前言
前短时间,为了验证公司的验证码功能存在安全漏洞,写了一个爬虫程序爬取官网图库,然后通过二值分析,破解验证码进入系统刷单。 其中,整个环节里关键的第一步就是利用 Python 爬虫技术就是拿到数据。
今天,我打算把爬虫经验分享一下,因为不能泄露公司核心信息,所以只能再一次拿“某瓣电影”开刀啦,O(∩_∩)O哈哈~
通过本篇,你将学会破解【身份鉴别】类的反爬虫程序,并利用 BeautifulSoup 解析静态的HTML页面,还有使用 xlwt 插件操作 Excel。
本文仅教学使用,无任何攻击行为或意向。
正文
一、页面分析
1. 打开页面,提取关键信息
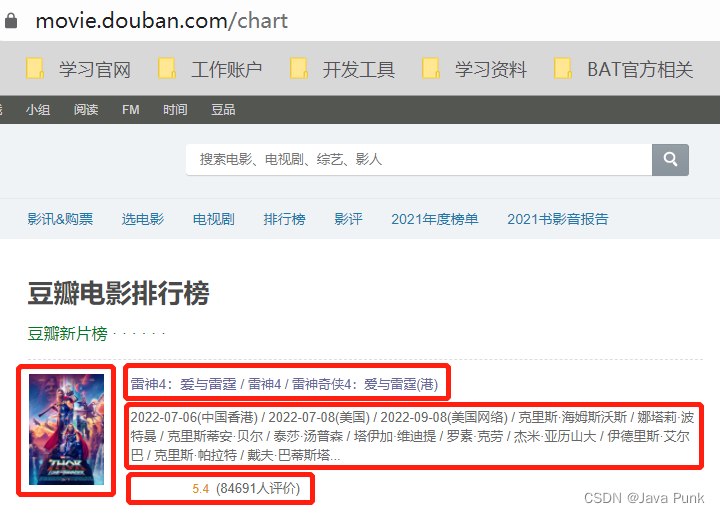
首先,打开“某瓣电影一周新片榜”的页面:https://movie.douban.com/chart,截图省略了下面列表部分。
然后,提取榜单里的关键信息,如:电影名,图片链接,详情链接,评分,评论数等,这是我们需要爬取的数据,接下来就需要弄清楚他们在 Html 中的位置。
2. 分析Html页面
Chrome浏览器 - 【F12】检查下 Html 页面结构,找到排行榜数据的具体位置,这对我们后续利用 BeautifulSoup 解析至关重要。
下面图片里可以看到,TOP10榜单信息在 “<div class="indent"></div>” 标签里,而每一条记录都在 “<tr class="item"></tr>” 标签里,10条 “<tr></tr> ”标签形成一个List集合。

3. BeautifulSoup准备
BeautifulSoup 就是 Python 的一个 HTML 或 XML 的解析库,利用 BeautifulSoup 解析器可以把 HTML 标签和属性变得像对象那样获取,正式利用这点,我们才能方便地从网页中提取数据。
简单介绍一下 BeautifulSoup 的解析器,通常Python 标准库 - “html.parser”就够用了:

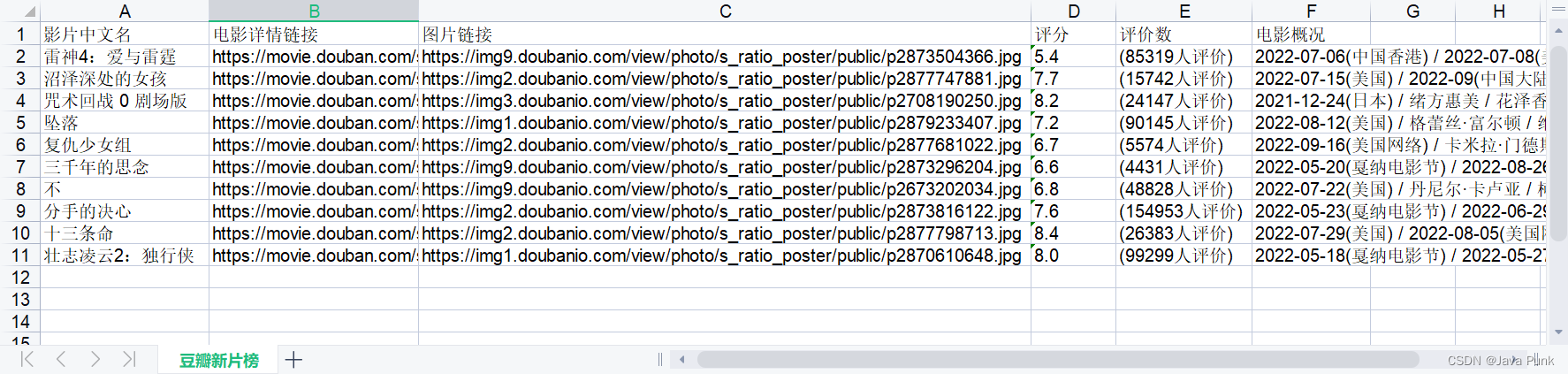
4. 结果展示
开发好 python 爬虫代码后,爬取成功后的 csv 数据,如下:
二、代码讲解
1. 导入关键库
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 网页解析
import os.path # 文件操作
import urllib.request, urllib.error # URL操作,获取网页数据
import xlwt # excel操作2. 发送URL请求
baseurl = "https://movie.douban.com/chart"
head = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
request = urllib.request.Request(baseurl, headers=head)
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
print(html)3. BeautifulSoup解析数据
# 1.利用 BeautifulSoup 标准库,解析页面信息
soup = BeautifulSoup(html, "html.parser")
# 2.获取所有 class_="item" 的 <tr></tr>
for item in soup.find_all('tr', class_="item"):
# <tr>标签下第一个<td>标签下第一个<a>标签内“title”的值
print(item.td.a["title"])
# <tr>标签下第一个<td>标签下第一个<a>标签内“href”的值
print(item.td.a["href"])
# <tr>标签下第一个<td>标签下第一个<img>标签内“src”的值
print(item.td.img["src"])
# <tr>标签下第一个属性 class_='rating_nums' 的<span>标签的文本的值
print(item.find('span', class_='rating_nums').text)
# <tr>标签下第一个属性 class_='pl' 的<span>标签的文本的值
print(item.find('span', class_='pl').text)
# <tr>标签下第一个<p>标签的文本的值
print(item.p.text)4. 保存数据
这里用到的是 xlwt 包,将数据写入 csv 保存到当前程序目录,用法和Java里的EasyUI很类似。
# 创建workbook对象
book = xlwt.Workbook(encoding="utf-8",style_compression=0)
# 创建工作表
sheet = book.add_sheet('豆瓣新片榜', cell_overwrite_ok=True)
col = ("影片中文名", "电影详情链接", "图片链接", "评分", "评价数", "电影概况")
