Redis是目前最流行、最快的Key-Value数据库,其优异的性能主要源于以下几个方面:
- Redis是基于内存的数据库
- Redis采用了IO多路复用,只有一个线程处理网络请求,可以高效处理高并发场景
- 良好的数据结构的设计,Redis中对列表、字典、队列、栈等数据结构做了非常高效的设计,实现对数据的快速增删改查。
这个系列的文章将深入Redis的源码,分析Redis中的各种数据结构的设计。那么我们首先从最简单的数据结构——字符串开始。
一. 简单动态字符串(SDS)
C语言中并没有直接支持字符串这种数据类型,但可以用一个char数组表示一个字符串,数组的末尾用一个结束符 '\0' 表示字符串的结束。例如
char str[] = "hello";实际上str中保存的是
['h','e','l','l','o','\0']出于以下几个方面的性能原因,Redis中没有直接使用这种方式作为字符串。
- 获取字符串长度的函数strlen(str)是O(N)复杂度,他需要从字符串开头一直遍历,直到碰到结束符 '\0'
- 如果字符串中本身就有 '\0' 字符,字符串就会被截断
- 字符串不支持扩容,如果频繁地对字符串进行修改,则需要频繁地分配内存,效率低下。
因此Redis没有使用C中的字符串,而是做了如下结构的重新设计,称为简单动态字符串(SDS)
struct sds{
int len; //buf中已使用的字节数
int alloc; //buf的总长度
char buf[]; //数据空间
}sds有以下特点:
- 保存了buf数组中已使用的字节数和剩余字节数,可以以O(1)复杂度获取字符串长度,并且长度统计变量len使得对 '\0' 字符是支持的
- 字符串内容保存在柔性数据buf中,buf地址和结构体是连续的,对字符串的访问更快。sds对外暴露的是buf的指针,不是指向结构体的指针,因此可以兼容C对字符串操作的各种函数,并且对buf的地址进行偏移可以很方便地获取len和alloc变量
- 新创建一个sds时会对buf数组预分配一些额外的空间,而通过alloc和len变量可以知道buf数组还剩余多少可用的空间,因此对字符串进行修改时可以很方便地知道是否需要扩容。
考虑这样一种情况,如果字符串长度为1,那么sds需要占几个字节?4(int len)+4(int alloc)+1(char buf[])=9,为了存储一个字符,需要占用9个字节,这显然是不合理的,因此Redis设计了5种不同类型的sds,他们的len和alloc变量占用不同长度的字节,因此可以表示的字符串的最大长度不同,然后结构体中用一个flags来标记这是哪种类型的sds,5种不同的类型需要3bit来存储,即使用char来存储flags,还是会浪费5个bit,因此长度最小的sds(即sdshdr5)可以用一个char变量来同时保存类型和长度,如下所示:
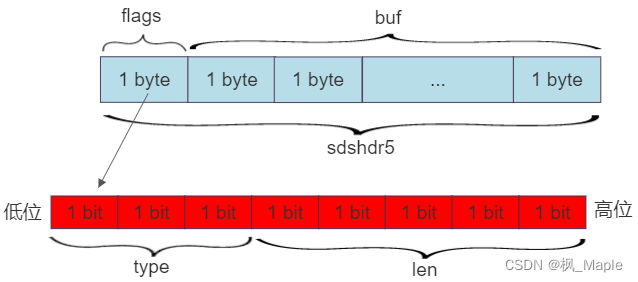
sdshdr5的len为5bit,因此sdshdr5最多只能表示2^5-1=31个字节长度的字符串,并且sdshdr5没有保存alloc变量,他的buf数组长度是固定的,因此是不会对buf进行预分配的,字符串长度是多少,buf的长度就是多少。再以sdshdr16的结构为例,sdshdr16的len和alloc变量都占两个字节,因此最多可以存储2^16-1=65535 byte长度的字符串,而flags不需要再保存len信息,因此只用到前3个bit保存类型信息,后5个bit闲置未使用,如图所示:
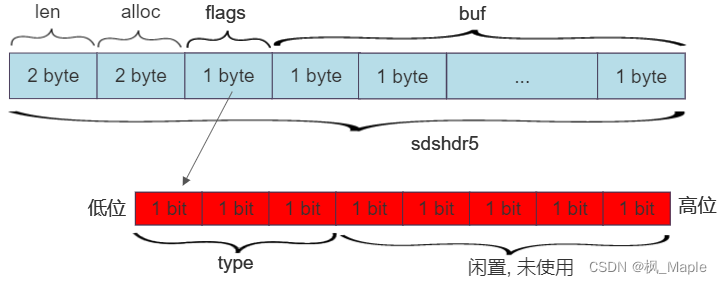
此外,需要注意的是结构体用packed进行了修饰,一般情况下,结构体会按其所有变量的大小的最小公倍数做对齐,而用packed修饰后,结构体会变为按1字节对齐,这样使得flags和buf数组的地址是完全连续的,这样做的好处有以下两点:
- 节省空间
- 无论是哪种类型的sds,都可以用(char*)sh+hdrlen由结构体地址sh得到buf指针的地址,同时也都可以用buf[-1]由buf得到flags的值,如果没有packed修饰,还需要对不同类型的sds做区分处理, 实现更复杂。
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
uint64_t len; /* used */
uint64_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};二. 创建字符串
Redis关于sds的操作都在sds.c中,创建字符串的函数为sdsnewlen,该函数接受两个参数:1.init:要创建的字符串的内容,是一个void指针;2. initlen:要创建的字符串的长度
该函数根据initlen选择SDS_TYPE,计算头部长度(len,alloc和flags变量的长度)和柔性数组的初始长度,然后动态分配内存,逻辑比较简单,具体可以看下面代码的注释。重点需要注意以下几点:
