如何理解线程不安全
集合类就相当于一个资源类,并发的多个线程同时操作同一资源类对象时 调用它的成员方法修改成员属性值 如果调用的方法没有加锁 会出现并发的数据安全问题
线程不安全的集合
| List:ArrayList | Set: HashSet | Map:HashMap |
线程不安全List
1、ArrayList演示线程不安全
UUID回顾
String str1 = UUID.randomUUID().toString();//e251ab3e-fa96-478c-b32f-1028db9b396f String str2 = UUID.randomUUID().toString().replace("-","");//8f76be380f1346a1b8406ca233129b0e System.out.println(str1); System.out.println(str2);按照8-4-4-4-12的顺序进行分隔。加上中间的横杆,UUID有36个字符。

ArrayList线程不安全演示
List list = new ArrayList<>();
//并发多个线程操作资源类对象
for (int i = 0;i < 30; i++) {
new Thread(()->{
list.add(UUID.randomUUID().toString().substring(0,8));
System.out.println(list);//list.toString()
},i+"").start();
}控制台运行报错:并发修改异常

报错分析:
并发的多个线程同时更新集合中的数据,但是集合的方法没有加锁,导致并发的数据安全问题
public boolean add(E e) { ensureCapacityInternal(size + 1); // Increments modCount!! elementData[size++] = e; return true; }
深层次分析:
ArrayList:
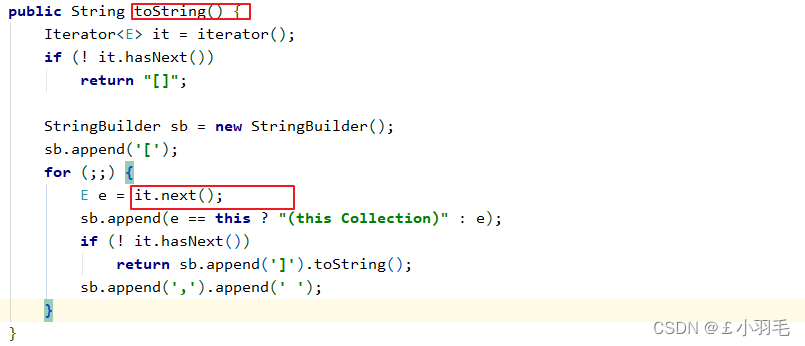
toSting方法执行时 会调用next方法 获取集合中的每一个元素 拼接集合的元素的字符串输出
next方法中 调用了checkForComodification 检查当前方法执行时元素的个数 和 现在集合中元素的个数是否一样。不一样 则抛出并发更新异常 “ConcurrentModificationException”//以下为ArrayList源码部分 final void checkForComodification() { if (modCount != expectedModCount) throw new ConcurrentModificationException(); }
但是ArrayList使用多的原因:
1、不加锁 性能高
2、以后Controller或者Servlet的方法 多线程并发访问时,每个方法执行时基本上不会再内部开子线程,一般也不会更新Controller或者Servlet定义的成员变量
每个线程调用的方法形成了一个独立的线程栈 ,不同线程栈中的方法互相独立。
每个方法中的局部变量操作时没有并发线程安全问题的 如果这个方法 使用的是 同一个对象的成员属性 是有并发数据安全问题
2、Vector 保证并发的线程安全
//线程安全的List集合类
Vector list = new Vector();
//并发多个线程操作资源类对象
for (int i = 0;i < 30; i++) {
new Thread(()->{
list.add(UUID.randomUUID().toString().substring(0,8));
System.out.println(list);//list.toString()
},i+"").start();
}Vector中基本所有的方法都添加了synchronized关键字保证线程安全
包括:CRUD和toString以及iterator()获取迭代器的方法


Vector 性能较差:内存消耗比较大,适合增量较大的写操作
3、SynchronizedList 装饰者模式
是Collections工具类提供的可以将线程不安全的List对象转为(装饰)线程安全的SynchronizedList对象
//线程安全的List集合类
List list = Collections.synchronizedList(new ArrayList<>());
//并发多个线程操作资源类对象
for (int i = 0;i < 30; i++) {
new Thread(()->{
list.add(UUID.randomUUID().toString().substring(0,8));
System.out.println(list);//list.toString()
},i+"").start();
}SynchronizedList 中基本上所有的方法 都通过synchronized(this)同步代码块加锁,代码块内的方法体通过创建对象时接收的不安全的List对象相同的方法来实现 【装饰者模式】

SynchronizedList: ,迭代遍历性能要高于Vector

SynchronizedList 使用场景:适合并发写多 读稍少 使用较多
4、CopyOnWriteArrayList 写时复制
CopyOnWrite容器(简称COW容器)即写时复制的容器。
