这篇文章的全名为
LinkNet: Exploiting Encoder Representations for Efficient Semantic Segmentation
感兴趣的可以自行下载查看
(1)LinkNet介绍
LinkNet采用自编码器的思想,其架构分为两个部分:编码器和解码器。编码器将输入编码到低维空间,解码器从低维空间重建输入。
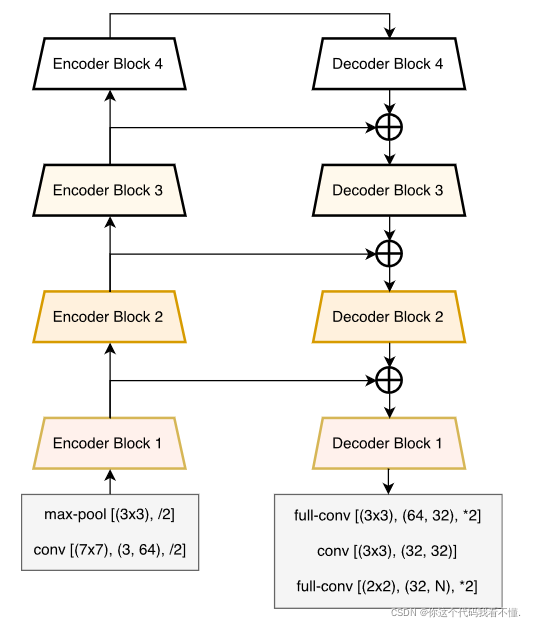
由一个初始块、一个最终块、一个带有四个卷积模块的编码器块以及一个带有四个解卷积模块的解码器块组成。
框架图如下,左边是编码器块,右边是解码器块
(2)反卷积与跳跃连接
反卷积的作用与卷积相反,可以看做是卷积运算的逆过程。效果图可以参考下面

跳跃连接表示为LinkNet网络架构中编码器和解码器之间的平行水平线。跳跃连接有助于网络在编码过程中遗忘某些信息,并在解码时再次查看这些信息。由于网络解码和生成图像所需的信息量相对较低,所以这减少了网络所需的参数量。跳跃连接可以借助不同的操作来实现。使用跳跃连接的另一个优点是,反向梯度流可以轻松地通过相同的连接来实现。LinkNet将隐藏的编码器输出添加到相应的解码器输入中,而另一种语义分割算法 Tiramisu将这两者连接在一起,然后将其发送到下一层。
(3)模型
1、卷积块ConvBlock
卷积块由卷积、batchnorm、ReLU激活函数构成。其中批次归一化可以帮助网络从更稳定的输入分布中学习,从而加快了网络的收敛速度。
2、解卷积块DeconvBlock
是解码器的构建块,与卷积块类似,由转置卷积、BatchNorm和ReLU构成。唯一区别就是将torch.nn.Conv2d换成了torch.nn.ConvTranspose2d。
3、编码器块EncoderBlock
如下图所示,LinkNet中的每个编码器块均由四个卷积块组成。前两个卷积块成为模块一,然后将其与残差输出相加,将输出传递给模块二。

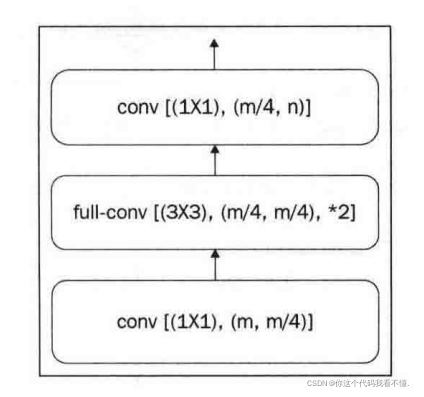
4、解码器块DecoderBlock
比较简单,仅仅是对其进行反卷积操作,示意图如下。
代码实现:
from __future__ import absolute_import
from __future__ import print_function
import os
import numpy as np
from keras.layers import Input, concatenate, Conv2D, MaxPooling2D, Activation, UpSampling2D, BatchNormalization, add
from keras.layers.core import Flatten, Reshape
from keras.models import Model
from keras.regularizers import l2
import keras.backend as K
def _shortcut(input, residual):
"""Adds a shortcut between input and residual block and merges them with "sum"
"""
