混音基础理论篇
什么是声音
声音是由物体震动,从而对周围空气产生的一种挤压压力,形成的声音效果。可以在脑海中想象一下水波纹的效果图。并且声音在传输时需要介质,无介质如真空是无法传递声音的,由于声音从音源出来会经过各种反射如墙面,各种反射声音经过叠加混音后传入人耳,才是我们听到的声音,所以大部分情况下我们听到的都是混音,除混音外也有可能同一音源经过墙面反射后先后到达我们的耳朵,但当两次声音间隔小于0.1s时人耳是无法感知的。
声音的基本属性

从上图声波示图中,知道波有频率、振幅和波形等特性,频率代表音阶的高低,振幅代表响度,波形代表音色;
人耳只对20Hz~20kHz频率的声音敏感,其他频率的声音是无法感知的,振幅高低决定人耳接收到声音大小,通常用分贝来度量,最后音色也好理解,同样频率、振幅情况下,钢琴和小提琴发出的音色是不同的,原因是他们所发出的声波波形不一样导致的。
频域中的声音
上面介绍的声音都是从时域角度触发来分析,但是有时候无法从时域中获取更多信息时,可以尝试转换一个角度,从频域角度来分析。那什么是频域呢?继续往下看:
通常自然界中的大部分声音不可能像上面正弦声波图形一样简单,往往都是由几种不同频率的声波组合而成,并且一个声波也可以使用傅立叶变换转换为频域内的多个声波信号,如下图(摘自知乎):

我们可以利用正余弦公式,用代码生成一份音频样本,该样本由多种频率信号构成,主频时440:
double sample_rate = 44100.0;
double duration = 5.0;
double step = 2 * PI * 440 / SAMPLE_RATE;
int i = 0;
short raw[SAMPLE_POINTE];
double temp;
double amplitude = 0;
FILE* fp = fopen("raw.pcm", "w+");
if(fp == NULL){
cout << "open file raw.pcm error!" << endl;
return -1;
}
for(i = 0; i < SAMPLE_POINTE; i++){
temp = sin(amplitude);
// temp = (sin(amplitude) + sin(amplitude * 2 + PI / 2) + sin(amplitude * 3 + PI / 3) + sin(amplitude * 4 + PI / 4)) * 0.25;
temp = (short)(temp * 32675);
amplitude += step;
raw[i] = temp;
}
fwrite(raw, sizeof(raw), 1, fp);
fclose(fp);
使用Audacity打开音频样本,波形时这样的:

它不在像上面的正弦声波图像,因为其中加入了其他集中声音波信号,并且我们从时域中无法分析这份音频样本有哪些频率的音频组成,怎么办?
可以试试切换到频域中来分析,在分析上面音频样本时,使用Audacity软件的频谱分析功能分析这段音频,也就是从频域分析,如下图:

可以看出这段音频有多个波峰组成,每个波峰对应一个频率的声音信号,第一个波峰时440Hz左右,第二个在881Hz左右,依次有第三第四波峰,刚好对应我们代码中设置的音频频率值。
所以,当我们无法从时域中获取更多信息时,可以从频域中分析。
声音的音量属性 — 分贝
贝尔
贝尔(Bel)单位的定义是 同类型数值的对数差值,如:
lg A − lg B = lg A B \lg A - \lg B = \lg \frac{A}{B} lgA−lgB=lgBA
分贝(deciBel)的定义是:10倍贝尔
1 B e l = 10 d e c i B e l 1 Bel = 10 deciBel 1Bel=10deciBel
单独拎出贝尔和分贝,不代表任何物理类型,他们是处理数值的一种对数差值或手段,要和其他物理量结合一起才有实际的意义,比如1 dBSWL,读出1分贝声功率(后面会具体解释这个单位),代表在声功率与参考基本声功率的差值为1,也就是当前声功率大小为1dBSWL
声音相关公式的推导
声功率、声强、声压
-
声功率(Sound Power Level)指声源在单位时间内辐射的总能量,单位W,瓦。
声源视角(声功率):我们都知道,声音是需要有声源的(图2),而声功率一般就是用来描述声源的声功率(有废话内味儿),当我们在说声功率的时候,一般就与声源有关了,普遍指声源向外辐射声波的功率大小。 -
声强(Sound intensity Level)指声源在单位面积上的辐射量,单位面积垂直于声源辐射方向,记为I,单位为 W / m 2 W/m^2 W/m2,瓦每平方。
路径视角(声强):什么叫路径视角呢,这么来说吧,在实际应用中,声强可以用来测试隔音材料的隔音效果(图3),声强还可以用来对噪声源进行定位,这便是所谓的路径视角。 -
声压(Sound pressure Level),因为声源辐射后,扰动空气进而产生一个叠加在大气压上的压强,记为P,单位Pa,这里的声压指产生的压强减去大气压。
听音者(声压):听音者为什么能感知到声音?这是因为声波是有声压的,声压形成空气振动,然后振动传递到人的耳膜(图4),如此人便能听到声音,当声压大的时候,人听到的声音的音量就大,当声压小的时候,人听到的声音的音量就小。所以,当人们在讨论声音音量的大小时,往往指的就是声压的大小。