通俗的理解是当我们往一个容器添加元素的时候,不直接往当前容器添加,而是先将当前容器进行Copy,复制出一个新的容器,然后新的容器里添加元素,添加完元素之后,再将原容器的引用指向新的容器
这样做的好处是我们可以对CopyOnWrite容器进行并发的读,而不需要加锁,因为当前容器不会添加任何元素。所以CopyOnWrite容器也是一种读写分离的思想,读和写不同的容器。
写操作:不直接修改数据,先拷贝数据的副本,修改副本数据,改成功后使用副本替换原数据
//线程安全的List集合类
CopyOnWriteArrayList list = new CopyOnWriteArrayList();
//并发多个线程操作资源类对象
for (int i = 0;i < 30; i++) {
new Thread(()->{
list.add(UUID.randomUUID().toString().substring(0,8));
System.out.println(list);//list.toString()
},i+"").start();
}不会有竞争关系的原理: 每个线程并发时 都是修改自己拷贝的副本数据,多个线程不会修改同一个数据
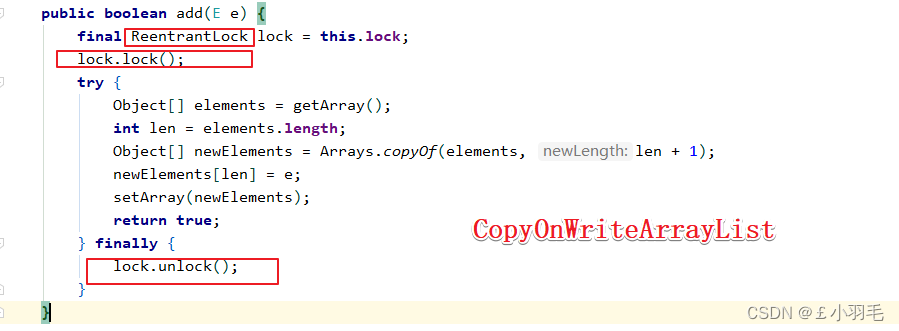
CopyOnWriteArrayList为了保证同时只有一个线程写数据 ;写/更新的方法使用了ReentrantLock加锁。
在向CopyOnWriteArrayList添加元素时,会复制⼀个新的数组,写操作在新数组上进⾏,读操作在原数组上 进⾏,写操作结束之后会把原数组指向新数组所有的读的方法均未加锁,读取数据时读取的是当前的集合的数据


cow优缺点:
优点:get/迭代器方法 性能高,未加锁
CopyOnWriteArrayList允许在写操作时来读取数据,⼤⼤提⾼了读的性能, 因此适合读多写少的应⽤场景缺点:
内存占用问题。写的时候会创建新对象添加到新容器里,而旧容器的对象还在使用,所以有两份对象内存。
数据一致性问题。CopyOnWrite容器只能保证数据的最终一致性,不能保证数据的实时一致性。所以如果你希望写入的的数据,马上能读到,请不要使用CopyOnWrite容器。
CopyOnWriteArrayList 使用场景:适合读多写少场景,比如白名单、黑名单。 尽量少用
5、线程安全的List性能测试
/*
线程安全的List的性能测试
先并发写入20w的数据,并发随机读取20w次数据各自的时间
*/
public static void main(String[] args) {
List list1 = new Vector();
//spring-core核心包中提供了StopWatch的工具类 可以帮助我们统计方法执行的时间
StopWatch stopWatch = new StopWatch();
stopWatch.start("vector:write");//一次统计开始
IntStream.rangeClosed(1,200000)
.parallel() //并行
.forEach(i->{
list1.add(i);
});
stopWatch.stop();//一次统计的结束
stopWatch.start("vector:read");//一次统计开始
IntStream.rangeClosed(1,200000)
.parallel() //并行
.forEach(i->{
list1.get(new Random().nextInt(200000));
});
stopWatch.stop();//一次统计的结束
//======================
List list2 = Collections.synchronizedList(new ArrayList<>());
stopWatch.start("synchronizedList:write");//一次统计开始
IntStream.rangeClosed(1,200000)
.parallel() //并行
.forEach(i->{
list2.add(i);
});
stopWatch.stop();//一次统计的结束
stopWatch.start("synchronizedList:read");//一次统计开始
IntStream.rangeClosed(1,200000)
.parallel() //并行
.forEach(i->{
list2.get(new Random().nextInt(200000));
});
stopWatch.stop();//一次统计的结束
//==========
List list3 = new CopyOnWriteArrayList();
stopWatch.start("CopyOnWriteArrayList:write");//一次统计开始
IntStream.rangeClosed(1,200000)
.parallel() //并行
.forEach(i->{
list3.add(i);
});
stopWatch.stop();//一次统计的结束
stopWatch.start("CopyOnWriteArrayList:read");//一次统计开始
IntStream.rangeClosed(1,200000)
.parallel() //并行
.forEach(i->{
list3.get(new Random().nextInt(200000));
});
