1. 前言
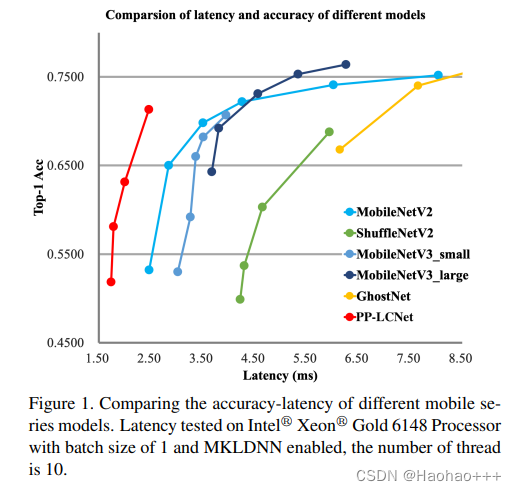
PPLCNet是百度团队结合Intel-CPU端侧推理特性而设计的轻量高性能网络PP-LCNet,所提方案在图像分类任务上取得了比ShuffleNetV2、MobileNetV2、MobileNetV3以及GhostNet更优的延迟-精度均衡。
论文提出了一种基于MKLDNN加速的轻量CPU模型PP-LCNet,它在多个任务上改善了轻量型模型的性能。
如下图所示,在图像分类任务方面,所提PP-LCNet在推理延迟-精度均衡方面大幅优于ShuffleNetV2、MobileNetV2、MobileNetV3以及GhostNet。
2. PPLCNet介绍
网络结构整体如下图所示。
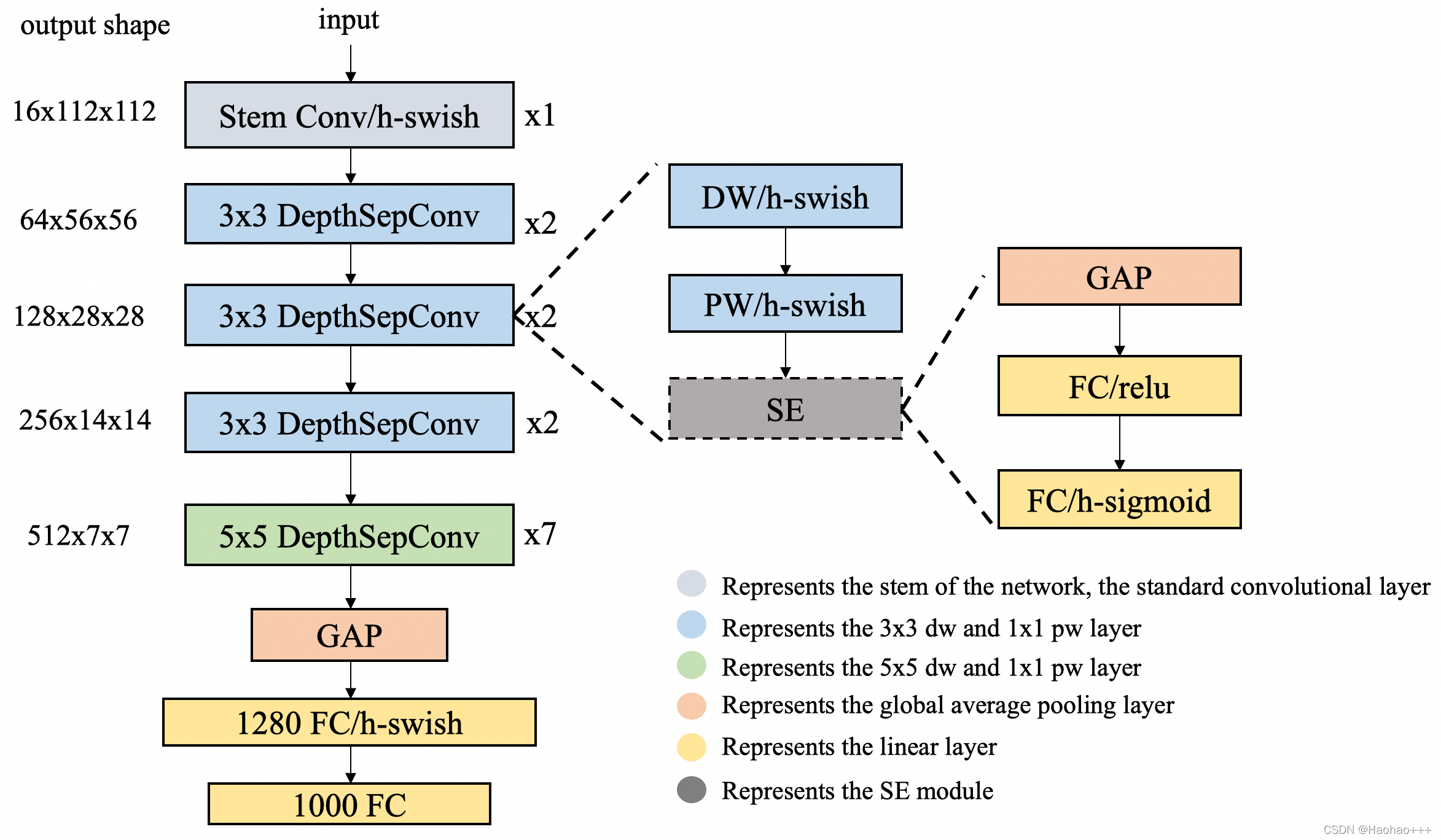
1. 模块
使用了类似MobileNetV1中的深度可分离卷积作为基础,通过堆叠模块构建了一个类似MobileNetV1的BaseNet,然后组合BaseNet与某些现有技术构建了一种更强力网络PP-LCNet。
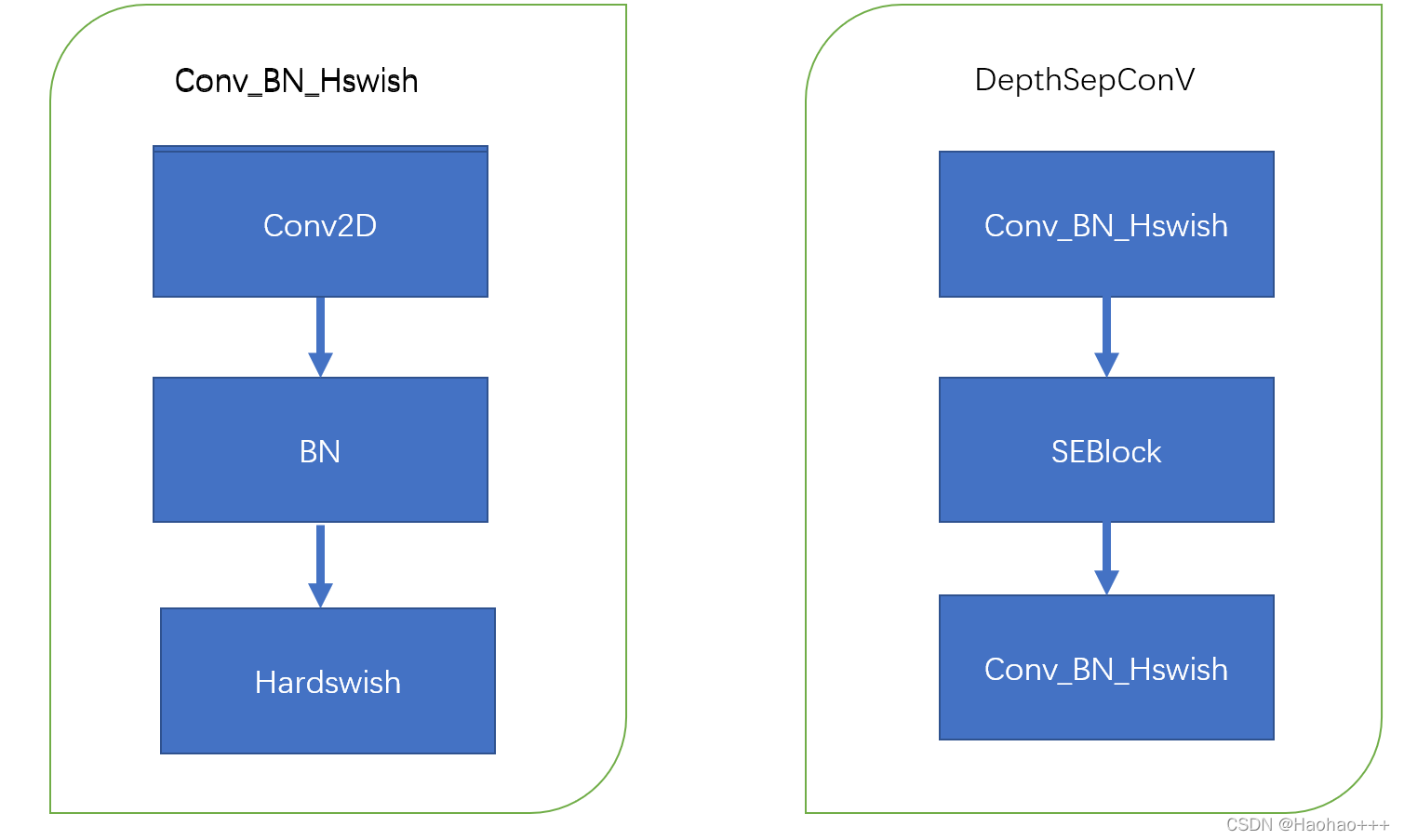
结构图如下:
左图是卷积+标准化+激活函数,右图是PPLCNet中的基础模块,我是根据源代码中画的图,源代码中是先卷积+SE模块+卷积。
def DethSepConv(x, filter,kernel_size ,stride, use_se=False):
x = Conv2D(filters=x.shape[-1], kernel_size=kernel_size, strides=stride, padding='same',
groups=x.shape[-1], use_bias=False)(x)
x = BatchNormalization()(x)
x = Activation(hard_swich)(x)
if use_se:
x = SE_block(x)
x = Conv2D(filters=filter, kernel_size=1, strides=1, padding='same',
use_bias=False)(x)
x = BatchNormalization()(x)