有了以上概念后,物理学家通过测量1kHz的声源发声下,人耳能听到最小的声音,测量除了其声功率、声强和声压的基准值;

除了基准参考值,科学家们还定义了一些其它的具象值,比如1W为接近人耳痛阈的声功率值,1W/m²为接近人耳痛阈的声强值,20Pa为接近人耳痛阈的声压值。
对数公式转换定理
先熟悉下对数的公式定理
lg A − lg B = lg A B \lg A - \lg B = \lg \frac{A}{B} lgA−lgB=lgBA
lg A + lg B = lg A B \lg A + \lg B = \lg {AB} lgA+lgB=lgAB
lg A n = n lg A \lg {A^n} = n \lg A lgAn=nlgA
大致有一个对数函数图像的概念图,如下:

分贝公式推导
以声功率为例,综上人耳可接收的声功率范围就在 1 0 − 12 到 1 W 10^{-12}到1W 10−12到1W这个范围,而这个范围内我们计算声功率的范围就很广,假设
W a = 0.0256662338661 W W_a=0.0256662338661W Wa=0.0256662338661W, W 2 = 0.0019932338993 W W_2=0.0019932338993W W2=0.0019932338993W,那我们计算 W 1 比 W 2 W_1比W_2 W1比W2大多少?并且如果 W 2 W_2 W2声音太小,我们增加它本身的一半值,声音会不会也增大一半呢?实质声音可能根本没啥变化,因为他们的关系是非线性的,那我们要他的声音增大一半,怎么计算要增益多大声功率呢?
首先,以上声功率数值较长,科学家们想出用取对数的方式来表达声功率:
W a = 0.0256662338661 W = lg 0.0256662338661 = − 1.6 W_a = 0.0256662338661W = \lg0.0256662338661 = -1.6 Wa=0.0256662338661W=lg0.0256662338661=−1.6
W b = 0.0019932338993 W = lg 0.0019932338993 = − 2.7 W_b = 0.0019932338993W = \lg0.0019932338993 = -2.7 Wb=0.0019932338993W=lg0.0019932338993=−2.7
那他们相差多少呢? W a − W b = − 1.6 − ( − 2.7 ) = 1.1 W_a - W_b = -1.6 - (-2.7) = 1.1 Wa−Wb=−1.6−(−2.7)=1.1,这不就是贝尔Bel的定义吗? W 1 W_1 W1的声功率比 W 2 W_2 W2大1.1贝尔;
同理1.1小数也不太直观,乘10换成整数就是11分贝,这样分贝和声功率结合就是11dBSWL,叫做声功率级,代表的就是声功率之间的差值;最后我们的推导公式就是:
声功率差值:
差值 B e l = lg W a − lg W r e f = lg W a W r e f 差值Bel = \lg{W_a} - \lg{W_ref} = \lg \frac{W_a}{W_{ref}} 差值Bel=lgWa−lgWref=lgWrefWa
差值 d B = 10 差值 B e l = 10 lg W a W r e f = d B S W L 差值dB = 10 差值Bel = 10 \lg\frac{W_a}{W_{ref}} = dBSWL 差值dB=10差值Bel=10lgWrefWa=dBSWL
通常我们的参考基础声功率 W r e f = 1 0 12 W_{ref}=10^{12} Wref=1012
参考推导出来的公式,计算 W a W_a Wa的分贝声功率级就是104, W b W_b Wb的分贝声功率级就是93,相差11个分贝声功率等级;
同理声强级推导和声功率差不多,本文就不在推导了;声压推导稍有不同;
声压级
