一. 背景介绍
HashMap的底层是通过数组+链表+红黑树的数据结构来存放数据的。我们知道,当新添加元素的key值出现了hash碰撞,就会在同一个bucket中形成链表或者红黑树。当键值对的数量超过阈值时就会扩容,将以前处于同一个链表或者红黑树上的元素打散,在新数组的 bucket 上进行重新分布。
当HashMap在初始化没有指定容量的情况下,首次添加元素时,数组的容量为16;当超出阈值,数组容量为扩容为之前的2倍。
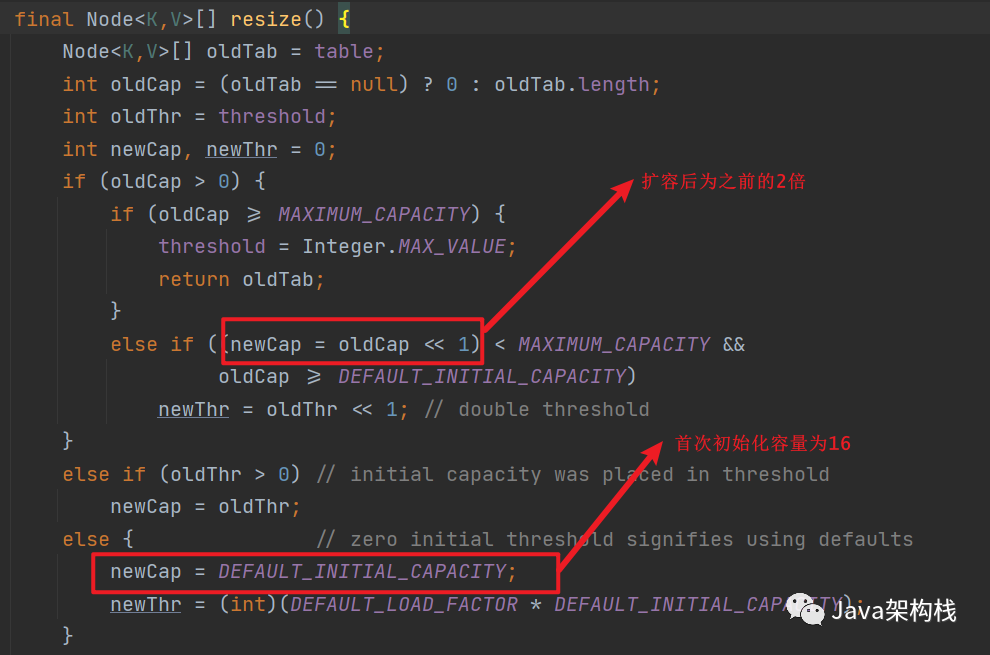
那么问题来了,为什么HashMap会将首次初始化容量设置为16,而后续每次扩容都是之前的2倍?而不是像ArrayList首次为10,后续为1.5倍呢?这可是我们在面试时的一个高频考点哦!