stopWatch.stop();//一次统计的结束
//获取统计结果输出
System.out.println(stopWatch.prettyPrint());
}
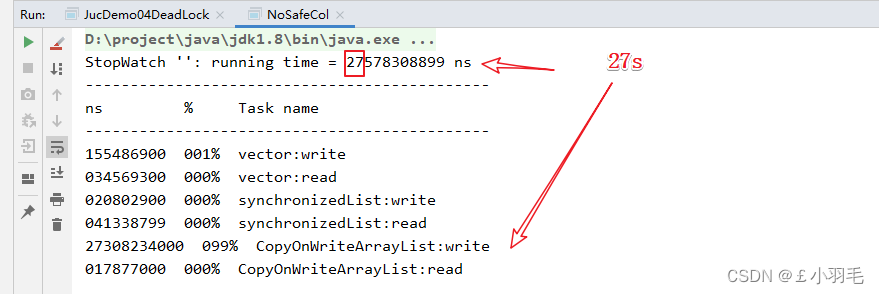
获取统计结果输出:看得出来时间基本都是cow在写的时候用掉的
线程不安全Set
1、HashSet演示线程不安全
//HashSet线程不安全测试: ConcurrentModificationException
Set set = new HashSet();
//并发多个线程操作资源类对象
for (int i = 0; i < 30; i++) {
new Thread(()->{
set.add(UUID.randomUUID().toString().substring(0,8));
System.out.println(set);//set.toString()
},i+"").start();
}
2、synchronizedSet 同步代码块加锁
通过同步代码块加锁,迭代器没有加锁
Set<Object> set = Collections.synchronizedSet(new HashSet<>());
//并发多个线程操作资源类对象
for (int i = 0; i < 30; i++) {
new Thread(()->{
set.add(UUID.randomUUID().toString().substring(0,8));
System.out.println(set);//set.toString()
},i+"").start();
}SynchronizedSet 原理和SynchronizedList基本一样
除了迭代器相关的方法 没有加锁,其他的方法都通过synchronized同步代码块加锁
SynchronizedSet 优先使用
3、CopyOnWriteArraySet
使用cow技术实现的并发安全的set
CopyOnWriteArraySet set = new CopyOnWriteArraySet();
//并发多个线程操作资源类对象
for (int i = 0; i < 30; i++) {
new Thread(()->{
set.add(UUID.randomUUID().toString().substring(0,8));
System.out.println(set);//set.toString()
},i+"").start();
}线程不安全Map
1、HashMap演示线程不安全
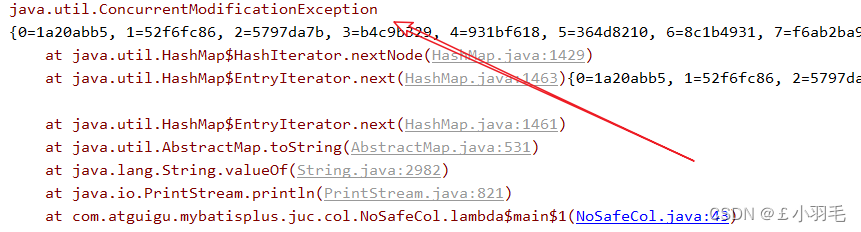
Map map = new HashMap();//ConcurrentModificationException
//并发多个线程操作资源类对象
for (int i = 0; i < 30; i++) {
String s = i+"";
new Thread(()->{
map.put(s , UUID.randomUUID().toString().substring(0,8));
System.out.println(map);//map.toString()
},i+"").start();
}
2、HashTable保证线程安全
//线程安全
//Hashtable:和vector类似,所有的方法都通过synchronized在方法上加锁了
Map map = new Hashtable();
//并发多个线程操作资源类对象
for (int i = 0; i < 30; i++) {
String s = i+"";
new Thread(()->{
map.put(s , UUID.randomUUID().toString().substring(0,8));
System.out.println(map);//map.toString()
},i+"").start();
}HashTable 所有的方法都加锁了
3、SynchronizedMap
//线程安全
//SynchronizedMap: 和synchornizedList/set 类似, 所有的方法都通过同步代码块加锁了
Map<Object, Object> map = Collections.synchronizedMap(new HashMap<>());
//并发多个线程操作资源类对象
for (int i = 0; i < 30; i++) {
String s = i + "";
new Thread(() -> {
map.put(s, UUID.randomUUID().toString().substring(0, 8));
System.out.println(map);//map.toString()
}, i + "").start();
}SynchronizedMap: 所有的方法都通过同步代码块加锁,包括迭代器也加锁了
4、ConcurrentHashMap 分段加锁
采用分段加锁 技术加锁,效率高、并发线程安全。
分段锁,就是将数据分段,对每⼀段数据分配⼀把锁。当⼀个线程占⽤锁访问其中⼀个段数据的时候,其他段的数据也能被其他线程访问在并发环境下将实现更⾼的吞吐量,⽽在单线程环境下只损失⾮常⼩的性能。
//线程安全
//ConcurrentHashMap: 分段加锁保证数据安全的同时可以提高CRUD的效率
Map map = new ConcurrentHashMap();
