
InstructPix2Pix: Learning to Follow Image Editing Instructions
图像的语言指令生成。目的是遵循人工指令去编辑图像,即给定输入图像和一个如何编辑它的文本指令,模型尝试遵循这些指令来编辑图像。
这份论文与现有基于文本的图像编辑工作们最大的不同在于,它可以直接以自然文本形式告诉模型要执行什么操作(Instructs),而不是以文本标签、描述或字幕等方式。指令形式的一个好处在于,用户可以用自然的书面文本准确地告诉模型该做什么。指令具有表达性、精确和直观,允许用户轻松地对某些特定对象或视觉属性进行更改。
由于该任务的训练数据难以在大规模上获取,为了获得训练数据,作者结合了两个大型的预训练模型的知识:GPT-3和stable diffusion,以生成一个用于图像编辑任务的大型生成训练数据集。这两个大模型可以分别捕获关于语言和图像的互补知识,以为跨模态的任务创建一些成对的训练数据。
因此InstructPix2Pix的方法包括两部分:生成一个图像编辑数据集,以及基于该数据集训练扩散模型。具体的步骤有如下几步:
- a)首先使用一个微调过的GPT-3来生成指令Instruction和按照指令编辑图像后的描述Edited Caption。如
Input Caption: “photograph of a girl riding a horse” Instruction:
GPT-3生成Instruction:“have her ride a dragon”
GPT-3生成Edited Caption: “photograph of a girl riding a dragon”
在文本域中的操作可以生成大量和多样化的编辑指令集合,同时还能保持图像变化前后的文字对应关系。其中作者是在GPT-3 Davinci上进行微调的,微调使用Human-written的700个Caption–Instruction–Edited Caption数据。得益于GPT-3丰富的知识和概括能力,微调后的模型能够生成创造性而明确的指令和描述。
- b)然后指令实施前后的Input Caption和Edited Caption,由Stable Diffusion和Prompt-to-Prompt一起生成图像对。此处必需使用Prompt-to-Prompt的原因是,文本到图像的转换并不能保证图像的一致性,即使是在非常小的条件变化下,如下图的对比。因此为了保证数据集的稳定性,强调每轮扩散之间要尽可能相似的Prompt-to-Prompt方法十分适合。因此作者通过控制denoising steps p和利用CLIP特征计算相似度过滤来尽可能保证得到的图像对的质量,和可信度。

