二进制相关知识回顾
1、所有的数据都是以二进制的形式存储在硬盘上。对于一个字节的8位到底是什么类型 计算机是如何分辨的呢? 其实计算机并不负责判断数据类型,数据类型是程序告诉计算机该如何解释内存块.
2、对于字符的存储,先将字符转化成其字符集的码点,(码点就是一个数字),然后把该数字转成2进制存储。所以我们只要记得数字的存储就ok了。字符的码点程序采用无符号处理,即没有符号位,数值型默认都是有符号位的。
1个字节的最高位是符号位所以一个数字能够存储的范围是-128-127
3.原码
正数5: 0000 0101
负数5: 1000 0101
4.反码
正数5: 0000 0101
负数5: 1111 1010
5.补码
正数5: 0000 0101
负数5: 1111 1011(-5在硬盘上的存储方式)
1.可以看到正数的原码 与 其反码补码相同 2.负数的原码最高位为1
3.负数的反码: 符号位不变,其余各位按位取反
4.负数的补码:在其反码的基础上+1
5.负数是以其补码的方式存储在硬盘上的
6.左移操作(<<)
规则: 右边空出的位用0填补 高位左移溢出则舍弃该高位。 计算机中常用补码表示数据: 数据 127,补码和原码一样:0111 1111。 左移一位: 1111 1110 -> 这个补码对应的原码为:1000 0010 对应十进制:-2 左移二位: 1111 1100 -> 这个补码对应的原码为:1000 0100 对应十进制:-4 左移三位: 1111 1000 -> 这个补码对应的原码为:1000 1000 对应十进制:-8 左移四位: 1111 0000 -> 这个补码对应的原码为:1001 0000 对应十进制:-16 左移五位: 1110 0000 -> 这个补码对应的原码为:1010 0000 对应十进制:-32 左移六位: 1100 0000 -> 这个补码对应的原码为:1100 0000 对应十进制:-64 左移七位: 1000 0000 -> 这个补码对应的原码为:1000 0000 对应十进制:-128 左移八位: 0000 0000 -> 这个补码对应的原码为:0000 0000 对应十进制:0 注: 原码到补码的计算方式:取反+1, 补码到原码的计算方式:-1再取反。 数据-1,它的原码为1000 0001,补码为1111 1111 左移一位: 1111 1110 -> 这个补码对应的原码为:1000 0010 对应十进制:-2 左移二位: 1111 1100 -> 这个补码对应的原码为:1000 0100 对应十进制:-4 左移三位: 1111 1000 -> 这个补码对应的原码为:1000 1000 对应十进制:-8 左移四位: 1111 0000 -> 这个补码对应的原码为:1001 0000 对应十进制:-16 左移五位: 1110 0000 -> 这个补码对应的原码为:1010 0000 对应十进制:-32 左移六位: 1100 0000 -> 这个补码对应的原码为:1100 0000 对应十进制:-64 左移七位: 1000 0000 -> 这个补码对应的原码为:1000 0000 对应十进制:-128 左移八位: 0000 0000 -> 这个补码对应的原码为:0000 0000 对应十进制:0 可以看出127和-1的结果完全一样。移位操作与正负数无关,它只是忠实的将所有位进行移动,补0,舍弃操作。
7.右移操作( >>)
规则: 左边空出的位用0或者1填补。正数用0填补,负数用1填补。注:不同的环境填补方式可能不同; 低位右移溢出则舍弃该位。 1、127的补码:0111 1111 右移一位: 0011 1111 -> 原码同补码一样 对应十进制:63 右移二位: 0001 1111 -> 原码同补码一样 对应十进制:31 右移三位: 0000 1111 -> 原码同补码一样 对应十进制:15 右移四位: 0000 0111 -> 原码同补码一样 对应十进制:7 右移五位: 0000 0011 -> 原码同补码一样 对应十进制:3 右移六位: 0000 0001 -> 原码同补码一样 对应十进制:1 右移七位: 0000 0000 -> 原码同补码一样 对应十进制:0 右移八位: 0000 0000 -> 原码同补码一样 对应十进制:0 2、-128的补码:1000 0000 右移一位: 1100 0000 -> 这个补码对应的原码为:1100 0000 对应十进制:-64 右移二位: 1110 0000 -> 这个补码对应的原码为:1010 0000 对应十进制:-32 右移三位: 1111 0000 -> 这个补码对应的原码为:1001 0000 对应十进制:-16 右移四位: 1111 1000 -> 这个补码对应的原码为:1000 1000 对应十进制:-8 右移五位: 1111 1100 -> 这个补码对应的原码为:1000 0100 对应十进制:-4 右移六位: 1111 1110 -> 这个补码对应的原码为:1000 0010 对应十进制:-2 右移七位: 1111 1111 -> 这个补码对应的原码为:1000 0001 对应十进制:-1 右移八位: 1111 1111 -> 这个补码对应的原码为:1000 0001 对应十进制:-1 常见应用 左移相当于*2,只是要注意边界问题。如char a = 65; a<<1 按照*2来算为130;但有符号char的取值范围-128~127,已经越界,多超出了3个数值,所以从-128算起的第三个数值-126才是a<<1的正确结果。 而右移相当于除以2,只是要注意移位比较多的时候结果会趋近去一个非常小的数,如上面结果中的-1,0。

1位:不用,二进制中最高位为1的都是负数,但是我们生成的id一般都使用整数,所以这个最高位固定是0.
