
Greenplum是在开源PostgreSQL的基础上,采用MPP架构的关系型分布式数据库。Greenplum被业界认为是最快最具性价比的数据库,具有强大的大规模数据分析任务处理能力。
Greenplum采用Shared-Nothing架构,整个集群由多个数据节点(Segment sever)和控制节点(Master Server)组成,其中的每个数据节点上可以运行多个数据库。
简单来说,Shared-Nothing是一个分布式的架构,每个节点相对独立。在典型的Shared-Nothing中,每一个节点上所有的资源(CPU、内存、磁盘)都是独立的,每个节点都只有全部数据的一部分,也只能使用本节点的资源。
由于采用分布式架构,Greenplum 能够将查询并行化,以充分发挥集群的优势。Segment内部按照规则将数据组织在一起,有助于提高数据查询性能,利于数据仓库的维护工作。如下图所示,Greenplum数据库是由Master Server、Segment Server和Interconnect三部分组成,Master Server和Segment Server的互联通过Interconnect实现。
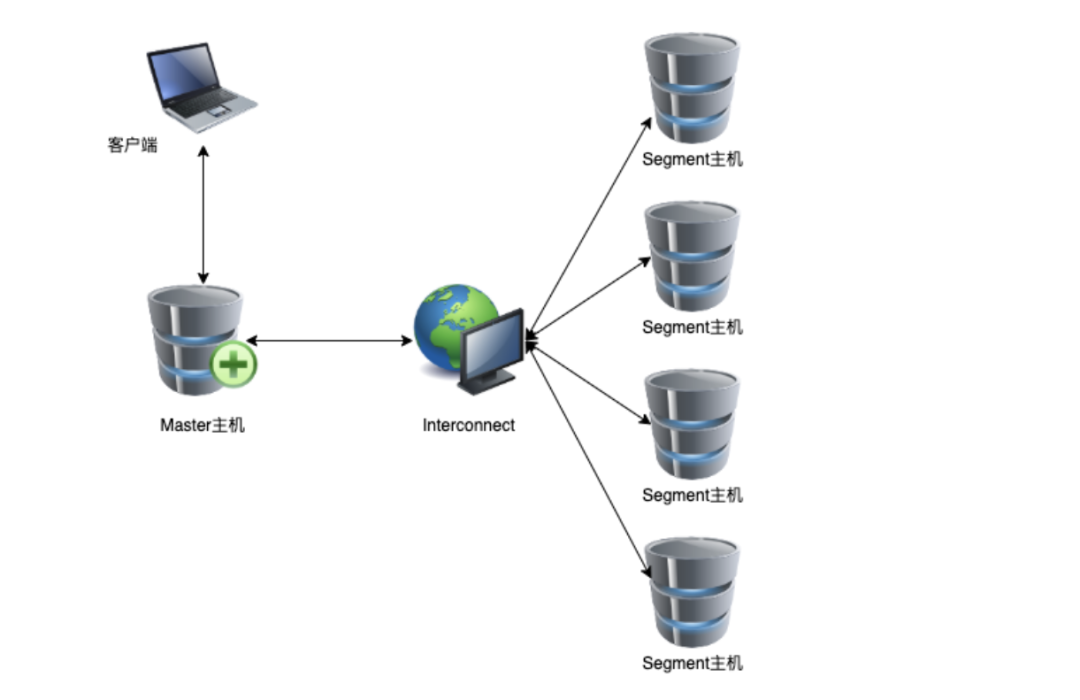
图1:Greenplum数据库架构示意
同时,为了最大限度地实现并行化处理,当节点间需要移动数据时,查询计划将被分割,而不同Segment间的数据移动就由Interconnect模块来执行。
在上次的直播中,我们为大家介绍了Greenplum-Interconnect模块技术特性和实现流程分析,以下内容根据直播文字整理而成。
Interconnect概要介绍
Interconnect是Greenplum数据库中负责不同节点进行内部数据传输的组件。Greenplum数据库有一种特有的执行算子Motion,负责查询处理在执行器节点之间交换数据,底层网络通信协议通过Interconnect实现。
Greenplum数据库架构中有一些重要的概念,包括查询调度器(Query Dispatcher,简称QD)、查询执行器(Query Executor,简称QE)、执行算子Motion等。

图2:Master-Segment查询执行调度架构示意
QD:是指Master节点上负责处理用户查询请求的进程。
QE:是指Segment上负责执行 QD 分发来的查询任务的进程。
通常,QD和QE之间有两种类型的网络连接:
-
libpq是基于TCP的控制流协议。QD通过libpq与各个QE间传输控制信息,包括发送查询计划、收集错误信息、处理取消操作等。libpq是PostgreSQL的标准协议,Greenplum对该协议进行了增强,譬如新增了‘M’消息类型 (QD 使用该消息发送查询计划给QE)等。
-
Interconnect数据流协议:QD和QE、QE和QE之间的表元组数据传输通过Interconnect实现,Greenplum有三种Interconnect实现方式,一种基于TCP协议,一种基于UDP协议,还有一种是Proxy协议。缺省方式为 UDP Interconnect连接方式。
