文化袁探索专栏——Activity、Window和View三者间关系
文化袁探索专栏——View三大流程#Measure
文化袁探索专栏——View三大流程#Layout
文化袁探索专栏——消息分发机制
文化袁探索专栏——事件分发机制
文化袁探索专栏——Launcher进程启动流程’VS’APP进程启动流程
文化袁探索专栏——Activity启动流程
文化袁探索专栏——自定义View实现细节
文化袁探索专栏——线程池执行原理|线程复用|线程回收
文化袁探索专栏——React Native启动流程
线程池执行原理?
线程如何复用?
线程又怎么回收?
引入使用线程池-原因
- 降低资源消耗 - 重复利用已创建的线程,降低线程创建和销毁所造成的消耗。
- 提高响应速度 - 当任务到达时,可以不许需要等到线程创建就能立即执行。
- 提高线程可管理性 - 无限创建线程,会消耗系统资源、降低系统稳定性。通过使用线程池可统一对线程进行分配、调优和监控。
线程池执行流程图

线程池执行原理
ThreadPoolExecutor通过execute方法提交一个Runnable任务。
- 当前线程池中运行的线程数量还没有达到 corePoolSize 大小时,线程池会创建一个新线程执行提交的任务,无论之前创建的线程是否处于空闲状态。
- 当前线程池中运行的线程数量已经达到 corePoolSize 大小时,并且等待队列未满,线程池会把任务加入到等待队列中,直到某一个线程空闲了,线程池会根据我们设置的等待队列规则,从队列中取出一个新的任务执行。
- 如果线程数大于 corePoolSize 数量但是还没有达到最大线程数 maximumPoolSize,并且等待队列已满,则线程池会创建新的线程来执行任务。
- 除此之外,则执行拒绝策略,任务结束。
线程如何复用
线程池中线程复用,在Worker.class中的runWorker方法执行中实现。即在不断通过getTask方法从阻塞队列获取任务并执行来体现的。
线程又怎么回收
Worker.class的runWork中,当获取不到任务时候回收线程。通过CAS将线程数减1,对应worker移除线程池。并将线程池状态设置为TERMINATED。

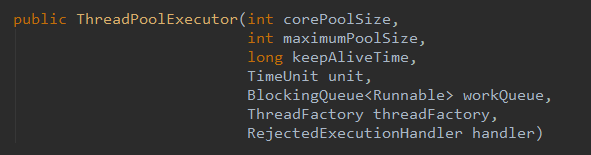
| ThreadPoolExecutor参数 | 参数说明 |
|---|---|
| int corePoolSize | 核心线程数量 |
| int maximumPoolSize | 最多(大)能创建的线程数量 |
| long keepAliveTime | 非核心线程,最大保活时间 |
| TimeUnit unit | keepAliveTime的时间单位 |
| BlockingQueue workQueue | 阻塞(等待)队列,当提交Runnable任务时,若线程池中线程数量threadNum>=corePoolSize&&阻塞队列未满,则把热舞放入等待队列。 |
| ThreadFactory threadFactory | 线程创建工厂,默认使用Executors.defaultThreadFactory() 来创建线程,线程具有相同的NORM_PRIORITY优先级并且是非守护线程。 |
| RejectedExecutionHandler handler | 线程池的饱和拒绝策略,若阻塞队列已满且线程池中线程数量threadNum>=maximumPoolSize,则据徐提交任务,则会采取拒绝策略处理该任务。 |
JUC包下Executors提供的几种线程池
| 代码示范 | 线程解释说明 | 阻塞队列数据结构 |
|---|---|---|
| Executors.newSingleThreadExecutor(); | 单一线程数,同时只有一个线程存活,但线程阻塞队列无界 | LinkedBlockingQueue |
| Executors.newCachedThreadPool(); | 可复用线程池,核心线程数0,最大可创建线程数为Interger.max,线程复用存活时间60s | SynchronousQueue |
| Executors.newFixedThreadPool(int corePoolSize) | 固定线程数量的线程池 | LinkedBlockingQueue |
| Executors.newScheduledThreadPool(int corePoolSize); | 可执行定时任务,延迟任务的线程池 | DelayedWorkQueue |
线程池7个重要方法
| 线程方法 | 代码解释说明 |
|---|---|
| void execute(Runnable run) | 提交任务,交由线程池调度 |
| void shutdown() | 关闭线程池,等待任务执行完成 |
| void shutdownNow() | 关闭线程池,不等待任务执行完成 |
| int getCompletedTaskCount() | 返回线程池中已执行完成的任务数量 |
| int getTaskCount() | 返回线程池找中所有任务的数量 |
| int getCompletedTaskCount() | 返回线程池中已完成的任务数量 |
| int getPoolSize() | 返回线程池中已创建线程数量 |
| int getActiveCount() | 返回当前正在运行的线程数量 |
线程池状态流转

