWS 的统计,在大型数据中心中,网络流量的处理占到了计算的 30% 左右,即:CPU 30% 的 workload 都是在做流量处理,这个开销被形象的称作数据中心税(Datacenter Tax)。即还未运行业务程序,先接入网络数据就要占去的计算资源。
冯诺依曼内存墙
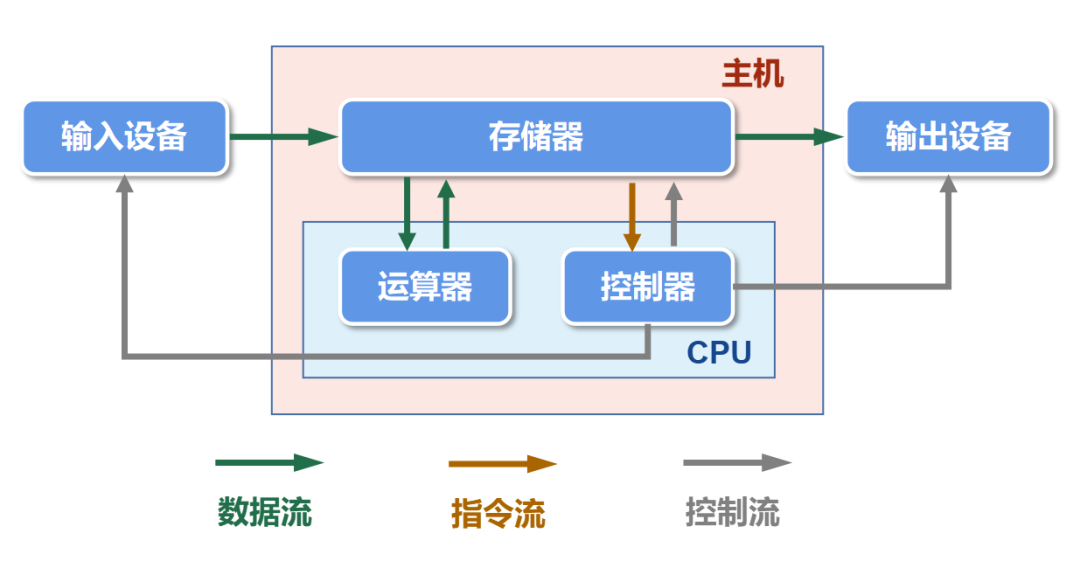
冯·诺依曼体系结构作为一种程序存储计算机,CPU 从 Main Memory 中读取数据,在完成计算后再将数据回写,该模型存在的潜规则是 CPU 计算速度和 Main Memory 传输速度相当。相对的,一旦失衡,那么慢的一方就会成为瓶颈。
而 “内存墙“ 的现实就是 DDR(Main Memory 的容量和 Bus 传输带宽)已经成为了那块短板。这意味着传统计算机体系结构已经无法满足新兴的内存密集型应用程序的需求。例如 AI DL/ML 训练场景,具有高并发、高耦合的特点,不仅有大量的数据参与到整个算法运行的过程中,这些数据之间的耦合性也非常强,因此对 Main Memory 提出了非常高的要求。
为了解决内存墙问题,业界目前有下列几种 “补丁式“ 的解决方法:
- 加大存储带宽:采用高带宽的外部存储,如 HDM2,降低对 DDR 的访问。这种方法虽然看似最简单直接,但问题在于缓存的调度对深度学习的有效性就是一个难点;
- 片上存储:在处理器芯片里集成大存储,抛弃 DDR,比如集成几十兆字节到上百兆的 SRAM。这种方法看上去也比较简单直接,但成本高昂也是显著的劣势。
- 存算一体(In-Memory Computing):在存储器上集成计算单元,现在也是一个比较受关注的方向。
数据 I/O 路径冗长
基于以上等等背景,DSA/DSL(专用的协处理器)和异构计算等领域成为了热门研究方向。针对不同的应用场景,在冯·诺依曼体系中部署专用的协处理器(e.g. GPU、ASIC、FPGA、DSA)来进行加速处理。
但也存在一个直观的问题,CPU 和 Main Memory 以及 Device Memory 之间的数据 I/O 路径冗长,同样会成为计算性能的瓶颈。以 CPU+GPU 异构计算为例,GPU 具有强大的计算能力,能够同时并行工作数百个的内核,但 “CPU+GPU 分离” 架构中存在海量数据无法轻松存储到 GPU Device Memory 中,需要等待显存数据刷新。同时,海量数据在 CPU 和 GPU 等加速器之间来回移动,也加剧了额外的速率消耗。
可见,以 CPU 为中心的体系架构在异构计算场景中,由于内存 IO 路径太长也会成为一种性能瓶颈。
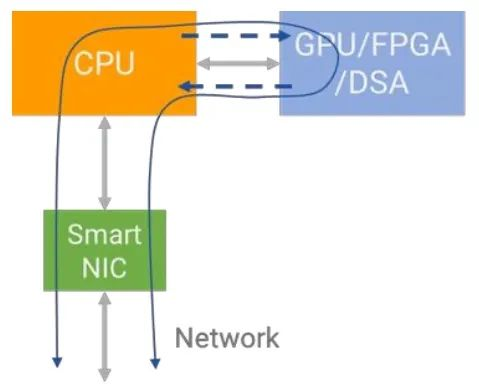
以 DPU 为中心的新型架构