二. 问题解答
2.1 对应源码分析
其实要想回答出上面提出的问题,我们可以从HashMap的源码里找到答案,如下图所示:
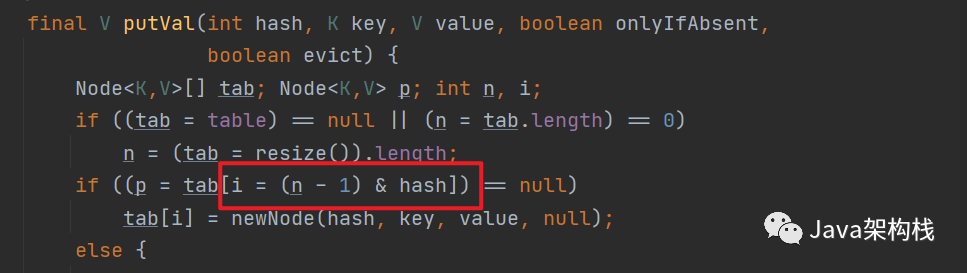
其中 n 为数组的长度,n - 1 为数组的最大索引值。(n - 1)& hash 的意思是将每个元素key的hash值,与最大索引值进行相与操作。然后判断对应的 bucket 位置是否有元素,如果没有元素则在对应的 bucket 位置直接添加;如果有元素,则形成链表或者红黑树。
2.2 深入分析
各位看官,你现在可能对上面的内容还是有点云里雾里,别急,让我们再来看一组数据:
长度最大索引二进制数

当数组初始长度为16的时候,每次扩容都为之前的2倍,那么就保证了每次扩容之后新数组的最大索引值对应的二进制数为全1。根据2.1小节中,图片标识的(n-1)&hash,那么就能保证添加到HashMap中key的hash值与最大索引相与时,能够最大化的分散到HashMap所有的 bucket 中,进而最大化避免出现 hash碰撞而形成链表或者红黑树。
我们再反向地跟各位看官论证一下。假如说 HashMap的初始化长度是10,那么最大索引值为9,而9对应的二进制数是 1001。那么key的hash值与 9相与,结果只可能为 0、1、8、9,那么新增的数据永远只能放到数组索引为 0、1、8、9这四个位置,这就大大增加了出现链表和红黑树转换的概率。
所以初始化为16,每次扩容是之前的2倍,这就大大降低了链表和红黑树转换的概率,自然也就提高了HashMap的性能。
举例说明:
向集合中添加元素时,会使用(n - 1) & hash的计算方法来得出该元素在集合中的位置,其中n是集合的容量,hash是添加的元素进过hash函数计算出来的hash值。
HashMap的容量为什么是2的n次幂,和这个(n - 1) & hash的计算方法有着千丝万缕的关系,符号&是按位与的计算,这是位运算,计算机能直接运算,特别高效,按位与&的计算方法是,只有当对应位置的数据都为1时,运算结果也为1,当HashMap的容量是2的n次幂时,(n-1)的2进制也就是1111111***111这样形式的,这样与添加元素的hash值进行位运算时,能够充分的散列,使得添加的元素均匀分布在HashMap的每个位置上,减少hash碰撞,下面举例进行说明。
当HashMap的容量是16时,它的二进制是10000,(n-1)的二进制是01111,与hash值得计算结果如下
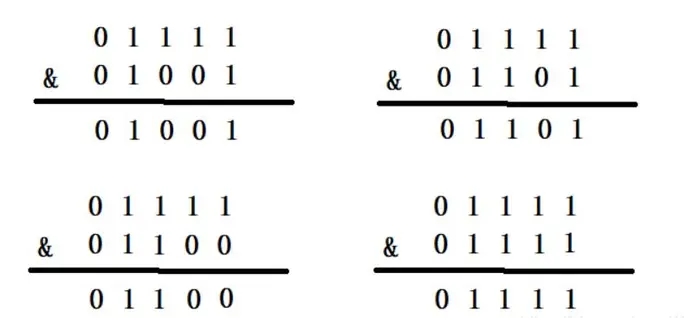
上面四种情况我们可以看出,不同的hash值,和(n-1)进行位运算后,能够得出不同的值,使得添加的元素能够均匀分布在集合中不同的位置上,避免hash碰撞。
下面就来看一下HashMap的容量不是2的n次幂的情况,当容量为10时,二进制为01010,(n-1)的二进制是01001,向里面添加同样的元素,结果为:

可以看出,有三个不同的元素与不同的hashCode经过&运算得出了同样的结果(index),严重的hash碰撞了。
终上所述,HashMap计算添加元素的位置时,使用的位运算,这是特别高效的运算;另外,HashMap的初始容量是2的n次幂,扩容也是2倍的形式进行扩容,是因为容量是2的n次幂,可以使得添加的元素均匀分布在HashMap中的数组上,减少hash碰撞,避免形成链表的结构,使得查询效率降低!