什么是回归模型?
回归模型提供了一个函数,用于描述一个或多个自变量与响应、因变量或目标变量之间的关系。
例如,身高和体重之间的关系可以通过线性回归模型来描述。回归分析是许多类型预测和确定对目标变量的影响的基础。当您听到有关燃料效率、污染原因或屏幕时间对学习影响的新闻研究时,通常会使用回归模型来支持他们的主张。
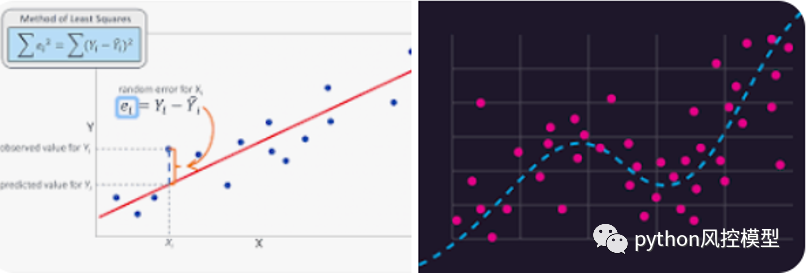
线性回归
线性回归是一种模型,其中输入和输出之间的关系是一条直线。这是最容易概念化甚至在现实世界中观察到的。即使关系不是很线性,我们的大脑也会尝试查看模式并将基本的线性模型附加到该关系。
一个例子可能是对营销活动的响应数量。如果我们发送 1,000 封电子邮件,我们可能会收到 5 封回复。如果可以使用线性回归对这种关系进行建模,那么当我们发送 2,000 封电子邮件时,我们预计会收到 10 个回复。您的图表可能会有所不同,但总体思路是我们将预测变量和目标关联起来,并假设两者之间存在关系。
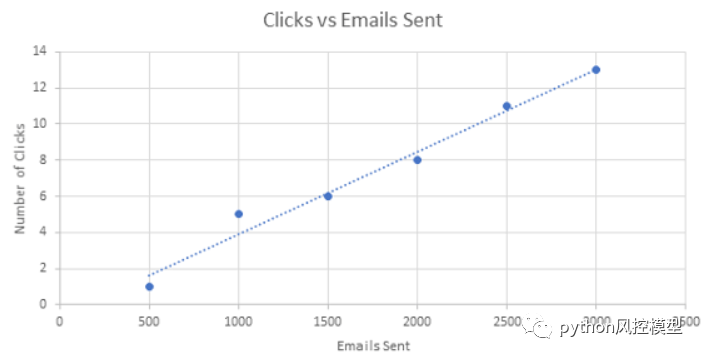
模型案例概述
复杂回归模型包含多个变量,今天我举一个实战案例。该项目是中国移动公司举办模型竞赛项目,奖金百万。
赛题信息
随着社会信用体系建设的深入推进, 社会信用标准建设飞速发展,相关的标准相继发布,包括信用服务标准、信用数据釆集和服务标准、信用修复标准、城市信用标准、行业信用标准等在内的多层次标准体系亟待出台,社会信用标准体系有望快速推进。社会各行业信用服务机构深度参与广告、政务、涉金融、共享单车、旅游、重大投资项目、教育、环保以及社会信用体系建设,社会信用体系建设是个系统工程,通讯运营商作为社会企业中不可缺少的部分同样需要打造企业信用评分体系,助推整个社会的信用体系升级。同时国家也鼓励推进第三方信用服务机构与政府数据交换,以增强政府公共信用信息中心的核心竞争力。
传统的信用评分主要以客户消费能力等少数的维度来衡量,难以全面、客观、及时的反映客户的信用。中国移动作为通信运营商拥有海量、广泛、高质量、高时效的数据,如何基于丰富的大数据对客户进行智能评分是中国移动和新大陆科技集团目前攻关的难题。运营商信用智能评分体系的建立不仅能完善社会信用体系,同时中国移动内部也提供了丰富的应用价值,包括全球通客户服务品质的提升、客户欠费额度的信用控制、根据信用等级享受各类业务优惠等,希望通过本次建模比赛,征集优秀的模型体系,准确评估用户信用分值。