x = Activation(hard_swich)(x)
return x
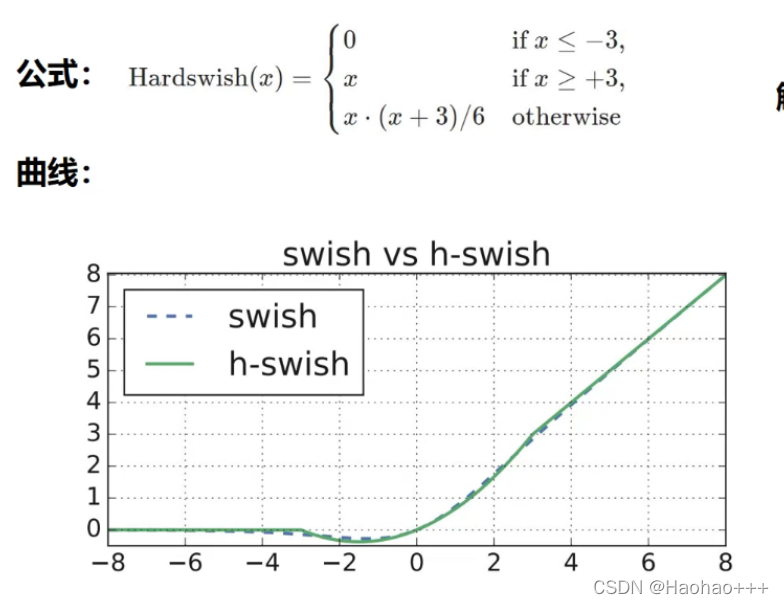
2. 激活函数的使用
自从卷积神经网络使用了 ReLU 激活函数后,网络性能得到了大幅度提升,近些年 ReLU 激活函数的变体也相继出现,如 Leaky-ReLU、P-ReLU、ELU 等,2017 年,谷歌大脑团队通过搜索的方式得到了 swish 激活函数,该激活函数在轻量级网络上表现优异,在 2019 年,MobileNetV3 的作者将该激活函数进一步优化为 H-Swish,该激活函数去除了指数运算,速度更快,网络精度几乎不受影响,也经过很多实验发现该激活函数在轻量级网络上有优异的表现。所以在 PP-LCNet 中,选用了该激活函数。
def hard_swich(x):
return x * K.relu(x + 3.0, max_value=6.0) / 6.0
3. SE 模块
SE模块使用的激活函数ReLU和H-sigmoid。代码实现如下:
def SE_block(x_0, r = 4):
channels = x_0.shape[-1]
x = GlobalAveragePooling2D()(x_0)
# (?, ?) -> (?, 1, 1, ?)
x = x[:, None, None, :]
# 用2个1x1卷积代替全连接
x = Conv2D(filters=channels//r, kernel_size=1, strides=1)(x)
x = Activation('relu')(x)
x = Conv2D(filters=channels, kernel_size=1, strides=1)(x)
x = Activation(hard_sigmoid)(x)
x = Multiply()([x_0, x])
return x
3. 合适的位置添加更大的卷积核
通过实验总结了一些更大的卷积核在不同位置的作用,类似 SE 模块的位置,更大的卷积核在网络的中后部作用更明显,所以在网络的后部会使用很多5x5的卷积核。
4. GAP 后使用更大的 1x1 卷积层
