上一篇文章我们说了 critical point 中的 local minima 可能会让训练停止,但其实更多的情况下是 saddle point 。这一次呢,我们说一下另外一个可能会让 training 止步不前的问题: learning rate 学习率。
在训练一个 network 的时候,往往会把它的 loss 记录下来,所以会看到原来 loss 很大但随著参数不断 update ,loss 会越来越小,最后就卡住了,loss 不再下降
那多数这个时候,大家就会猜说是不是走到了 critical point ,所以我们没有办法再更新参数,但是真的是这样吗?当我们说走到 critical point 的时候,意味著 gradient 非常的小,但我们当 loss 不再下降的时候很少会去确认 gradient 真的很小吗?

gradient 是一个向量,norm of gradient 是 gradient 的长度。随著参数更新的时候的变化,会发现说虽然loss 不再下降,但是这个 gradient 的大小并没有真的变得很小,那说明这并不是遇到了 critical point 而是我们 learning rate 学习率没有选取好。图左可以看到 update 在山谷两侧来回震荡,导致了 loss 不在下降,但是 gradient 的长度并没降低。
降低 learning rate 确实可以起到一定作用,比如:左边是 learning rate 为 10^-2 ,右边是 10^-7 。较小的 learning rate 确实从两边山谷震荡的情况,变成了下降。但这并没有达到我们的预期,因为黄色叉号是 error surface 的最低点,当梯度比较缓时,学习率也非常小,就会导致loss 停止下降。为了解决这一问题,我们需要动态的改变我们学习率,当梯度大时,学习率就小一点;梯度比较小时,学习率就大一些。

既然我们希望 learning rate 和 gradient 成反比关系,所以改写参数 update 的式子为:
,其中
与
成正比即可
比较常见的更新方法:
Root Mean Square
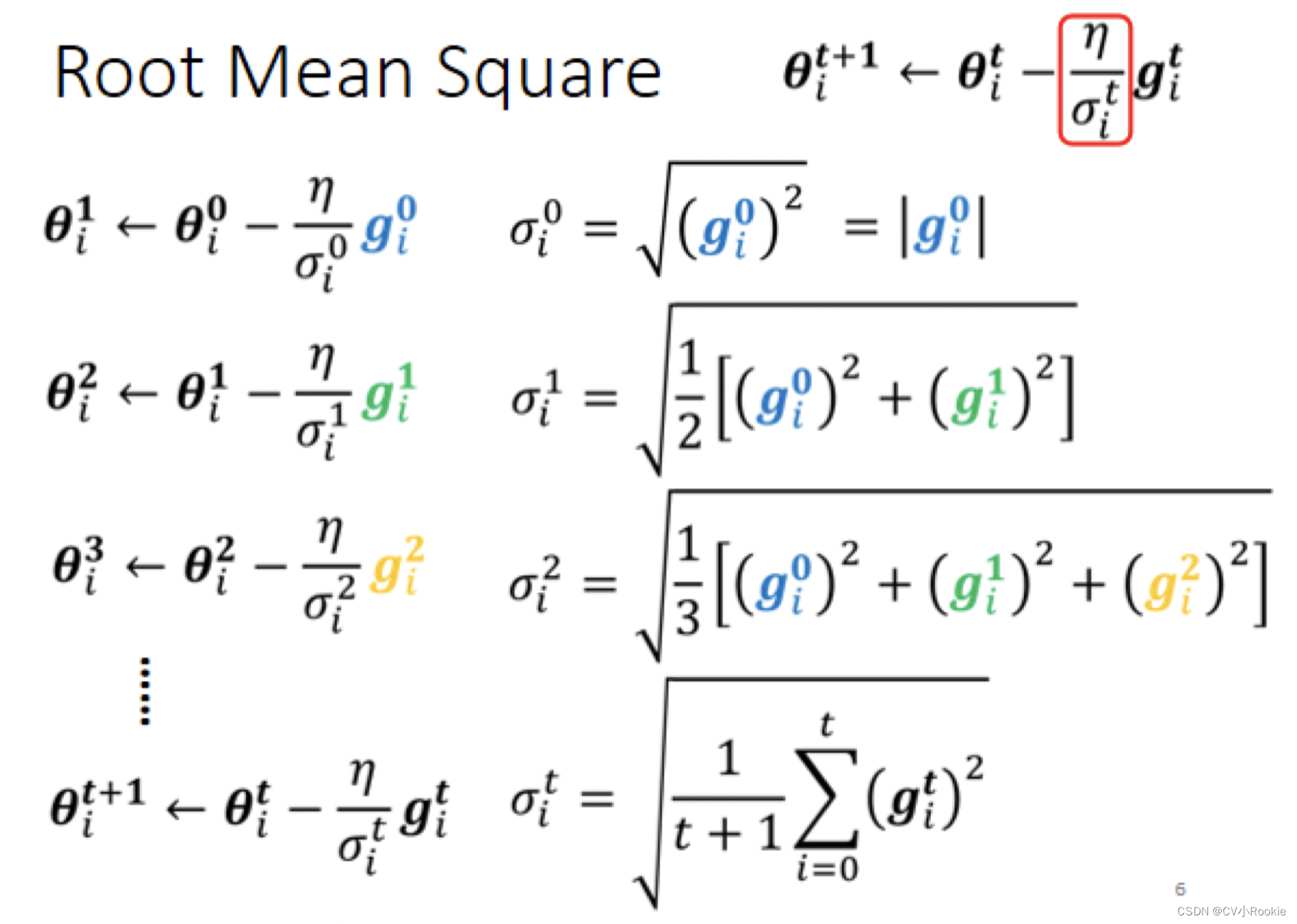
Adagrad 方法就采用的均方根方法。
RMSProp
RMSProp 相较于 Adagrad 方法引入了一个 hyperparameter 用来平衡当前 gradient 和历史 gradient 的权重:
这样调整有一个好处,可以根据我们的需要调整 ,把更多的注意力放在当前梯度还是过去的梯度。如果我们让
小一些,也就是更关注当前梯度,那我们的学习率反应就会快一些。