41位:用来记录时间戳(毫秒)。
- 41位可以表示241−1个数字,
- 如果只用来表示正整数(计算机中正数包含0),可以表示的数值范围是:0 至 241−1,减1是因为可表示的数值范围是从0开始算的,而不是1。
- 也就是说41位可以表示241−1个毫秒的值,转化成单位年则是(241−1)/(1000∗60∗60∗24∗365)=69年
16位:用来记录工作机器id
- 可以部署在210=1024个节点,包括
5位datacenterId和5位workerId 5位(bit)可以表示的最大正整数是25−1=31,即可以用0、1、2、3、....31这32个数字,来表示不同的datecenterId或workerId
12位:序列号,用来记录同毫秒内产生的不同id
12位(bit)可以表示的最大正整数是212−1=4095,即可以用0、1、2、3、....4094这4095个数字,来表示同一机器同一时间截(毫秒)内产生的4095个ID序号
由于在java中64bit的整数是long类型,所以在java中SnowFlake算法生成的id就是long来存储的。
SnowFlake可以保证:
- 所有生成的id按时间趋势递增
- 整个分布式系统内不会产生重复id(因为有datacenterId和workerId来做区分)
/** Copyright 2010-2012 Twitter, Inc.*/
package com.twitter.service.snowflake
import com.twitter.ostrich.stats.Stats
import com.twitter.service.snowflake.gen._
import java.util.Random
import com.twitter.logging.Logger
/**
* An object that generates IDs.
* This is broken into a separate class in case
* we ever want to support multiple worker threads
* per process
*/
class IdWorker(val workerId: Long, val datacenterId: Long, private val reporter: Reporter, var sequence: Long = 0L)
extends Snowflake.Iface {
private[this] def genCounter(agent: String) = {
Stats.incr("ids_generated")
Stats.incr("ids_generated_%s".format(agent))
}
private[this] val exceptionCounter = Stats.getCounter("exceptions")
private[this] val log = Logger.get
private[this] val rand = new Random
val twepoch = 1288834974657L
private[this] val workerIdBits = 5L
private[this] val datacenterIdBits = 5L
private[this] val maxWorkerId = -1L ^ (-1L << workerIdBits)
private[this] val maxDatacenterId = -1L ^ (-1L << datacenterIdBits)
private[this] val sequenceBits = 12L
private[this] val workerIdShift = sequenceBits
private[this] val datacenterIdShift = sequenceBits + workerIdBits
private[this] val timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits
private[this] val sequenceMask = -1L ^ (-1L << sequenceBits)
private[this] var lastTimestamp = -1L
// sanity check for workerId
if (workerId > maxWorkerId || workerId < 0) {
exceptionCounter.incr(1)
throw new IllegalArgumentException("worker Id can't be greater than %d or less than 0".format(maxWorkerId))
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
exceptionCounter.incr(1)
throw new IllegalArgumentException("datacenter Id can't be greater than %d or less than 0".format(maxDatacenterId))
}
log.info("worker starting. timestamp left shift %d, datacenter id bits %d, worker id bits %d, sequence bits %d, workerid %d",
timestampLeftShift, datacenterIdBits, workerIdBits, sequenceBits, workerId)
def get_id(useragent: String): Long = {
if (!validUseragent(useragent)) {
exceptionCounter.incr(1)
throw new InvalidUserAgentError
}
val id = nextId()
genCounter(useragent)
reporter.report(new AuditLogEntry(id, useragent, rand.nextLong))
id
}
def get_worker_id(): Long = workerId
def get_datacenter_id(): Long = datacenterId
def get_timestamp() = System.currentTimeMillis
protected[snowflake] def nextId(): Long = synchronized {
var timestamp = timeGen()
if (timestamp < lastTimestamp) {
exceptionCounter.incr(1)
log.error("clock is moving backwards. Rejecting requests until %d.", lastTimestamp);
throw new InvalidSystemClock("Clock moved backwards. Refusing to generate id for %d milliseconds".format(
lastTimestamp - timestamp))
}
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp)
}
} else {
sequence = 0
}
lastTimestamp = timestamp