数据清单
train_dataset.zip:训练数据,包含50000行
test_dataset.zip:测试集数据,包含50000行
官网链接:
https://www.datafountain.cn/competitions/337
模型竞赛奖励包括金钱奖励,荣誉证书和大企业工作机会提供
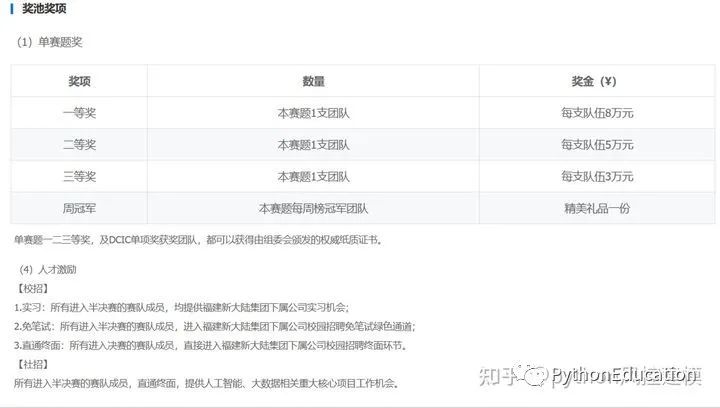
模型竞赛评分方式是MAE,MAE是回归模型的一个评估指标,因此我们需要建立一个回归模型来解决问题。

欢迎各位同学收藏<Python实战金融风控回归模型(附代码)>,学习回归模型知识。
课程对该项目详细讲解,包括回归原理知识,梯度下降,正则化,岭回归,Lasso回归,弹性网络,支持向量回归,xgboost回归,lightgbm回归,Keras sequencial等多种回归模型建模和算法比较


课程有调试好的python脚本,可以直接调用
课程有完整的训练集,测试集,和oot数据,下图是部分数据预览
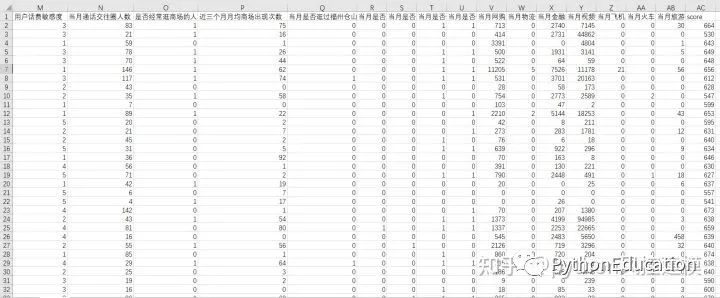
数据说明
本次提供数据主要包含用户几个方面信息:身份特征、消费能力、人脉关系、位置轨迹、应用行为偏好。字段说明如下:
字段列表 字段说明
用户编码 数值 唯一性
用户实名制是否通过核实 1为是0为否
用户年龄 数值
是否大学生客户 1为是0为否
是否黑名单客户 1为是0为否
是否4G不健康客户 1为是0为否
用户网龄(月) 数值
用户最近一次缴费距今时长(月) 数值
缴费用户最近一次缴费金额(元) 数值
用户近6个月平均消费话费(元) 数值
用户账单当月总费用(元) 数值
用户当月账户余额(元) 数值
缴费用户当前是否欠费缴费 1为是0为否