在 GoogLeNet 之后,GAP(Global-Average-Pooling)后往往直接接分类层,但是在轻量级网络中,这样会导致 GAP 后提取的特征没有得到进一步的融合和加工。如果在此后使用一个更大的 1x1 卷积层(等同于 FC 层),GAP 后的特征便不会直接经过分类层,而是先进行了融合,并将融合的特征进行分类。这样可以在不影响模型推理速度的同时大大提升准确率。
3. 整体代码:
参考源码:https://github.com/PaddlePaddle/PaddleClas/blob/1358e3f647e12b9ee6c5d6450291983b2d5ac382/ppcls/arch/backbone/legendary_models/pp_lcnet.py
此代码实在gpu上训练的。
import tensorflow as tf
from tensorflow.keras import backend as K
from tensorflow.keras.layers import (
Layer, GlobalAveragePooling2D, Conv2D, Activation, Multiply,
BatchNormalization, Dropout, Dense, Flatten, Input, Reshape
)
from tensorflow.keras.models import Model
from tensorflow.keras.activations import hard_sigmoid
import numpy as np
# 保证特征层为8得倍数
def _make_divisible(v, divisor=8, min_value=None):
if min_value is None:
min_value = divisor
new_v = max(min_value, int(v + divisor / 2) // divisor * divisor)
if new_v < 0.9 * v:
new_v += divisor
return new_v
def hard_swich(x):
return x * K.relu(x + 3.0, max_value=6.0) / 6.0
def SE_block(x_0, r = 4):
channels = x_0.shape[-1]
x = GlobalAveragePooling2D()(x_0)