((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence
}
protected def tilNextMillis(lastTimestamp: Long): Long = {
var timestamp = timeGen()
while (timestamp <= lastTimestamp) {
timestamp = timeGen()
}
timestamp
}
protected def timeGen(): Long = System.currentTimeMillis()
val AgentParser = """([a-zA-Z][a-zA-Z\-0-9]*)""".r
def validUseragent(useragent: String): Boolean = useragent match {
case AgentParser(_) => true
case _ => false
}
}
java版:
/**
* Twitter_Snowflake<br>
* SnowFlake的结构如下(每部分用-分开):<br>
* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000 <br>
* 1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0<br>
* 41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截)
* 得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下下面程序IdWorker类的startTime属性)。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69<br>
* 10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId<br>
* 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号<br>
* 加起来刚好64位,为一个Long型。<br>
* SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右。
*/
public class SnowflakeIdWorker {
// ==============================Fields===========================================
/** 开始时间截 (2015-01-01) */
private final long twepoch = 1420041600000L;
/** 机器id所占的位数 */
private final long workerIdBits = 5L;
/** 数据标识id所占的位数 */
private final long datacenterIdBits = 5L;
/** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/** 支持的最大数据标识id,结果是31 */
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/** 序列在id中占的位数 */
private final long sequenceBits = 12L;
/** 机器ID向左移12位 */
private final long workerIdShift = sequenceBits;
/** 数据标识id向左移17位(12+5) */
private final long datacenterIdShift = sequenceBits + workerIdBits;
/** 时间截向左移22位(5+5+12) */
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/** 工作机器ID(0~31) */
private long workerId;
/** 数据中心ID(0~31) */
private long datacenterId;
/** 毫秒内序列(0~4095) */
private long sequence = 0L;
/** 上次生成ID的时间截 */
private long lastTimestamp = -1L;
//==============================Constructors=====================================
/**
* 构造函数
* @param workerId 工作ID (0~31)
* @param datacenterId 数据中心ID (0~31)
*/
public SnowflakeIdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can't be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can't be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
// ==============================Methods==========================================
/**
* 获得下一个ID (该方法是线程安全的)
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
}
//时间戳改变,毫秒内序列重置
else {
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
}
/**
* 阻塞到下一个毫秒,直到获得新的时间戳
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 返回以毫秒为单位的当前时间
* @return 当前时间(毫秒)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
//==============================Test=============================================
/** 测试 */
public static void main(String[] args) {
SnowflakeIdWorker idWorker = new SnowflakeIdWorker(0, 0);
for (int i = 0; i < 1000; i++) {
long id = idWorker.nextId();
System.out.println(Long.toBinaryString(id));
System.out.println(id);
}
}
}
理解:
sequence = (sequence + 1) & sequenceMask;
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
负数的二进制表示
在计算机中,负数的二进制是用补码来表示的。
假设我是用Java中的int类型来存储数字的,
int类型的大小是32个二进制位(bit),即4个字节(byte)。(1 byte = 8 bit)
那么十进制数字3在二进制中的表示应该是这样的:
00000000 00000000 00000000 00000011 // 3的二进制表示,就是原码
那数字-3在二进制中应该如何表示?