用户话费敏感度 用户话费敏感度一级表示敏感等级最大。根据极值计算法、叶指标权重后得出的结果,根据规则,生成敏感度用户的敏感级别:先将敏感度用户按中间分值按降序进行排序,前5%的用户对应的敏感级别为一级:接下来的15%的用户对应的敏感级别为二级;接下来的15%的用户对应的敏感级别为三级;接下来的25%的用户对应的敏感级别为四级;最后40%的用户对应的敏感度级别为五级。
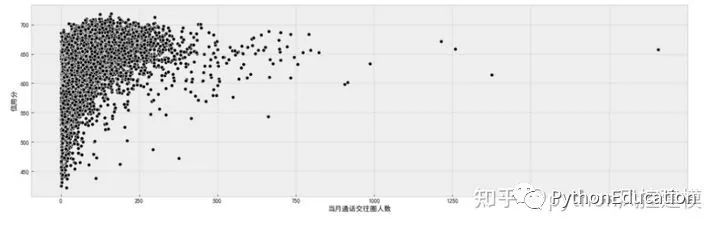
当月通话交往圈人数 数值
是否经常逛商场的人 1为是0为否
近三个月月均商场出现次数 数值
当月是否逛过福州仓山万达 1为是0为否
当月是否到过福州山姆会员店 1为是0为否
当月是否看电影 1为是0为否
当月是否景点游览 1为是0为否
当月是否体育场馆消费 1为是0为否
当月网购类应用使用次数 数值
当月物流快递类应用使用次数 数值
当月金融理财类应用使用总次数 数值
当月视频播放类应用使用次数 数值
当月飞机类应用使用次数 数值
当月火车类应用使用次数 数值
当月旅游资讯类应用使用次数 数值
深度学习sequencial模型建立时,需要安装Keras包。
下面我们用部分python脚本演示变量的可视化,方便描述性统计分析
当月通话交往圈人数数据可视化
#原创公众号pythonEducation
f, ax = plt.subplots(figsize=(20, 6))
sns.scatterplot(data=df_data, x='当月通话交往圈人数', y='信用分', color='k', ax=ax)
plt.show()
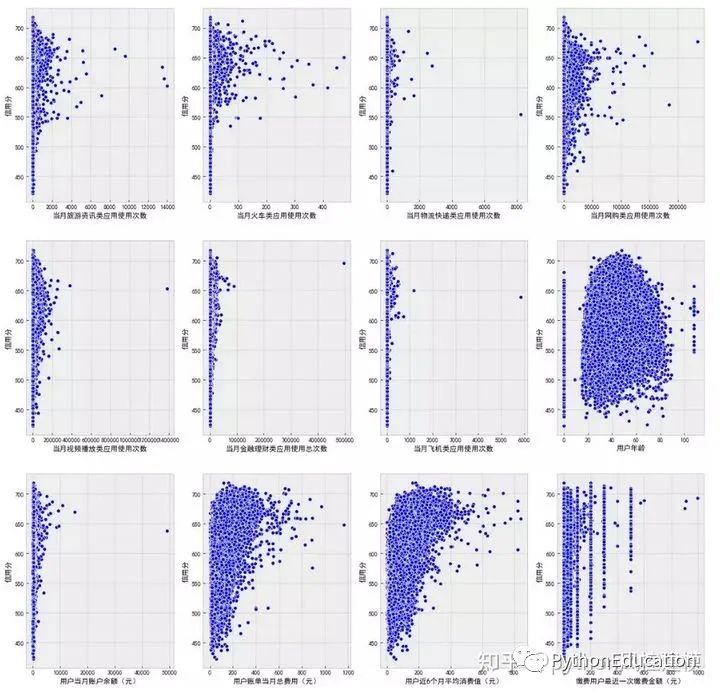
‘当月旅游资讯类应用使用次数’, ‘当月火车类应用使用次数’, ‘当月物流快递类应用使用次数’, ‘当月网购类应用使用次数’, ‘当月视频播放类应用使用次数’, ‘当月金融理财类应用使用总次数’, ‘当月飞机类应用使用次数’, ‘用户年龄’,‘用户当月账户余额(元)’, ‘用户账单当月总费用(元)’, '用户近6个月平均消费值(元)等多个变量散点图绘制。
#原创公众号pythonEducation
name_list = ['当月旅游资讯类应用使用次数', '当月火车类应用使用次数', '当月物流快递类应用使用次数', '当月网购类应用使用次数',