比如当遇到 update 时 gradient 突然变大了,如果是原来的 Adagrad的话它反应比较慢(所有 gradient 权值一样)
没能马上增大,learning rate 和 gradient 都很大,可能就很快就飞出去了,而不是沿着斜坡继续向下。 但如果用 RMSProp 然后把 α 设小一点,那么当前的 gradient 影响比较大,就可以很快的让 σ 的值变大,使得 learning rate 迅速变小。
Adam 方法采用的就是 RMSProp 方法。
当我们采用了自适应学习率调整后,发现,确实在梯度较小的时候训练还能继续下去:

但是,发现快到终点时突然间就发生了爆炸:因为这边走了很长一段路以后,这 gradient 算出来都很小,所以就累积了很小的 σ ,累积到一定地步以后,这个 step 就变很大,然后就爆走就喷出去了。喷出去以后没关系,是有办法修正回来的,因为喷出去以后就到了 gradient 比较大的地方,σ 又慢慢的变大 update 的步伐大小就慢慢的变小。
那解决这个问题也有对应的方法:learning rate scheduling ,learning rate scheduling 的意思就是说我们不要把 η 当一个常数,我们把它跟时间相关联。最常见的策略是 Learning Rate Decay,就是让学习率随着 update 不断降低。

刚才那个状况,如果加上 Learning Rate Decay 的话,我们就可以很平顺的走到终点,因为随着update,η 已经变得非常的小了,之前它本来想要左右乱喷,但是因为乘上这个非常小的 η,就停下来了,慢慢地走到终点。
还有一个 learning rate scheduling 方法叫做 warm up :让 learning rate 先变大后变小