- 如果创建的是空字符串,会选择SDS_TYPE_8而不是SDS_TYPE_5,因为创建空字符串时,通常是为了后续在其后面追加内容,后续可能会成长为一个大于31长度的字符串,那么需要将字符串内容转换为SDS_TYPE_8,既然如此,那么不如一开始创建的时候就直接创建sdshdr8,而不是sdshdr5,并且sdshdr5是没有冗余空间的,每次扩容都需要新申请内存,效率很低。
- 方法返回的是柔性数组buf的指针s,因此可以通过s[-1]访问到flags。
sds sdsnewlen(const void *init, size_t initlen) {
void *sh;
sds s;
//根据字符串长度选择SDS_TYPE
char type = sdsReqType(initlen);
/* Empty strings are usually created in order to append. Use type 8
* since type 5 is not good at this. */
//如果是空字符串,直接创建sdshdr8
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
//计算头部长度
int hdrlen = sdsHdrSize(type);
unsigned char *fp; /* flags pointer. */
//申请大小为hdrlen+initlen+1长度的内存,+1是因为字符串末尾要追加一个额外的结束符 '\0'
//创建一个新字符串时是没有冗余空间的,buf数组的总长度就等于字符串的长度+1
sh = s_malloc(hdrlen+initlen+1);
//SDS_NOINIT是一个标志字符串,如果字符串内容为SDS_NOINIT,意味着用0填充buf
if (init==SDS_NOINIT)
init = NULL;
else if (!init)
memset(sh, 0, hdrlen+initlen+1);
if (sh == NULL) return NULL;
//s为指向buf数组的指针
s = (char*)sh+hdrlen;
//通过s-1直接获取flags指针
fp = ((unsigned char*)s)-1;
switch(type) {
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS);
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
}
//将字符串的内容复制到buf中
if (initlen && init)
memcpy(s, init, initlen);
//结尾追加结束符
s[initlen] = '\0';
return s;
}三. 释放字符串
sds有两种释放的方式:直接释放内存和重置字符串,分别为sdsfree函数和sdsclear函数。
sdsfree函数会将sds结构体的内存完全释放,该函数通过对buf指针的偏移定位到sds结构体的首部,然后调用s_free释放内存(s_free就是zfree)。
sdsclear函数并不释放内存,而是仅对sds结构体的变量进行重置,buf的内存并不被回收,新的数据可以覆盖写。
void sdsfree(sds s) {
if (s == NULL) return;
s_free((char*)s-sdsHdrSize(s[-1]));
}
void sdsclear(sds s) {
sdssetlen(s, 0);
s[0] = '\0';
}四. 字符串扩容
sds扩容操作涉及的参数:
- len:扩容前buf已使用的空间大小
- avail:扩容前buf剩余空间大小,等于alloc-len
- addlen:需要扩容的空间大小
- newlen:扩容后buf的总大小
- hdrlen:扩容后sds的头部大小
- oldtype:扩容前sds的类型
- type:扩容后sds的类型
sds的扩容操作流程如下:

同样需要注意的是,即使计算得到扩容后的sds类型为SDS_TYPE_5,也会强转为SDS_TYPE_8,理由和上面一样
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
/* Return ASAP if there is enough space left. */
//如果剩余可用空间大于需要扩容的空间,直接返回
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen);
//如果len+addlen小于1MB,newlen=2*(len+addlen),相当于预分配len+addlen的冗余空间
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