声压级(Sound Pressure Level)指的是目标声压与参考声压之间的相对差值,简写为SPL,记为 ,单位为dBSPL,需要注意的是,声压的基准参考值是0.00002Pa。声压级的计算公式与声功率级或声强级的计算公式略有不同,“功率级”(声功率级与声强级)都是乘以10,而声压级则是乘以20;
音频领域内(如音乐制作、电视广播节目等)的dB值,绝大部分都指的是dBSPL值,也就是所谓的声压级,只不过是人们在称呼声压级的时候往往省略了后面的SPL。
看下图,不同升压级别下,声压和声强的数值:
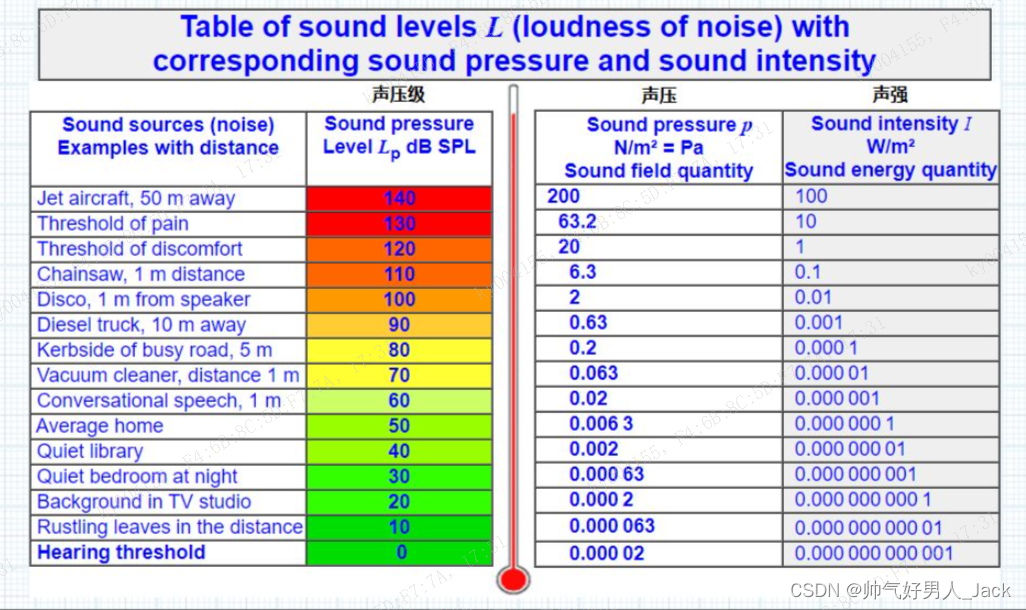
科学家们发现不同的声压级下,声压的平方与声强成正比,比如80和70声压级下:
( 比值 ) r a t i o 80 = 0.001 0. 2 2 = 0.0025 (比值)ratio_{80} = \frac{0.001}{0.2^2} = 0.0025 (比值)ratio80=0.220.001=0.0025
( 比值 ) r a t i o 70 = 0.00001 0.06 3 2 = 0.0025 (比值)ratio_{70} = \frac{0.00001}{0.063^2} = 0.0025 (比值)ratio70=0.06320.00001=0.0025
其他声压级别可以自行计算,比值也是约等于0.0025, 假设声压为 p p p,声强我 I I I,也就是说 I = 0.0025 ∗ p 2 I = 0.0025*p^2 I=0.0025∗p2,这样带入声强级推导公式中:
声强级 = 10 lg I I r e f = 10 lg p 2 p r e f 2 = 10 lg ( p p r e f ) 2 = 20 lg p p r e f 声强级 = 10 \lg \frac{I}{I_{ref}} = 10 \lg \frac{p^2}{p_{ref}^2} = 10 \lg (\frac{p}{p_{ref}})^2 = 20 \lg \frac {p}{p_{ref}} 声强级=10lgIrefI=10lgpref2p2=10lg(prefp)2=20lgprefp
参考基础声压为 2 ∗ 1 0 − 5 2*10^{-5} 2∗10−5,那假设待测声压为20Pa,那它的声压级是 20 ∗ lg 20 2 ∗ 1 0 − 5 20*\lg \frac{20}{2*10^{-5}} 20∗lg2∗10−520就等120dBSPL,也就是120分贝。
其实还有一个疑问?一开始功率的数字小数点后太多位,科学家用对数函数去处理这个值合理吗?为什么不直接放大很多倍比如统一乘一个 1 0 x 10^x 10x,(x>0),这样也可以解决数字大小的问题呢?
博主查了很多资料,也没有找到这方面的解释,最后自己做了这方面觉得还算一个合理的猜测,如下:
试想最后声压级的推导公式 y ( p ) d B S P L = 20 ∗ lg p p r e f y(p) dBSPL = 20* \lg \frac {p}{p_{ref}} y(p)dBSPL=20∗lgprefp,这个y§书面上是分贝声压级的意思,通俗易懂一点就是我们人耳对这个声压的感知能力,这个函数的函数图像就是一个对数函数图像,图像可以看上面的对数公式转换定理章节,待测声压p大于参考基准声压 p r e f p_{ref} pref,默认图像从y轴大于0的地方开始,也就是一开始p逐渐变大我们人耳对声音的感知还算灵敏,并且这个灵敏不是线性的(线性的话图像应该是一条斜的线),到后面p变得很大了,y的变化也不明显了,同时我们人耳也感觉不到声音的再次变大了,也就是说我们最终推导的这个公式 y ( p ) d B S P L = 20 ∗ lg p p r e f y(p) dBSPL = 20* \lg \frac {p}{p_{ref}} y(p)dBSPL=20∗lgprefp符合人耳的听力情况,从反面推导了公式的合理性,也就是最终科学家用对数来处理这个的合理性
混音—分贝的叠加
混音在生活中无处不在,在自然界中通常是两路声压波进行叠加而成,对应到分贝中,1dB + 1dB的声音大小不等于2,参考上面的公式定义:
