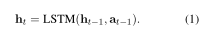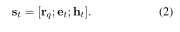近年来,多跳推理得到了广泛的研究,以寻求一种有效且可解释的知识图 (KG) 补全方法。以前的大多数推理方法都是为实体之间有足够路径的密集 KG 设计的,但在那些只包含用于推理的稀疏路径的==稀疏 KG ==上不能很好地工作。一方面,稀疏的 KG 包含的信息较少,这使得模型难以选择正确的路径。另一方面,缺乏指向目标实体的证据路径也使推理过程变得困难。为了解决这些问题,我们提出了一个名为 DacKGRover sparse KGs 的多跳推理模型,通过应用新颖的动态预期和完成策略:(1)预期策略利用基于嵌入的模型的潜在预测,使我们的模型在稀疏上执行更多潜在的路径搜索KGs。 (2) 基于预期信息,补全策略在路径搜索过程中动态添加边作为附加动作,进一步缓解了 KG 的稀疏性问题。从 Freebase、NELL 和 Wikidata 采样的五个数据集的实验结果表明,我们的方法优于最先进的基线。我们的代码和数据集可以从 https://github.com/THU-KEG/DacKGR 获得。
引言
知识图 (KG) 以结构化的方式表示世界知识,并已被证明有助于许多下游 NLP 任务,如查询回答 (Guu et al., 2015)、对话生成 (He et al., 2017) 和机器阅读理解(Yang et al., 2019)。 尽管应用广泛,但许多 KG 仍然面临严重的不完整性(Bordes et al., 2013),这限制了它们对相关下游任务的进一步发展和适应。
图 1:稀疏 KG 上的多跳推理任务示意图。 实体之间缺失的关系(黑色虚线箭头)可以通过推理路径(粗体箭头)从现有的三元组(实心黑色箭头)中推断出来。 然而,在稀疏 KG 中,推理路径中的某些关系缺失(红色虚线箭头),这使得多跳推理变得困难。
现有的多跳推理模型虽然取得了很好的效果,但在稀疏 KG 上仍然存在两个问题:(1)信息不足。 与普通 KG 相比,稀疏 KG 包含的信息较少,这使得智能体难以选择正确的搜索方向。 (2) 缺失路径。 在稀疏的 KG 中,一些实体对之间没有足够的路径作为推理证据,这使得智能体难以进行推理过程。 如图 1 的下部所示,由于缺少关系publish area,因此在Mark Twain和English之间没有证据路径。 从表 1 中我们可以了解到,一些采样的 KG 数据集实际上是稀疏的。 此外,一些特定领域的 KG(例如 WD-singer)知识不丰富,也面临着稀疏的问题。
表 1:一些基准 KG 数据集的统计数据。 #degree 是每个实体的输出度,可以表示稀疏度。
由于大多数现有的多跳推理方法在稀疏 KG 上的性能显着下降,一些初步的努力,例如 CPL (Fu et al., 2019),探索引入额外的文本信息来缓解 KG 的稀疏性。 尽管这些探索取得了可喜的成果,但它们仍然仅限于那些实体具有附加文本信息的特定 KG。 因此,对稀疏 KG 的推理仍然是一个重要但尚未完全解决的问题,并且需要更通用的方法来解决这个问题。
在本文中,我们提出了一个名为 DacKGR 的多跳推理模型,以及解决上述两个问题的两种动态策略:
动态预测利用稀疏知识图谱中的有限信息在推理过程之前预测潜在目标。 与多跳推理模型相比,基于嵌入的模型对稀疏 KG 具有鲁棒性,因为它们依赖于每一个三元组,而不是 KG 中的路径。== 为此,我们的预期策略将预训练的基于嵌入的模型的预测作为预期信息注入到强化学习的状态中==。 这些信息可以指导代理避免漫无目的地搜索路径。
Dynamic Completion临时扩展了KG的一部分,以丰富推理过程中的路径扩展选项。== 在稀疏 KG 中,许多实体只有很少的关系==,这限制了智能体的选择空间。 因此,我们的完成策略在搜索推理路径期间根据当前实体的状态信息动态添加一些额外的关系(例如,图 1 中的红色虚线箭头)。之后,对于当前实体和附加关系 r r r,我们使用预训练的基于嵌入的模型来预测尾部实体 e e e。 然后,附加关系 r r r 和预测的尾部实体 e e e 将形成一个潜在的动作 ( r , e ) (r, e) (r,e) 并被添加到当前实体的动作空间中进行路径扩展。
知识图KG可以表述为 K G = { E , R , T } KG=\{ E,R,T \} KG={
E,R,T},其中 E E E和 R R R分别表示实体集和关系集。 T = { ( e s , r q , e o ) } ⊆ E × R × E T=\{(e_s, r_q, e_o)\} ⊆ E × R × E T={(es,rq,eo)}⊆E×R×E是三元组,其中 e s e_s es和 e o e_o eo分别为头和尾部实体, r q r_q rq 是它们之间的关系。 对于每个 KG,我们可以使用每个实体(节点)的平均出度 D a v g o u t D^{out}_{avg} Davgout 来定义其稀疏度。 具体来说,如果一个 KG 的 D a v g o u t D^{out}_{avg} Davgout 大于某个阈值,我们可以说它是一个密集或正常的 KG,否则,它是一个稀疏的 KG。