# Expand channels of shortcut to match residual.
# Stride appropriately to match residual (width, height)
# Should be int if network architecture is correctly configured.
input_shape = K.int_shape(input)
residual_shape = K.int_shape(residual)
stride_width = int(round(input_shape[1] / residual_shape[1]))
stride_height = int(round(input_shape[2] / residual_shape[2]))
equal_channels = input_shape[3] == residual_shape[3]
shortcut = input
# 1 X 1 conv if shape is different. Else identity.
if stride_width > 1 or stride_height > 1 or not equal_channels:
shortcut = Conv2D(filters=residual_shape[3],
kernel_size=(1, 1),
strides=(stride_width, stride_height),
padding="valid",
kernel_initializer="he_normal",
kernel_regularizer=l2(0.0001))(input)
return add([shortcut, residual])
def encoder_block(input_tensor, m, n):
x = BatchNormalization()(input_tensor)
x = Activation('relu')(x)
x = Conv2D(filters=n, kernel_size=(3, 3), strides=(2, 2), padding="same")(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=n, kernel_size=(3, 3), padding="same")(x)
added_1 = _shortcut(input_tensor, x)
x = BatchNormalization()(added_1)
x = Activation('relu')(x)
x = Conv2D(filters=n, kernel_size=(3, 3), padding="same")(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=n, kernel_size=(3, 3), padding="same")(x)
added_2 = _shortcut(added_1, x)
return added_2
def decoder_block(input_tensor, m, n):
x = BatchNormalization()(input_tensor)
x = Activation('relu')(x)
x = Conv2D(filters=int(m/4), kernel_size=(1, 1))(x)
x = UpSampling2D((2, 2))(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=int(m/4), kernel_size=(3, 3), padding='same')(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=n, kernel_size=(1, 1))(x)
return x
def LinkNet(input_shape=(256, 256, 3), classes=1):
inputs = Input(shape=input_shape)
x = BatchNormalization()(inputs)
x = Activation('relu')(x)
x = Conv2D(filters=64, kernel_size=(7, 7), strides=(2, 2))(x)
x = MaxPooling2D((3, 3), strides=(2, 2), padding="same")(x)
encoder_1 = encoder_block(input_tensor=x, m=64, n=64)
encoder_2 = encoder_block(input_tensor=encoder_1, m=64, n=128)
encoder_3 = encoder_block(input_tensor=encoder_2, m=128, n=256)
encoder_4 = encoder_block(input_tensor=encoder_3, m=256, n=512)
decoder_4 = decoder_block(input_tensor=encoder_4, m=512, n=256)
decoder_3_in = add([decoder_4, encoder_3])
decoder_3_in = Activation('relu')(decoder_3_in)
decoder_3 = decoder_block(input_tensor=decoder_3_in, m=256, n=128)
decoder_2_in = add([decoder_3, encoder_2])
decoder_2_in = Activation('relu')(decoder_2_in)
decoder_2 = decoder_block(input_tensor=decoder_2_in, m=128, n=64)
decoder_1_in = add([decoder_2, encoder_1])
decoder_1_in = Activation('relu')(decoder_1_in)
decoder_1 = decoder_block(input_tensor=decoder_1_in, m=64, n=64)
x = UpSampling2D((2, 2))(decoder_1)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=32, kernel_size=(3, 3), padding="same")(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=32, kernel_size=(3, 3), padding="same")(x)
x = UpSampling2D((2, 2))(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
x = Conv2D(filters=classes, kernel_size=(2, 2), padding="same")(x)
model = Model(inputs=inputs, outputs=x)
return model