X d B = 10 lg P x 2 P r e f 2 X dB = 10\lg \frac {
{P_x}^2}{
{P_{ref}}^2} XdB=10lgPref2Px2 则,反向推导出 P x P_x Px
P x = P r e f ∗ 1 0 X d B 10 P_x = P_{ref} * \sqrt {10^{\frac {X dB}{10}}} Px=Pref∗1010XdB,最后在求两路声压级的叠加公式,得:
X d B + X d B = 10 ∗ lg P x 2 + P x 2 P r e f 2 = 10 ∗ lg 1 0 X d B 10 + 1 0 X d B 10 X dB + X dB = 10* \lg \frac {
{P_x}^2 + {P_x}^2}{
{P_{ref}}^2} = 10*\lg{10^{\frac{X dB}{10}} + 10^{\frac{X dB}{10}}} XdB+XdB=10∗lgPref2Px2+Px2=10∗lg1010XdB+1010XdB
= 10 ∗ lg 2 ∗ 1 0 X d B 10 = 10 ∗ lg 2 + X d B ≈ 3 + X d B = 10*\lg{2* 10^{\frac{X dB}{10}}} = 10* \lg2 + X dB \approx 3+XdB =10∗lg2∗1010XdB=10∗lg2+XdB≈3+XdB
按照这个公式,10 dB + 10 dB = 13 dB
音量的大小调节
声音是一个波形信号,一个波形上的幅值代表响度,也可以理解为音量的大小,如果要增大音量,也就要增大这个波形的幅值,也就是整个波形都要扩大,想想应该是这样,但是怎么建立理论基础呢?因为声音的公式是声压比,如何从声压比转换为幅值呢?
因为声压§的平方=声强(I) * 介质密度§ * 声速©,声强的大小与声速成正比,与声波频率的平方、振幅的平方成正比,也就是振幅与声压成正比的关系,所以在计算机里面处理混音时,取振幅比来计算声音分贝,如下:
A d B = 20 ∗ lg P a P 0 A dB = 20* \lg\frac{P_a}{P_0} AdB=20∗lgP0Pa
假设用户手动设置音量分贝为 A d B AdB AdB, P 0 P_0 P0是声音的原始振幅, P a P_a Pa是需要计算出了的幅值,计算出来后送入声卡音量就会增大了
A d b 20 = lg P a P 0 \frac{A db}{20} = \lg\frac{P_a}{P_0} 20Adb=lgP0Pa
1 0 A d B 20 = P a P 0 10^\frac{AdB}{20} = \frac{P_a}{P_0} 1020AdB=P0Pa
P 0 ∗ 1 0 A d b 20 = P a P_0 * 10^\frac{Adb}{20} = P_a P0∗1020Adb=Pa
所以,总结出来如上所示, P a P_a Pa等于原始振幅 P 0 P_0 P0和 A d B AdB AdB之间的乘积关系。这个在下篇混音实践篇中将会用到。
混音的实质
两路音频叠加在一起即是混音,自然界声波连续信号直接叠加在一起产生很好的效果;但是转化到计算机中的离散信号则不能直接叠加,需要一定的预处理,如采样率保证一致,但是为什么呢?
为什么采样率要一致
假设一个原始声波信号分别采用20Hz和40Hz的采样率,形成两份离散音频样本,一份有20个采样点,另一个是40个采样点,然后这两份音频不做任何处理,直接叠加混音,可以想像,在每个采样点逐次叠加时,第一个采样点没问题,但是从第二个点开始,在时间轴上采样的时间点时不同的,这样会造成混音的音频播放时会有两条重复的语音,一前一后,理论上是一条语音;同理两份不同的原始声波,分别采用不同的采样率产生的离散样本,直接叠加混音理论是没有问题的,只是播放时不是同一时刻的采样点,有可能造成两份音频播放的语速不一致。
如何解决上面的问题,保证相同的采样率,保证时域上音频采样点分布均匀,叠加的采样点是同一个时间基准的。
以上,是我对混音的理论理解,下篇文章将讲述android的Audioixer是如何进行混音的。