源码| 线程池执行原理
线程池的线程放在了池子workers中,该池子使用的数据结构是HashSet。
当已创建线程数量小于核心线程数,或者已创建线程数量大于核心数且阻塞队列不满且已创建线程数量小于最大可创建线程数量时,就会毫不犹豫创建新的线程。否则会复用已创建线程。
判断当前已创建线程数是否大于核心线程数?小于,则通过addWorker方法将Runable任务包装成Worker添加到任务队列(HashSet)并执行。
/// ThreadPoolExecutor.java
// 获取线程池中已创建的线程数
private static int workerCountOf(int c) {
return c & CAPACITY; }
public void execute(Runnable command) {
... ..
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
// 已创建线程数是否 < 核心线程数
if (addWorker(command, true))
return;
c = ctl.get();
}
... ... .......
}
通过addWorker方法将Runable任务包装成Worker添加到任务队列(HashSet)并执行
扫描二维码关注公众号,回复: 14692308 查看本文章
... addWorker(command, true) ...
private boolean addWorker(Runnable firstTask, boolean core) {
... ......
w = new Worker(firstTask); // 封装成worker
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
... ...
workers.add(w);// 添加到工作线程
... mainLock.unlock() ...
t.start(); // 立即执行
}
}
ThreadPoolExecutor.java的内部类Worker,核心代码实现对提交任务的封装
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable{
...
final Thread thread;
Runnable firstTask;
...
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask; // 将要被封装的任务
// 创建线程-当前worker(runnable),在addWorker中执行t.start时即是在执行Worker这个Runnable
this.thread = getThreadFactory().newThread(this);
}
... .......
public void run() {
// 在addWorker中执行t.start时即回调了这个方法
runWorker(this);
}
..........
}
当t.start执行回调进入到runWorker方法后,调用执行任务方法task.run()
final void runWorker(Worker w) {
...
Runnable task = w.firstTask;
...
while (task != null || (task = getTask()) != null) {
w.lock();
... task.run(); ... // 执行任务
...w.unlock();...
}
}
源码| 线程如何复用
线程复用,复用的是线程池workers中的线程。workers中的线程数量新增,是由addWorker方法促使的。
线程复用的起始在execute方法代码是 if (isRunning© && workQueue.offer(command)) ,目的是添加任务到阻塞队列以待被处理。将任务添加到阻塞队列并不会再创建任何线程,此时仅为复用线程去遍历队列执行任务而已。并且添加任务到队列,可能会触发并激活处于阻塞等待中的线程。核心实现在方法runWorker中,while (task != null || (task = getTask()) != null)
当task非空——(task = getTask()) != null,执行进入getTask方法[线程复用实现在该方法]获取任务,allowCoreThreadTimeOut 默认false。当已创建线程数大于核心线程数,则timed=true。
private Runnable getTask() {
...
for (;;) {
...
int wc = workerCountOf(c);
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
... ...
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
... ...
}
}
从上面源码看,timed=true会执行workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) 。即执行到LinkedBlockingDeque.java的pollFirst方法(当wc<corePoolSize时,无论核心线程是否有空闲都会重新创建新的核心线程执行任务)
public E pollFirst(long timeout, TimeUnit unit)
throws InterruptedException {
...
while ( (x = unlinkFirst()) == null) {
if (nanos <= 0L) // 超过(到了 )等待时间,还未等到signal()。则直接返回null
return null;
// 握住资源进入等待,等待时间是nanos。需要等到notEmpty.signal();才能放行。
nanos = notEmpty.awaitNanos(nanos);
}
...
}
从上面源码看,timed=false会执行workQueue.workQueue.take();即执行到LinkedBlockingDeque.java的takeFirst方法
public E takeFirst(long timeout, TimeUnit unit)
throws InterruptedException {
...
while ( (x = unlinkFirst()) == null)
notEmpty.await(); // 握住资源进入等待,一直阻塞,除非等到notEmpty.signal();才能放行。
}
...
}
基于上面两段代码,notEmpty.signal();什么时候会被触发?从中源码看,需要执行到LinkedBlockingDeque#offerLast方法才可。即执行workQueue.offer(command)成功,向阻塞队列中成功添加了任务后,线程被激活复用并继续处理任务。
大白话:线程复用是实现在getTask方法中。
【1】在当前线程下,若不允许核心线程具有存活时间或者线程池线程数小于最大允许创建线程数,那么通过ReentrantLock对任务加锁,并且当阻塞队列中任务为空时,通过Condition.await()使当前线程一直阻塞。(有任务进入)等到Condition.signal()时,当前线程得到再度复用。
【2】在当前线程下,若允许核心线程具有存活时间或者线程池线程数于最大允许创建线程数,那么通过ReentrantLock对任务加锁,并且当阻塞队列中任务为空时,通过Condition.awaitNanos(nanos)使当前线程在线程存活时间内进行阻塞,(有任务进入)等到Condition.signal()时,当前线程得到再度复用。
源码| 线程又怎么回收
线程回收的实现,在方法processWorkerExit中,移除线程池workers中的线程并设置线程池状态。
private void processWorkerExit(Worker w, boolean completedAbruptly) {
... ...
completedTaskCount += w.completedTasks;
workers.remove(w);
..........
tryTerminate()
...
}
为什么建议使用自定义线程池
ThreadPoolExecutor有多个构造参数,但最终都会调用参数最多的这个构造方法。
通过源码分析可知 ,newFixedThreadPool和newSingleThreadExecutor使用LinkedBlockingQueue任务队列。而LikedBlockingQueue的默认大小是Integer.MAX_VALUE。而newCachedThreadPool中默认定义的线程池大小是Integer.MAX_VALUE。
所以建议自定义线程池的原因就是newFixedThreadPool和newSingleThreadExecutor的任务队列长度为Integer.MAX_VALUE,可能会堆积大量的请求任务,从而导致OOM。newCachedThreadPool允许的创建最大线程数量是Integer.MAX_VALUE,若创建大量的线程,会导致OOM。
线程池怎么合理配置核心线程数
首要分析线程池所处理的程序是CPU密集型,还是IO密集型?
CPU密集型:核心线程数 = CPU核数 + 1
IO密集型:核心线程数 = CPU核数 * 2
// 我在自己项目中是这么直接定义了 !
val cpucount = Runtime.getRuntime().availableProcessors()
val corPoolSize = cpucount + 1
val maxPoolSize = cpucount * 2 + 1