以 DPU 为中心的数据中心,是一种全新的计算机体系结构。在数据中心,将更多 CPU 和 GPU 的 workload offload 到 DPU(Data Processing Unit,数据处理单元)中,使得计算、存储和网络变得更加紧耦合。
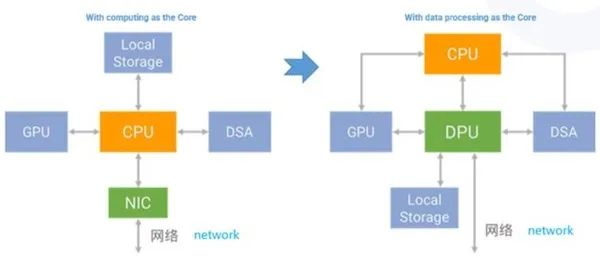
在以往,计算和网络是相互独立的,各自关心自己的事情。正如上文中提到的,随着 CPU 性能瓶颈摩尔定律失效,就需要通过各种方式进行计算加速,但这些手段都使得问题变得非常的复杂。再遵循旧思维以各自的方式去解决各自的问题变得难度都很大。而把计算和网络两者融合起来,用网络的方式解决计算的问题,用计算的方式解决网络的挑战,却是非常高效的新思路。
未来的一个重要趋势是,计算、存储和网络都在不断融合。而 DPU 的核心就是让计算发生在靠近数据产生的地方。
- CPU 负责通用计算。
- GPU 负责加速计算
- DPU 负责数据中心内部的数据传输和处理。
DPU 的抽象架构
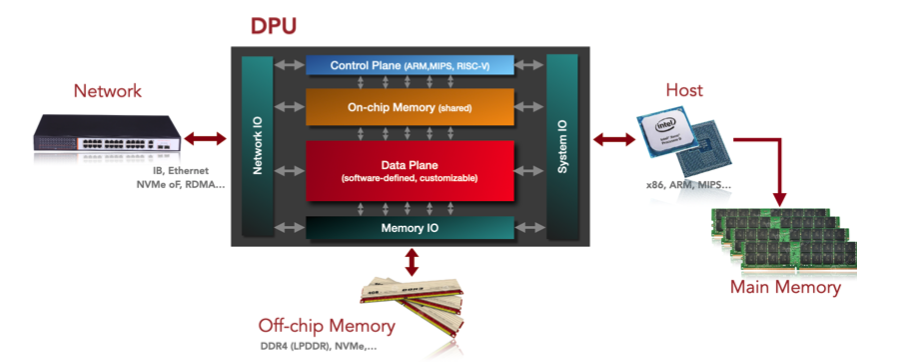
控制平面
由通用处理器(x86 / ARM / MIPS)和片上内存实现,可运行 NIC OS(Linux),主要负责以下工作:
- DPU 设备运行管理
- 安全管理:信任根、安全启动、安全固件升级、基于身份验证的容器和应用生命周期管理等。
- 实时监控:对 DPU 的各个子系统进行监控,包括:数据平面处理单元等。实时观察设备是否可用、设备中流量是否正常,周期性生成报表,记录设备访问日志核配置修改日志。
- DPU 计算任务和资源配置
- 网络功能控制面计算任务。
- 存储功能控制面计算任务。
- 等。
数据平面
由专用处理器(NP / ASIC / FPGA)和 NIC 实现,主要负责以下工作:
- 可编程的数据报文处理功能。
- 协议加速功能。
I/O 子系统
System I/O:由 PCIe 实现,负责 DPU 和其他系统的集成。支持 Endpoint 和 Root Complex 两种实现类型。
- Endpoint System I/O:将 DPU 作为 “从设备” 接入到 Host CPU 处理平台,将数据上传至 CPU 进行处理。
- Root Complex System I/O:将 DPU 作为 “主设备” 接入其他加速处理平台(e.g. FPGA、GPU)或高速外部设备(e.g. SSD),将数据分流至加速平台或外设进行处理。
Network I/O:由 NIC(网络协议处理器单元)实现,与 IP/FC Fabric 互联。
Main Memory I/O:由 DDR 和 HBM 接口实现,与片外内存互联,可作为 Cache 和 Shared Memory。
- DDR 可以提供比较大的存储容量(512GB 以上)。
- HBM 可以提供比较大的存储带宽(500GB/s 以上)。