Motion:PostgreSQL生成的查询计划只能在单节点上执行,Greenplum需要将查询计划并行化,以充分发挥集群的优势。为此,Greenplum引入Motion算子实现查询计划的并行化。Motion算子实现数据在不同节点间的传输,在Gang之间通过Interconnect进行数据重分布。
同时,Motion为其他算子隐藏了MPP架构和单机的不同,使得其他大多数算子都可以在集群或者单机上执行。每个Motion 算子都有发送方和接收方。
此外,Greenplum还对某些算子进行了分布式优化,譬如聚集。Motion算子对数据的重分布有gather、broadcast和redistribute三种操作,底层传输协议通过Interconnect实现。Interconnect是一个network abstraction layer,负责各节点之间的数据传输。
Greenplum是采用Shared-Nothing架构来存储数据的,按照某个字段哈希计算后打散到不同Segment节点上。当用到连接字段之类的操作时,由于这一字段的某一个值可能在不同Segment上面,所以需要在不同节点上对这一字段所有的值重新哈希,然后Segment间通过UDP的方式把这些数据互相发送到对应位置,聚集到各自哈希出的Segment上去形成一个临时的数据块以便后续的聚合操作。
Slice:为了在查询执行期间实现最大的并行度,Greenplum将查询计划的工作划分为slices。Slice是计划中可以独立进行处理的部分。查询计划会为motion生成slice,motion的每一侧都有一个slice。正是由于motion算子将查询计划分割为一个个slice,上一层slice对应的进程会读取下一层各个slice进程广播或重分布操作,然后进行计算。
Gang:属于同一个slice但是运行在不同的segment上的进程,称为Gang。如上图2所示,图中有两个QE节点,一个QD节点,QD节点被划分为三个slice。按照相同的slice在不同QE上面运行称一个组件的Gang,所以上图共有三个Gang。
Interconnect初始化流程
在做好基础准备工作之后,会有一系列处理函数,将某个节点或所有节点的数据收集上来。在数据传输的过程中,会有buffer管理的机制,在一定的时机,将buffer内的数据刷出,这种机制可以有效地降低存储和网络的开销。以下是初始化一些重要的数据结构说明。
1. Interconnect初始化核心结构
| Go
typedef enum GpVars_Interconnect_Type
{
Interconnect_TYPE_TCP = 0,
Interconnect_TYPE_UDPIFC,
Interconnect_TYPE_PROXY,
} GpVars_Interconnect_Type;
typedef struct ChunkTransportState
{
/* array of per-motion-node chunk transport state */
int size;//来自宏定义CTS_INITIAL_SIZE
ChunkTransportStateEntry *states;//上一个成员变量定义的size个数
ChunkTransportStateEntry
/* keeps track of if we've "activated" connections via SetupInterconnect().