# (?, ?) -> (?, 1, 1, ?)
x = x[:, None, None, :]
# 用2个1x1卷积代替全连接
x = Conv2D(filters=channels//r, kernel_size=1, strides=1)(x)
x = Activation('relu')(x)
x = Conv2D(filters=channels, kernel_size=1, strides=1)(x)
x = Activation(hard_sigmoid)(x)
x = Multiply()([x_0, x])
return x
def DethSepConv(x, filter,kernel_size ,stride, use_se=False):
x = Conv2D(filters=x.shape[-1], kernel_size=kernel_size, strides=stride, padding='same',
groups=x.shape[-1], use_bias=False)(x)
x = BatchNormalization()(x)
x = Activation(hard_swich)(x)
if use_se:
x = SE_block(x)
x = Conv2D(filters=filter, kernel_size=1, strides=1, padding='same',
use_bias=False)(x)
x = BatchNormalization()(x)
x = Activation(hard_swich)(x)
return x
def PP_LCNet(inputs, classes, dropout=0.2, scale=1.0):
x = Conv2D(filters=_make_divisible(16*scale), kernel_size=3, strides=2, padding='same',use_bias=False)(inputs)
x = BatchNormalization()(x)
x = Activation(hard_swich)(x)
x = DethSepConv(x, filter=_make_divisible(_make_divisible(scale*32)), kernel_size=3, stride=1, use_se=False)
print(x.shape,'1')
x = DethSepConv(x, filter=_make_divisible(_make_divisible(scale*64)), kernel_size=3, stride=2, use_se=False)
x = DethSepConv(x, filter=_make_divisible(_make_divisible(scale*64)), kernel_size=3, stride=1, use_se=False)
print(x.shape,'2')
x = DethSepConv(x, filter=_make_divisible(_make_divisible(128*scale)), kernel_size=3, stride=2, use_se=False)
x = DethSepConv(x, filter=_make_divisible(_make_divisible(128*scale)), kernel_size=3, stride=1, use_se=False)
print(x.shape,'3')
x = DethSepConv(x, filter=_make_divisible(_make_divisible(256*scale)), kernel_size=3, stride=2, use_se=False)
x = DethSepConv(x, filter=_make_divisible(_make_divisible(256*scale)), kernel_size=5, stride=1, use_se=False)
x = DethSepConv(x, filter=_make_divisible(_make_divisible(256*scale)), kernel_size=5, stride=1, use_se=False)
x = DethSepConv(x, filter=_make_divisible(_make_divisible(256*scale)), kernel_size=5, stride=1, use_se=False)
x = DethSepConv(x, filter=_make_divisible(_make_divisible(256*scale)), kernel_size=5, stride=1, use_se=False)
x = DethSepConv(x, filter=_make_divisible(_make_divisible(256*scale)), kernel_size=5, stride=1, use_se=False)
print(x.shape,'4')
x = DethSepConv(x, filter=_make_divisible(_make_divisible(512*scale)), kernel_size=5, stride=2, use_se=True)
x = DethSepConv(x, filter=_make_divisible(_make_divisible(512*scale)), kernel_size=5, stride=1, use_se=True)
print(x.shape,'5')
x = GlobalAveragePooling2D()(x)
shape = (1, 1, x.shape[-1])
x = Reshape(shape)(x)
x = Conv2D(filters=1280, kernel_size=1, strides=1,padding='valid', use_bias=False)(x)
x = Activation(hard_swich)(x)
x = Dropout(rate=dropout)(x)
x = Flatten()(x)
x = Dense(classes, activation='softmax')(x)
return x
if __name__ == '__main__':
inputs = Input(shape=(224,224,3))
classes = 17
model = Model(inputs=inputs, outputs=PP_LCNet(inputs, classes))
model.summary()