给定一个图 KG 和一个三元组查询 ( e s , r q , ? ) (e_s, r_q,?) (es,rq,?),其中 e s e_s es是源实体, r q r_q rq 是查询关系,知识图谱的多跳推理旨在预测 ( e s , r q , ? ) (e_s, r_q,?) (es,rq,?) 的尾部实体 e o e_o eo。 与之前的 KG 嵌入任务不同,多跳推理还给出了一条支持路径 { ( e s , r 1 , e 1 ) , ( e 1 , r 2 , e 2 ) . . . ( e n − 1 , r n , e o ) } \{(e_s, r_1, e_1),(e_1, r_2, e_2) . . .(e_{n−1}, r_n, e_o)\} {(es,r1,e1),(e1,r2,e2)...(en−1,rn,eo)} 在 KG 上作为证据。 如上所述,本文主要关注稀疏 KG 上的多跳推理任务。
方法
在本节中,我们首先介绍用于多跳推理的整个强化学习框架,然后详细介绍我们为稀疏 KG 设计的两种策略,即动态预期和动态完成。 前一种策略引入了基于嵌入的模型的指导信息,以帮助多跳模型在稀疏 KG 上找到正确的方向。 基于这种策略,动态完成策略在推理过程中引入了一些额外的动作来增加路径的数量,这可以缓解 KG 的稀疏性。 继Lin et al(2018)之后,DacKGR 的总体框架如图 2 所示。
图 2:具有动态预期和动态完成策略的政策网络示意图。 e p e_p ep的向量是3.3节介绍的预测信息。 我们使用当前状态动态选择一些关系,并使用预训练的基于嵌入的模型进行链接预测以获得额外的动作空间。 原有的动作空间将与附加的动作空间合并,形成一个新的动作空间。
强化学习框架
近年来,KG 的多跳推理已被制定为 KG 上的马尔可夫决策过程 (MDP)(Das 等人,2018):给定一个三元组查询 ( e s , r q , ? ) (e_s, r_q,?) (es,rq,?),代理需要从 头实体 e s e_s es开始,以最大概率连续选择当前实体对应的边(关系)作为方向,并跳转到下一个实体,直到最大跳数 T T T。继之前的工作(Lin et al,2018)之后,MDP 由以下组件组成:
状态 在多跳推理过程中,agent选择哪条边(关系)不仅取决于查询关系 r q r_q rq和当前实体 e t e_t et,还取决于之前的历史搜索路径。 因此,第 t t t 跳的状态可以定义为 s t = ( r q , e t , h t ) s_t=(r_q,e_t,h_t) st=(rq,et,ht),其中 h t h_t ht 是历史路径的表示。 具体来说,我们使用 LSTM 对历史路径信息进行编码, h t h_t ht 是 LSTM 在第 t t t 步的输出。
动作 对于状态 s t = ( r q , e t , h t ) s_t= (r_q, e_t, h_t) st=(rq,et,ht),如果KG中有一个三元组 ( e t , r n , e n ) (e_t, r_n, e_n) (et,rn,en), ( r n , e n ) (r_n, e_n) (rn,en)就是状态 s t s_t st的一个动作。 状态 s t s_t st 的所有动作组成其动作空间 A t = { ( r , e ) ∣ ( e t , r , e ) ∈ T } A_t=\{(r, e)|(e_t, r, e)∈ T \} At={(r,e)∣(et,r,e)∈T}。 此外,对于每个状态,我们还添加了一个额外的动作 ( r L O O P , e t ) (r_{LOOP},e_t) (rLOOP,et),其中 LOOP 是手动添加的自循环关系。 它允许代理停留在当前实体,这类似于“停止”动作。
转移 如果当前状态为 s t = ( r q , e t , h t ) s_t= (r_q, e_t, h_t) st=(rq,et,ht) 且智能体选择 ( r n , e n ) ∈ A t (r_n, e_n)∈A_t (rn,en)∈At 作为下一个动作,则当前状态 s t s_t st 将转换为 s t + 1 = ( r q , e n , h t + 1 ) s_{t+1}= (r_q, e_n, h_{t+ 1}) st+1=(rq,en,ht+1)。 在本文中,我们将最大跳数限制为 T T T,并且转换将在状态 T = ( r q , e T , h T ) T= (r_q, e_T, h_T) T=(rq,eT,hT) 处结束。
奖励 对于带有尾实体 e o e_o eo 的给定查询 ( e s , r q , ? ) (e_s, r_q,?) (es,rq,?),如果代理最终停在正确的实体上,即 e T = e o e_T=e_o eT=eo,则奖励为 1,否则,奖励是函数 f ( e s , r q , e T ) f(e_s, r_q, e_T) f(es,rq,eT) 给出的介于 0 和 1 之间的值,其中函数 f f f 由预训练的知识图嵌入 (KGE) 模型给出,用于评估三元组的正确性 ( e s , r q , e T ) (e_s, r_q, e_T) (es,rq,eT)。
策略网络
对于上述 MDP ,我们需要一个策略网络来指导代理在不同状态下选择正确的动作。
我们将 KG 中的实体和关系表示为语义空间中的向量,然后步骤 t t t 处的动作 ( r , e ) (r, e) (r,e) 可以表示为 a t = [ r ; e ] a_t= [r;e] at=[r;e],其中 r r r 和 e e e 分别是 r r r 和 e e e 的向量。 正如我们在第 3.1 节中提到的,我们使用 LSTM 来存储历史路径信息。 具体来说,代理选择的每个动作的表示将被送入 LSTM 以生成迄今为止的历史路径信息,
第 t t t 个状态 s t = ( r q , e t , h t ) s_t= (r_q, e_t, h_t) st=(rq,et,ht) 的表示可以表示为