'当月视频播放类应用使用次数', '当月金融理财类应用使用总次数', '当月飞机类应用使用次数', '用户年龄',
'用户当月账户余额(元)', '用户账单当月总费用(元)', '用户近6个月平均消费值(元)', '缴费用户最近一次缴费金额(元)']
f, ax = plt.subplots(3, 4, figsize=(20, 20))
for i,name in enumerate(name_list):
sns.scatterplot(data=df_data, x=name, y='信用分', color='b', ax=ax[i // 4][i % 4])
plt.show()
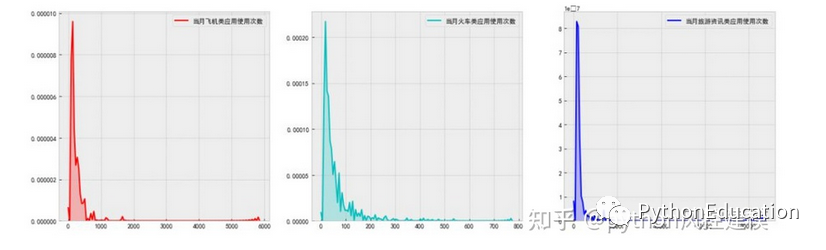
sns.kdeplot()核密度估计图
核密度估计是概率论上用来估计未知的密度函数,属于非参数检验,通过核密度估计图可以比较直观的看出样本数据本身的分布特征
#原创公众号pythonEducation
f, ax = plt.subplots(1, 3, figsize=(10, 8))
sns.kdeplot(data=df['当月飞机类应用使用次数'], color='r', shade=True, ax=ax[0])
sns.kdeplot(data=df['当月火车类应用使用次数'], color='c', shade=True, ax=ax[1])
sns.kdeplot(data=df['当月旅游资讯类应用使用次数'], color='b', shade=True, ax=ax[2])
plt.show()
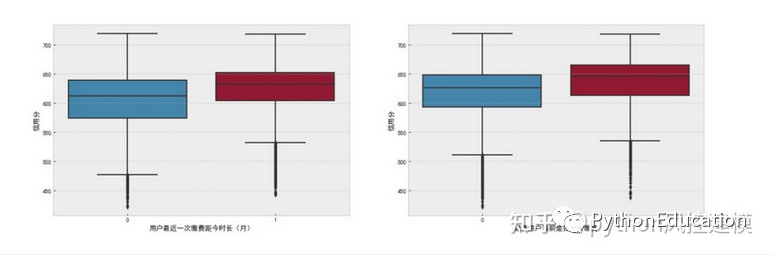
'用户最近一次缴费距今时长(月)'和’缴费用户当前是否欠费缴费’变量箱型图绘制
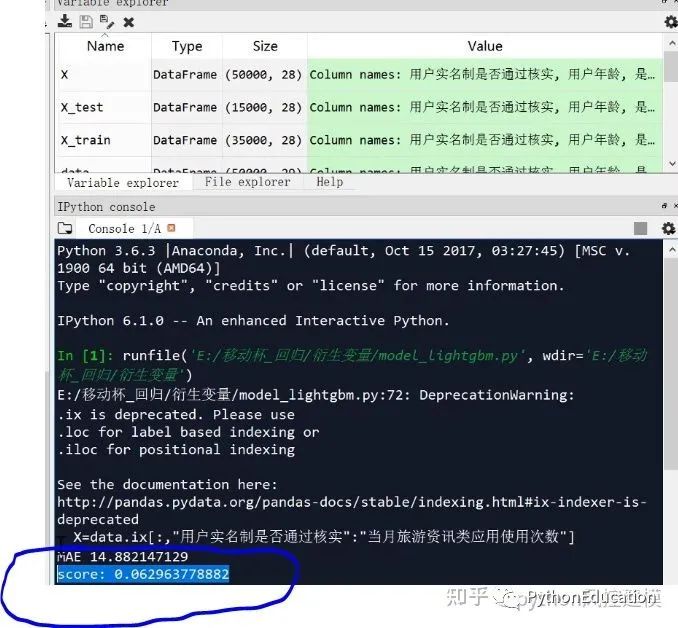
建立好模型后,得到MAE值为14.88,score为0.629,效果非常好。我们通过不断调参,模型可以得到更好性能。
版权声明:文章来自公众号(python风控模型),未经许可,不得抄袭。遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。