//并发多个线程操作资源类对象
for (int i = 0; i < 30; i++) {
String s = i + "";
new Thread(() -> {
map.put(s, UUID.randomUUID().toString().substring(0, 8));
System.out.println(map);//map.toString()
}, i + "").start();
}ConcurrentHashMap: 开发中优先使用
mysql的innodb存储引擎支持行级锁 和分段加锁技术类似
分段加锁的原理:只对 Map的 tab中 某个索引位置顶点元素加锁
⼀个 ConcurrentHashMap ⾥包含⼀个 Segment 数组, Segment 的结构和 HashMap类似,是⼀种数组和链表结构。⼀个Segment ⾥包含⼀个 HashEntry 数组,每个HashEntry是⼀个链表结构 的元素, 每个Segment 守护着⼀个 HashEntry 数组⾥的元素,当对HashEntry数组的数据进⾏修改时,必须⾸先获得它对应的 Segment 锁。/** Implementation for put and putIfAbsent */ final V putVal(K key, V value, boolean onlyIfAbsent) {//方法未加锁 if (key == null || value == null) throw new NullPointerException(); int hash = spread(key.hashCode());//计算key的hashcode值 int binCount = 0; for (Node<K,V>[] tab = table;;) {//死循环 循环内的代码只有执行了break或者return或者抛出异常循环才会结束 tab 接收了table 也就是kv值构成的Node节点的数组 Node<K,V> f; int n, i, fh; if (tab == null || (n = tab.length) == 0)//判断Map的Node节点的数组是否为空 tab = initTable();//初始化Map的Node节点数组 后面没有结束循环 所以继续执行下一次循环 通过n接收Node节点数组的长度 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {//使用存入数据的key的hash和数组的长度-1 &运算 得到当前key在tab中应该存储的索引 最后从tab中根据索引获取元素 //如果此行执行 代表key在tab中的索引位置没有存入元素 //将key和value创建为Node对象 存入到tab的索引为i的位置(cas:compare and swap 利用c操作系统中硬件级别支持的函数保证线程安全) if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } else if ((fh = f.hash) == MOVED)//Map数据正在迁移 不管 tab = helpTransfer(tab, f); else {// 代表key在tab中要存入的索引位置存在元素 V oldVal = null; //分段加锁的原理:只对 Map的 tab中 某个索引位置顶点元素加锁 synchronized (f) {//f代表key在tab中要存储的位置的Node节点对象 使用同步代码块加锁 if (tabAt(tab, i) == f) {//判断锁定的对象是否正确 if (fh >= 0) {//将新增的k-v创建为node对象 添加到f的最后的下一个节点中 binCount = 1; for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((ek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; if (!onlyIfAbsent) e.val = value; break; } Node<K,V> pred = e; if ((e = e.next) == null) { pred.next = new Node<K,V>(hash, key, value, null); break; } } } else if (f instanceof TreeBin) { Node<K,V> p; binCount = 2; if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key, value)) != null) { oldVal = p.val; if (!onlyIfAbsent) p.val = value; } } } } if (binCount != 0) { if (binCount >= TREEIFY_THRESHOLD) treeifyBin(tab, i); if (oldVal != null) return oldVal; break; } } } addCount(1L, binCount); return null; }
并发容器和同步容器
1、并发容器
并发容器:不直接加锁的通过其他方式保证并发线程安全的容器类。在jdk5.0引入了concurrent包,其中提供了很多并发容器
ConcurrentHashMap: 分段加锁