我们可以反过来想想,因为-3+3=0,
在二进制运算中把-3的二进制看成未知数x来求解,
求解算式的二进制表示如下:
00000000 00000000 00000000 00000011 //3,原码 + xxxxxxxx xxxxxxxx xxxxxxxx xxxxxxxx //-3,补码 ----------------------------------------------- 00000000 00000000 00000000 00000000
反推x的值,3的二进制加上什么值才使结果变成00000000 00000000 00000000 00000000?:
00000000 00000000 00000000 00000011 //3,原码 + 11111111 11111111 11111111 11111101 //-3,补码 ----------------------------------------------- 1 00000000 00000000 00000000 00000000
反推的思路是3的二进制数从最低位开始逐位加1,使溢出的1不断向高位溢出,直到溢出到第33位。然后由于int类型最多只能保存32个二进制位,所以最高位的1溢出了,剩下的32位就成了(十进制的)0。
补码的意义就是可以拿补码和原码(3的二进制)相加,最终加出一个“溢出的0”
以上是理解的过程,实际中记住公式就很容易算出来:
- 补码 = 反码 + 1
- 补码 = (原码 - 1)再取反码
因此-1的二进制应该这样算:
00000000 00000000 00000000 00000001 //原码:1的二进制 11111111 11111111 11111111 11111110 //取反码:1的二进制的反码 11111111 11111111 11111111 11111111 //加1:-1的二进制表示(补码)
用位运算计算n个bit能表示的最大数值
比如这样一行代码:
private long workerIdBits = 5L;
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
上面代码换成这样看方便一点:long maxWorkerId = -1L ^ (-1L << 5L)
-1 左移 5,得结果a :
11111111 11111111 11111111 11111111 //-1的二进制表示(补码)
11111 11111111 11111111 11111111 11100000 //高位溢出的不要,低位补0
11111111 11111111 11111111 11100000 //结果a
-1 异或 a :
11111111 11111111 11111111 11111111 //-1的二进制表示(补码)
^ 11111111 11111111 11111111 11100000 //两个操作数的位中,相同则为0,不同则为1
---------------------------------------------------------------------------
00000000 00000000 00000000 00011111 //最终结果31
最终结果是31,二进制00000000 00000000 00000000 00011111转十进制可以这么算:
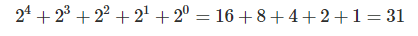
那既然现在知道算出来long maxWorkerId = -1L ^ (-1L << 5L)中的maxWorkerId = 31,有什么含义?为什么要用左移5来算?如果你看过概述部分,请找到这段内容看看:
5位(bit)可以表示的最大正整数是2^5−1=31,即可以用0、1、2、3、....31这32个数字,来表示不同的datecenterId或workerId
-1L ^ (-1L << 5L)结果是31,2^5−1的结果也是31,所以在代码中,-1L ^ (-1L << 5L)的写法是利用位运算计算出5位能表示的最大正整数是多少
用mask防止溢出
有一段有趣的代码:
sequence = (sequence + 1) & sequenceMask;
long seqMask = -1L ^ (-1L << 12L); //计算12位能耐存储的最大正整数,相当于:2^12-1 = 4095
System.out.println("seqMask: "+seqMask);
System.out.println(1L & seqMask);
System.out.println(2L & seqMask);
System.out.println(3L & seqMask);
System.out.println(4L & seqMask);
System.out.println(4095L & seqMask);
System.out.println(4096L & seqMask);
System.out.println(4097L & seqMask);
System.out.println(4098L & seqMask);
/**
seqMask: 4095
1
2
3
4
4095
0
1
2
*/
这段代码通过位与运算保证计算的结果范围始终是 0-4095 !