//如果len+addlen大于等于1MB,newlen=len+addlen+1MB,相当于预分配1MB的冗余空间
else
newlen += SDS_MAX_PREALLOC;
//计算新长度的sds类型
type = sdsReqType(newlen);
/* Don't use type 5: the user is appending to the string and type 5 is
* not able to remember empty space, so sdsMakeRoomFor() must be called
* at every appending operation. */
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
//如果不需要改变sds类型,在原有sds上重新分配内存
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc */
//如果需要改变sds类型,创建一个新的sds,将原有sds内容复制过来,再free掉
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, newlen);
return s;
}五. 字符串缩容
没错,除了对sds进行扩容,还可以对sds进行缩容,也就是将sds冗余的(或者说预分配的)内存空间free掉,不改变原字符串的内容,但新的sds的avail=0。注意sdsRemoveFreeSpace函数会使得传入的sds失效,该函数的流程如下:
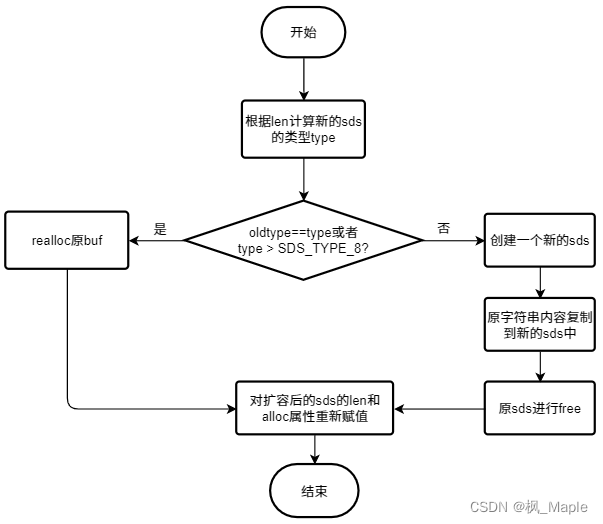
sds sdsRemoveFreeSpace(sds s) {
void *sh, *newsh;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen, oldhdrlen = sdsHdrSize(oldtype);
size_t len = sdslen(s);
sh = (char*)s-oldhdrlen;
/* Check what would be the minimum SDS header that is just good enough to
* fit this string. */
type = sdsReqType(len);
hdrlen = sdsHdrSize(type);
/* If the type is the same, or at least a large enough type is still
* required, we just realloc(), letting the allocator to do the copy
* only if really needed. Otherwise if the change is huge, we manually
* reallocate the string to use the different header type. */
//如果新sds的type > SDS_TYPE_8, 同样不会对sds类型进行降级,因为字符串太长了,重新对buf进行赋值的操作会很耗时
if (oldtype==type || type > SDS_TYPE_8) {
newsh = s_realloc(sh, oldhdrlen+len+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+oldhdrlen;
} else {
newsh = s_malloc(hdrlen+len+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, len);
return s;
}其他的一些对sds的操作的原理都比较简单,这里就不一一阐述了。
- sds sdscatsds (sds s, const sds t):将t的字符串拼接到s后面,返回拼接后的sds,该方法会涉及到字符串的扩容操作。
- sds sdsdup(const sds s):复制给定的sds
- void sdsfree(sds s):将指定的sds进行free
- void sdsupdatelen(sds s):手动计算buf的已使用长度,然后赋值给len
- sds sdsgrowzero(sds s, size_t len):将sds扩容至指定长度,并用0填充新增内容
- sds sdscpylen(sds s, const char *t, size_t len):将c字符串t的前len个字符赋值给指定sds
- void sdsrange(sds s, ssize_t start, ssize_t end):将sds修改为他的子字符串。
- int sdscmp(const sds s1, const sds s2):比较两个sds的字符串的字典顺序