内部采用Segment结构,进行两次Hash进行定位,写时只对Segment加锁CopyOnWriteArrayList/CopyOnWriteSet:写时复制技术
写时复制一份新的容器,在新的上面修改,然后把引用指向新的。只能实现数据的最终一致性,非实时一致的;代替List,适用于读操作为主的情况
2、同步容器
同步容器可以简单地理解为通过synchronized来实现同步的容器。
同步容器会导致多个线程中对容器方法调用的串行执行,降低并发性,因为它们都是以容器自身对象为锁。在并发下进行迭代的读和写时并不是线程安全的
Vector、Stack、HashTable、Collections类的静态工厂方法创建的类(如Collections.synchronizedList)
小总结:
线程不安全使用ArrayList,线程安全使用synchronizedList
线程不安全使用HashMap,线程安全 使用ConcurrentHashMap
juc强大的辅助类
juc的辅助类只能在单体应用中起作用,分布式集群启动的应用会失效
将来Redis提供了Redisson,它提供了juc辅助类 对应的 分布式的辅助类
使用场景:多个线程间需要协作通信时使用,不需要我们自己考虑线程间如何通信
--------------------
1、CountDownLatch:倒计数器
作用:可以控制倒计数后执行特定的操作,但是只能进行一轮的倒计数
常用方法:
public CountDownLatch(int count) //实例化一个倒计数器,count指定初始计数
public void countDown() // 每调用一次,计数减一
public void await() //等待,当计数减到0时,阻塞线程并行执行count值只能被设置⼀次,CountDownLatch没有提供任何机制去重新设置这个计数值。
场景例如:在手机上安装一个应用程序,假如需要5个子进程检查服务授权,那么主进程会维护一个计数器,初始计数就是5。用户每同意一个授权该计数器减1,当计数减为0时,主进程才启动,否则就只有阻塞等待了。
CountDownLatch cdl = new CountDownLatch(5);
for (int i = 1; i <=5; i++) {
new Thread(()->{
System.out.println(Thread.currentThread().getName()+" 检查授权服务...");
int anInt = new Random().nextInt(5);
try {
TimeUnit.SECONDS.sleep(anInt);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread().getName()+" 检查完毕,"+"用时:"+anInt+"秒");
cdl.countDown();//让countDownLatch的 count值-1
},"子进程-"+i).start();
}
cdl.await();//阻塞当前线程 直到 cdl设置的count的值变为0才停止阻塞
//主进程才启动
System.out.println("主进程: 授权成功");
面试:CountDownLatch 与 join 方法的区别
调用一个子线程的 join()方法后,该线程会一直被阻塞直到该线程运行完毕。
-----------
CountDownLatch 使用计数器允许子线程运行完毕或者运行中时候递减计数,也就是 CountDownLatch 可以在子线程运行任何时候让 await 方法返回而不一定必须等到线程结束;另外使用线程池来管理线程时候一般都是直接添加 Runnable 到线程池这时候就没有办法在调用线程的 join 方法了,countDownLatch 相比 Join 方法让我们对线程同步有更灵活的控制。
2、CyclicBarrier:循环栅栏
意思就是一个可循环利用的屏障。该命令只在每个屏障点运行一次。可以看成多组倒计时器的组合
常用方法
1.CyclicBarrier(int parties, Runnable barrierAction) 创建一个CyclicBarrier实例,
parties指定参与相互等待的线程数, barrierAction一个可选的Runnable命令, 该命令只在每个屏障点运行一次,可以在执行后续业务之前共享状态。 该操作由最后一个进入屏障点的线程执行。2.CyclicBarrier(int parties) 创建一个CyclicBarrier实例,parties指定参与相互等待的线程数。
3.await() 设置栅栏,创建CyclicBarrier对象时执行的数量线程数都执行到此行时栅栏才会放行
案例: 3个玩家玩游戏,所有人通过同一关后 才可以开始下一关 一共4关
//参数1:参与者数量 参数2:每次所有参与者到达栅栏时的回调任务
//回调任务谁执行:最后达到栅栏的子线程执行回调任务
CyclicBarrier cb = new CyclicBarrier(3, () -> {
System.out.println(Thread.currentThread().getName() + " 恭喜所有人过关.....");
});
for (int i = 1; i <= 3; i++) {
new Thread(() -> {
try {
System.out.println(Thread.currentThread().getName() + "正在准备中");