- c)最终作者们一共创建了超过45万的训练数据集。
- d)最后进行条件扩散模型的训练,以期望其在推理时能泛化到真实图像和用户编写的指令场景中。
虽然InstructPix2Pix是完全在自己生成的数据集上进行训练,即利用GPT-3和stable diffusion生成的数据,但其实仍然现了对任意真实图像和人类编写文本的zero-shot泛化。
paper:https://arxiv.org/abs/2211.09800
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
如题是Grounding Language任务,即按照人类口头指令执行现实世界的任务。论文motivation在于,使用大语言模型来理解口头指令可以编码关于世界的丰富语义知识,这些知识对于机器人能够执行高水平的指令可能非常有用。然而,语言模型的一个显著弱点是它们缺乏现实世界的经验,这使得很难利用它们来进行具象决策。
如下图所示,对于“我把饮料洒了出来,你能帮忙吗?” ,缺乏现实经验的语言模型可能会给出不现实的建议,如如果现场没有吸尘器等物品,机器人是无法帮忙清除饮料的。因此,相结合之下,机器人可以作为语言模型的“手和眼睛”,而语言模型则提供关于任务的高级语义知识,从而将低级别技能与大型语言模型结合起来。
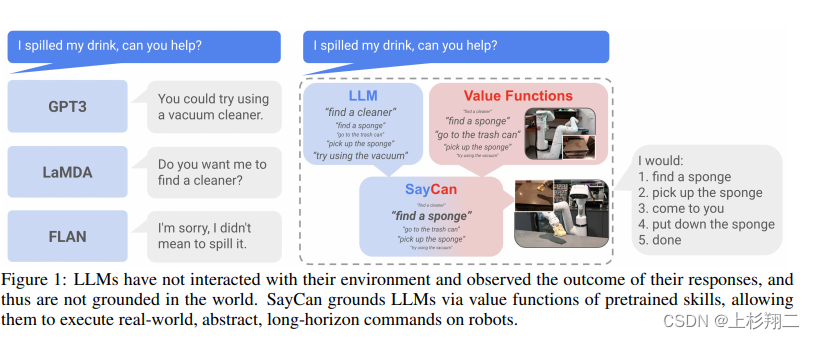
本文主要提出了一种将语言模型转化为机器指令的方法,如上图右侧,大规模语言模型的能力可以帮助分解语义从而得到足够的可能,然后通过强化学习训练一个价值函数来判断可能的价值,最终指导机器人去找到海绵、拿起海绵、找到你、放下海绵、结束。具体的模型结构如下图所示,
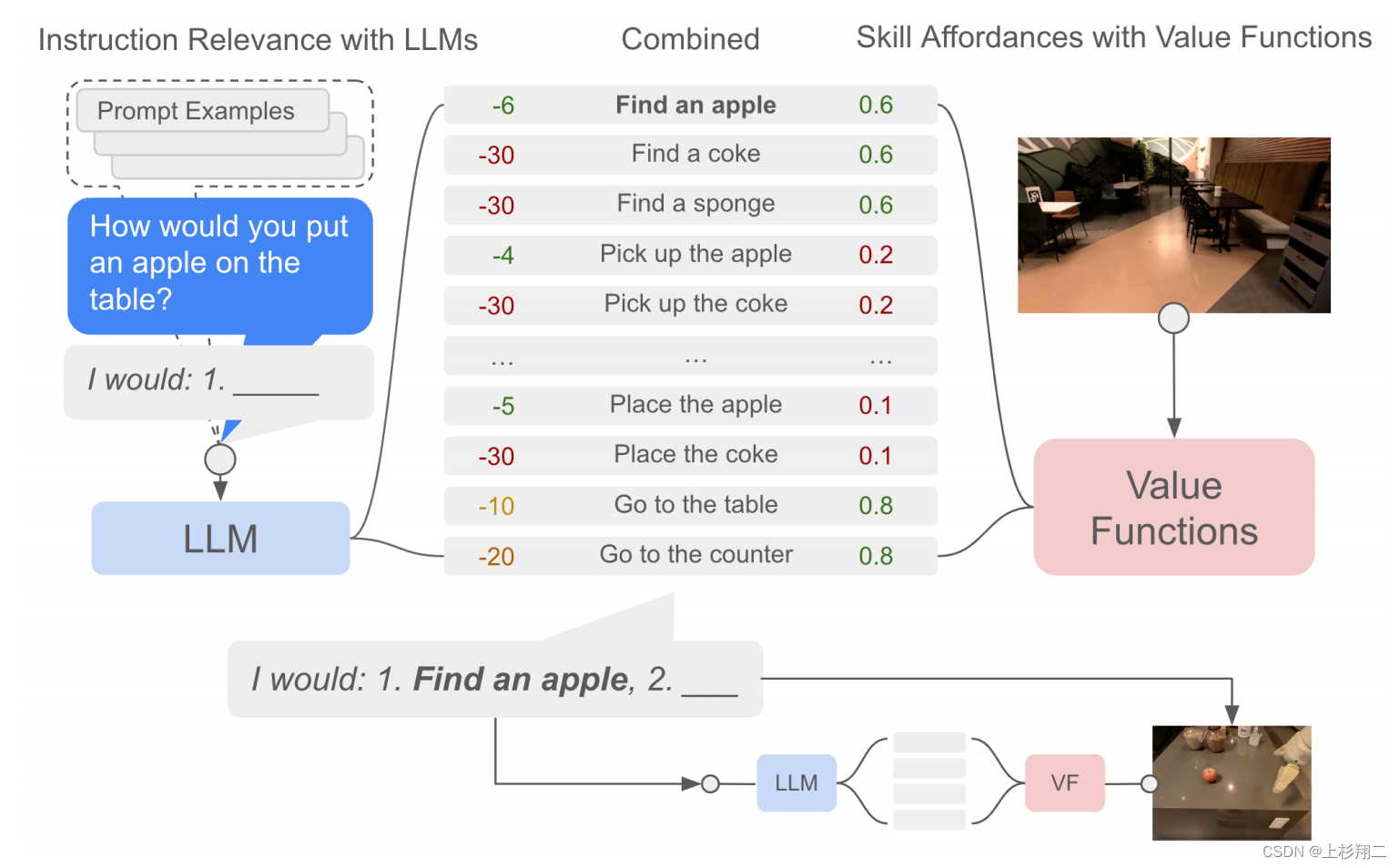
给定一个高级指令,SayCan结合了来自LLM的概率(一个技能对指令有用的概率)和来自一个值函数的概率(为的概率 成功地执行上述技能)来选择要执行的技能。
- LLM。先把指令变成Prompt形式,再利用LLM把指令分解成多个动作,如拿起或放下苹果。
- VF。通过训练好的价值函数,联合LLM给出动作的概率分布,并使机器人执行概率最大的动作,如找到苹果。
- 重复。执行完第一个动作之后,再拼接成新的prompt以生成第二个动作。
code:https://github.com/google-research/google-research/tree/master/saycan
paper:https://arxiv.org/pdf/2204.01691
demo:https://sites.research.google/palm-saycan