book.save("豆瓣新片榜.xls") 5. 完成代码
预下载好相应的插件,直接运行就可以了。
# -*- codeing = utf-8 -*-
from bs4 import BeautifulSoup # 网页解析
import os.path # 文件操作
import urllib.request, urllib.error # URL操作,获取网页数据
import xlwt # excel操作
# 获取原始 html 网页
def readHtml():
print("—————————— Read ——————————")
# 要爬取的网页链接
baseurl = "https://movie.douban.com/chart"
# 模拟浏览器头部信息,向豆瓣服务器发送消息
# 用户代理,表示告诉豆瓣服务器,我们是什么类型的机器、浏览器(本质上是告诉浏览器,我们可以接收什么水平的文件内容)
head = {
"User-Agent": "Mozilla / 5.0(Windows NT 10.0; Win64; x64) AppleWebKit / 537.36(KHTML, like Gecko) Chrome / 80.0.3987.122 Safari / 537.36"
}
request = urllib.request.Request(baseurl, headers=head)
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
html = ""
try:
response = urllib.request.urlopen(request)
html = response.read().decode("utf-8")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
return html
# 从 html 页面爬取数据
def getData(html):
print("—————————— Process ——————————")
datalist = [] # 用来存储爬取的网页信息
# 1.逐一解析数据
soup = BeautifulSoup(html, "html.parser") # BeautifulSoup解析页面信息
soup.prettify()
for item in soup.find_all('tr', class_="item"): # 查找符合要求的字符串
data = [] # 保存一部电影所有信息
# 2.生成一条记录
data.append(item.td.a["title"])
data.append(item.td.a["href"])
data.append(item.td.img["src"])
data.append(item.find('span', class_='rating_nums').text)
data.append(item.find('span', class_='pl').text)
data.append(item.p.text)
# 3. 存入list
datalist.append(data)
return datalist
# 保存数据到表格
def saveData(datalist, savepath):
print("—————————— save ——————————")
book = xlwt.Workbook(encoding="utf-8",style_compression=0) # 创建workbook对象
sheet = book.add_sheet('豆瓣新片榜', cell_overwrite_ok=True) # 创建工作表
col = ("影片中文名", "电影详情链接", "图片链接", "评分", "评价数", "电影概况")
for i in range(0, len(col)):
sheet.write(0, i, col[i]) # 列名
for i in range(0, len(datalist)):
# print("第%d条" %(i+1)) # 输出语句,用来测试
data = datalist[i]
for j in range(0, len(col)):
sheet.write(i+1, j, data[j]) # 数据
if os.path.exists(savepath):
os.remove(savepath)
book.save(savepath) # 保存
pass
if __name__ == "__main__":
print("—————————— 开始执行 ——————————")
# 1. 读取uri
html = readHtml()
# 2. 处理Html数据
data = getData(html)
# 3. 保存数据
saveData(data, "豆瓣新片榜.xls")
print("—————————— 爬取完毕 ——————————")