用位运算汇总结果
还有另外一段诡异的代码:
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
为了弄清楚这段代码,
首先 需要计算一下相关的值:
private long twepoch = 1288834974657L; //起始时间戳,用于用当前时间戳减去这个时间戳,算出偏移量
private long workerIdBits = 5L; //workerId占用的位数:5
private long datacenterIdBits = 5L; //datacenterId占用的位数:5
private long maxWorkerId = -1L ^ (-1L << workerIdBits); // workerId可以使用的最大数值:31
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits); // datacenterId可以使用的最大数值:31
private long sequenceBits = 12L;//序列号占用的位数:12
private long workerIdShift = sequenceBits; // 12
private long datacenterIdShift = sequenceBits + workerIdBits; // 12+5 = 17
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits; // 12+5+5 = 22
private long sequenceMask = -1L ^ (-1L << sequenceBits);//4095
private long lastTimestamp = -1L;
其次 写个测试,把参数都写死,并运行打印信息,方便后面来核对计算结果:
//---------------测试---------------
public static void main(String[] args) {
long timestamp = 1505914988849L;
long twepoch = 1288834974657L;
long datacenterId = 17L;
long workerId = 25L;
long sequence = 0L;
System.out.printf("\ntimestamp: %d \n",timestamp);
System.out.printf("twepoch: %d \n",twepoch);
System.out.printf("datacenterId: %d \n",datacenterId);
System.out.printf("workerId: %d \n",workerId);
System.out.printf("sequence: %d \n",sequence);
System.out.println();
System.out.printf("(timestamp - twepoch): %d \n",(timestamp - twepoch));
System.out.printf("((timestamp - twepoch) << 22L): %d \n",((timestamp - twepoch) << 22L));
System.out.printf("(datacenterId << 17L): %d \n" ,(datacenterId << 17L));
System.out.printf("(workerId << 12L): %d \n",(workerId << 12L));
System.out.printf("sequence: %d \n",sequence);
long result = ((timestamp - twepoch) << 22L) |
(datacenterId << 17L) |
(workerId << 12L) |
sequence;
System.out.println(result);
}
/** 打印信息:
timestamp: 1505914988849
twepoch: 1288834974657
datacenterId: 17
workerId: 25
sequence: 0
(timestamp - twepoch): 217080014192
((timestamp - twepoch) << 22L): 910499571845562368
(datacenterId << 17L): 2228224
(workerId << 12L): 102400
sequence: 0
910499571847892992
*/
代入位移的值得之后,就是这样:
return ((timestamp - 1288834974657) << 22) |
(datacenterId << 17) |
(workerId << 12) |
sequence;
对于尚未知道的值,我们可以先看看概述 中对SnowFlake结构的解释,再代入在合法范围的值(windows系统可以用计算器方便计算这些值的二进制),来了解计算的过程。
当然,由于我的测试代码已经把这些值写死了,那直接用这些值来手工验证计算结果即可:
long timestamp = 1505914988849L;
long twepoch = 1288834974657L;
long datacenterId = 17L;
long workerId = 25L;
long sequence = 0L;
设:timestamp = 1505914988849,twepoch = 1288834974657
1505914988849 - 1288834974657 = 217080014192 (timestamp相对于起始时间的毫秒偏移量),其(a)二进制左移22位计算过程如下:
|<--这里开始左右22位
00000000 00000000 000000|00 00110010 10001010 11111010 00100101 01110000 // a = 217080014192
00001100 10100010 10111110 10001001 01011100 00|000000 00000000 00000000 // a左移22位后的值(la)
|<--这里后面的位补0
设:datacenterId = 17,其(b)二进制左移17位计算过程如下:
|<--这里开始左移17位
00000000 00000000 0|0000000 00000000 00000000 00000000 00000000 00010001 // b = 17
00000000 00000000 00000000 00000000 00000000 0010001|0 00000000 00000000 // b左移17位后的值(lb)
|<--这里后面的位补0
设:workerId = 25,其(c)二进制左移12位计算过程如下:
|<--这里开始左移12位