*/
bool activated;
bool aggressiveRetry;
/* whether we've logged when network timeout happens */
bool networkTimeoutIsLogged;//缺省false,在ic_udp中才用到
bool teardownActive;
List *incompleteConns;
/* slice table stuff. */
struct SliceTable *sliceTable;
int sliceId;//当前执行slice的索引号
/* Estate pointer for this statement */
struct EState *estate;
/* Function pointers to our send/receive functions */
bool (*SendChunk)(struct ChunkTransportState *transportStates,
ChunkTransportStateEntry *pEntry, MotionConn *conn, TupleChunkListItem tcItem,
int16 motionId);
TupleChunkListItem (*RecvTupleChunkFrom)(struct ChunkTransportState
*transportStates, int16 motNodeID, int16 srcRoute);
TupleChunkListItem (*RecvTupleChunkFromAny)(struct ChunkTransportState
*transportStates, int16 motNodeID, int16 *srcRoute);
void (*doSendStopMessage)(struct ChunkTransportState *transportStates, int16
motNodeID);
void (*SendEos)(struct ChunkTransportState *transportStates, int motNodeID,
TupleChunkListItem tcItem);
/* ic_proxy backend context */
struct ICProxyBackendContext *proxyContext;
} ChunkTransportState; |
2. Interconnect初始化逻辑接口
初始化的流程会调用setup in Interconnect,然后根据数据类型选择连接协议。默认会选择UDP,用户也可以配置成TCP。在TCP的流程里面,会通过GUC宏来判断走纯TCP协议还是走proxy协议。
| Go
void
SetupInterconnect(EState *estate)
{
Interconnect_handle_t *h;
h = allocate_Interconnect_handle();
Assert(InterconnectContext != NULL);
oldContext = MemoryContextSwitchTo(InterconnectContext);
if (Gp_Interconnect_type == Interconnect_TYPE_UDPIFC)
SetupUDPIFCInterconnect(estate); #here udp初始化流程
else if (Gp_Interconnect_type == Interconnect_TYPE_TCP ||
Gp_Interconnect_type == Interconnect_TYPE_PROXY)
SetupTCPInterconnect(estate);#here tcp & proxy
else
elog(ERROR, "unsupported expected Interconnect type");
MemoryContextSwitchTo(oldContext);
h->Interconnect_context = estate->Interconnect_context;
}
SetupUDPIFCInterconnect_Internal初始化一些列相关结构,包括Interconnect_context初始化、以及transportStates->states成员createChunkTransportState的初始化,以及rx_buffer_queue相关成员的初始化。
/* rx_buffer_queue */
//缓冲区相关初始化重要参数
conn->pkt_q_capacity = Gp_Interconnect_queue_depth;
conn->pkt_q_size = 0;
conn->pkt_q_head = 0;
conn->pkt_q_tail = 0;
conn->pkt_q = (uint8 **) palloc0(conn->pkt_q_capacity * sizeof(uint8 *));
/* update the max buffer count of our rx buffer pool. */
rx_buffer_pool.maxCount += conn->pkt_q_capacity; |
3. Interconnect 初始化回调接口
当初始化的时候,接口回调函数都是统一的。当真正初始化执行时,会给上对应的函数支撑。
通过回调来对应处理函数,在PG里面是一种常见方式。比如,对于TCP的流程对应RecvTupleChunkFromTCP。
对于UDP的流程,对应TupleChunkFromUDP。相应函数的尾缀规律与TCP或是UDP对应。
| Go
TCP & proxy :
Interconnect_context->RecvTupleChunkFrom = RecvTupleChunkFromTCP;
Interconnect_context->RecvTupleChunkFromAny = RecvTupleChunkFromAnyTCP;