TimeUnit.SECONDS.sleep(new Random().nextInt(3));
System.out.println(Thread.currentThread().getName() + "准备完毕");
//所有玩家都准备好之后 开始第一关游戏
cb.await();//设置栅栏 创建CyclicBarrier对象时执行的数量线程数都执行到此行时栅栏才会放行
System.out.println(Thread.currentThread().getName() + "开始第一关");
TimeUnit.SECONDS.sleep(new Random().nextInt(5));
System.out.println(Thread.currentThread().getName() + "第一关通关");
//所有玩家都通过第一关游戏才开始下一关
cb.await();
System.out.println(Thread.currentThread().getName() + "开始第2关");
TimeUnit.SECONDS.sleep(new Random().nextInt(5));
System.out.println(Thread.currentThread().getName() + "第2关通关");
cb.await();
System.out.println(Thread.currentThread().getName() + "开始第3关");
TimeUnit.SECONDS.sleep(new Random().nextInt(5));
System.out.println(Thread.currentThread().getName() + "第3关通关");
cb.await();
System.out.println(Thread.currentThread().getName() + "开始最后1关");
TimeUnit.SECONDS.sleep(new Random().nextInt(5));
System.out.println(Thread.currentThread().getName() + "最后1关通关");
cb.await();
} catch (Exception e) {
e.printStackTrace();
}
}, "玩家: " + i).start();
}控制台打印

面试:CyclicBarrier和CountDownLatch的区别?
CountDownLatch的计数器只能使用一次,而CyclicBarrier的计数器可以使用reset()方法重置,可以使用多次,所以CyclicBarrier能够处理更为复杂的场景;CountDownLatch允许一个或多个线程等待一组事件的产生,而CyclicBarrier用于等待其他线程运行到栅栏位置。
3、Semaphore:信号量
作用:控制资源数量,不能超过资源的数量,被使用的资源释放后可以被复用
给定一个资源数目有限的资源池,假设资源数目为N,每一个线程均可获取一个资源,但是当资源分配完毕时,后来线程需要阻塞等待,直到前面已持有资源的线程释放资源之后才能继续
常用方法
public Semaphore(int permits) // 构造方法,permits指资源数目(信号量),默认情况下,是⾮公平的
public void acquire() throws InterruptedException // 占用资源,当一个线程调用acquire操作时,它要么通过成功获取信号量(信号量减1),要么一直等下去,直到有线程释放信号量,或超时。
public void release() // (释放)实际上会将信号量的值加1,然后唤醒等待的线程。
信号量主要用于两个目的:
多个共享资源的互斥使用。
用于并发线程数的控制。保护一个关键部分不要一次输入超过N个线程。
Semaphore往往⽤于资源有限的场景中,去限制线程的数量。案例:停车场抢车位,10个车抢三个车位。使用Semaphore限制同时只能有3个线程在⼯作
//构造器参数表示资源数量 为3个车位
Semaphore s = new Semaphore(3);
for (int i = 0; i < 10; i++) {
new Thread(()->{
try {
System.out.println(Thread.currentThread().getName()+" 开始抢车位....");
//如果抢到车位
s.acquire();//尝试获取资源 获取到停止阻塞 否则一直阻塞直到获取资源成功
s.tryAcquire(timeout,TimeUnit) 尝试获取资源 超过指定时间则中断
System.out.println(Thread.currentThread().getName()+" 抢到车位....正在停车");
int anInt = new Random().nextInt(8);
TimeUnit.SECONDS.sleep(anInt);
//释放停车位
s.release();//释放资源
System.out.println(Thread.currentThread().getName()+" 离开车位..."+"总计停车时长为"+anInt+"秒");
} catch (InterruptedException e) {
e.printStackTrace();
}
},"车辆:"+i).start();
}