00000000 0000|0000 00000000 00000000 00000000 00000000 00000000 00011001 // c = 25
00000000 00000000 00000000 00000000 00000000 00000001 1001|0000 00000000 // c左移12位后的值(lc)
|<--这里后面的位补0
设:sequence = 0,其二进制如下: 00000000 00000000 00000000 00000000 00000000 00000000 00000000 00000000 // sequence = 0
现在知道了每个部分左移后的值(la,lb,lc),代码可以简化成下面这样去理解:
return ((timestamp - 1288834974657) << 22) |
(datacenterId << 17) |
(workerId << 12) |
sequence;
-----------------------------
|
|简化
\|/
-----------------------------
return (la) |
(lb) |
(lc) |
sequence;
上面的管道符号|在Java中也是一个位运算符。其含义是:x的第n位和y的第n位 只要有一个是1,则结果的第n位也为1,否则为0,因此,我们对四个数的位或运算如下:
1 | 41 | 5 | 5 | 12
0|0001100 10100010 10111110 10001001 01011100 00|00000|0 0000|0000 00000000 //la
0|0000000 00000000 00000000 00000000 00000000 00|10001|0 0000|0000 00000000 //lb
0|0000000 00000000 00000000 00000000 00000000 00|00000|1 1001|0000 00000000 //lc
or 0|0000000 00000000 00000000 00000000 00000000 00|00000|0 0000|0000 00000000 //sequence
------------------------------------------------------------------------------------------
0|0001100 10100010 10111110 10001001 01011100 00|10001|1 1001|0000 00000000 //结果:910499571847892992
结果计算过程:
1) 从至左列出1出现的下标(从0开始算):
0000 1 1 00 1 0 1 000 1 0 1 0 1 1 1 1 1 0 1 000 1 00 1 0 1 0 1 1 1 0000 1 000 1 1 1 00 1 0000 0000 0000
59 58 55 53 49 47 45 44 43 42 41 39 35 32 30 28 27 26 21 17 16 15 12
2) 各个下标作为2的幂数来计算,并相加:
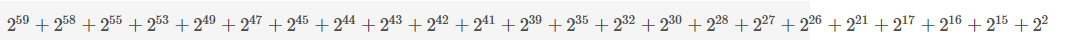
2^59} : 576460752303423488
2^58} : 288230376151711744
2^55} : 36028797018963968
2^53} : 9007199254740992
2^49} : 562949953421312
2^47} : 140737488355328
2^45} : 35184372088832
2^44} : 17592186044416
2^43} : 8796093022208
2^42} : 4398046511104
2^41} : 2199023255552
2^39} : 549755813888
2^35} : 34359738368
2^32} : 4294967296
2^30} : 1073741824
2^28} : 268435456
2^27} : 134217728
2^26} : 67108864
2^21} : 2097152
2^17} : 131072
2^16} : 65536
2^15} : 32768
+ 2^12} : 4096
----------------------------------------
910499571847892992
观察
1 | 41 | 5 | 5 | 12
0|0001100 10100010 10111110 10001001 01011100 00| | | //la
0| |10001| | //lb
0| | |1 1001| //lc
or 0| | | |0000 00000000 //sequence
------------------------------------------------------------------------------------------
0|0001100 10100010 10111110 10001001 01011100 00|10001|1 1001|0000 00000000 //结果:910499571847892992
上面的64位我按1、41、5、5、12的位数截开了,方便观察。
-
纵向观察发现:- 在41位那一段,除了la一行有值,其它行(lb、lc、sequence)都是0,(我爸其它)
- 在左起第一个5位那一段,除了lb一行有值,其它行都是0
- 在左起第二个5位那一段,除了lc一行有值,其它行都是0
- 按照这规律,如果sequence是0以外的其它值,12位那段也会有值的,其它行都是0
-
横向观察发现:- 在la行,由于左移了5+5+12位,5、5、12这三段都补0了,所以la行除了41那段外,其它肯定都是0
- 同理,lb、lc、sequnece行也以此类推
- 正因为左移的操作,使四个不同的值移到了SnowFlake理论上相应的位置,然后四行做
位或运算(只要有1结果就是1),就把4段的二进制数合并成一个二进制数。
结论:
所以,在这段代码中
return ((timestamp - 1288834974657) << 22) |
(datacenterId << 17) |
(workerId << 12) |
sequence;
左移运算是为了将数值移动到对应的段(41、5、5,12那段因为本来就在最右,因此不用左移)。 然后对每个左移后的值(la、lb、lc、sequence)做位或运算,是为了把各个短的数据合并起来,合并成一个二进制数。 最后转换成10进制,就是最终生成的id
扩展
在理解了这个算法之后,其实还有一些扩展的事情可以做:
- 根据自己业务修改每个位段存储的信息。算法是通用的,可以根据自己需求适当调整每段的大小以及存储的信息。
- 解密id,由于id的每段都保存了特定的信息,所以拿到一个id,应该可以尝试反推出原始的每个段的信息。反推出的信息可以帮助我们分析。比如作为订单,可以知道该订单的生成日期,负责处理的数据中心等等。