Interconnect_context->SendEos = SendEosTCP;
Interconnect_context->SendChunk = SendChunkTCP;
Interconnect_context->doSendStopMessage = doSendStopMessageTCP;
UDP:
Interconnect_context->RecvTupleChunkFrom = RecvTupleChunkFromUDPIFC;
Interconnect_context->RecvTupleChunkFromAny = RecvTupleChunkFromAnyUDPIFC;
Interconnect_context->SendEos = SendEosUDPIFC;
Interconnect_context->SendChunk = SendChunkUDPIFC;
Interconnect_context->doSendStopMessage = doSendStopMessageUDPIFC; |
Ic_udp流程分析
1. Ic_udp流程分析之缓冲区核心结构
| Go
MotionConn:
核心成员变量分析:
/* send side queue for packets to be sent */
ICBufferList sndQueue;
//buff来自conn->curBuff,间接来自snd_buffer_pool
ICBuffer *curBuff;
//snd_buffer_pool在motionconn初始化的时候,分别获取buffer,放在curBuff
uint8 *pBuff;
//pBuff初始化后指向其curBuff->pkt
/*
依赖aSlice->primaryProcesses获取进程proc结构进行初始化构造,进程id、IP、端口等信息
*/
struct icpkthdr conn_info;
//全局&ic_control_info.connHtab
struct CdbProcess *cdbProc;//来自aSlice->primaryProcesses
uint8 **pkt_q;
/*pkt_q是数组充当环形缓冲区,其中容量求模计算下标操作,Rx线程接收的数据包pkt放置在conn->pkt_q[pos] = (uint8 *) pkt中。而IcBuffer中的pkt赋值给motioncon中的pBuff,而pBuff又会在调用prepareRxConnForRead时,被赋值pkt_q对应指针指向的数据区,conn->pBuff = conn->pkt_q[conn->pkt_q_head];从而形成数据链路关系。
*/
motion:
ICBufferList sndQueue、
ICBuffer *curBuff、
ICBufferList unackQueue、
uint8 *pBuff、
uint8 **pkt_q;
ICBuffer
pkt
static SendBufferPool snd_buffer_pool;
第一层:snd_buffer_pool在motionconn初始化的时候,分别获取buffer,放在curBuff,并初始化pBuff。
第二层:理解sndQueue逻辑
中转站,buff来自conn->curBuff,间接来自snd_buffer_pool
第三层:理解data buffer和 pkt_q
启用数据缓冲区:pkt_q是数组充当环形缓冲区,其中容量求模计算下标操作,Rx线程接收的数据包pkt放置在conn->pkt_q[pos] = (uint8 *) pkt中。
而IcBuffer中的pkt赋值给motioncon中的pBuff,而pBuff又会在调用prepareRxConnForRead时,被赋值pkt_q对应指针指向的数据区, conn->pBuff = conn->pkt_q[conn->pkt_q_head];从而形成数据链路关系。 |
2. Ic_udp流程分析之缓冲区流程分析
| Go
Ic_udp流程分析缓冲区初始化:
SetupUDPIFCInterconnect_Internal调用initSndBufferPool(&snd_buffer_pool)进行初始化。
Ic_udp流程分析缓冲获取:
调用接口getSndBuffer获取缓冲区buffer,在初始化流程SetupUDPIFCInterconnect_Internal->startOutgoingUDPConnections,为每个con获取一个buffer,并且填充MotionConn中的curBuff
static ICBuffer * getSndBuffer(MotionConn *conn)
Ic_udp流程分析缓冲释放:
通过调用icBufferListReturn接口,释放buffer进去snd_buffer_pool.freeList
static void
icBufferListReturn(ICBufferList *list, bool inExpirationQueue)
{
icBufferListAppend(&snd_buffer_pool.freeList, buf);# here 0
}
清理:cleanSndBufferPool(&snd_buffer_pool);上面释放回去后接着清理buff。
handleAckedPacket逻辑对于unackQueue也会出发释放。 |
Ic_Proxy流程分析
1. 简要介绍
TCP流程buf设计较为简单,在这里不做详细赘述。Proxy代理服务是基于TCP改造而来,主要用来应对在大规模集群里面网络连接数巨大的情况。
Ic_Proxy只需要一个网络连接在每两个网端之间,相比较于IC-Tcp 模式,它消耗的连接总量和端口更少。同时,与 IC-Udp模式相比,在高延迟网络具有更好的表现。
TCP是一种点对点的有连接传输协议,一个有N个QE节点的Motion的连接数是N^2,一个有k个Motion的查询将产生k*N^2个连接。
举例来讲,如果一个包含500个Segment的集群,运行一个包含10个Motion的查询,那么这个查询就需要建立10*500^2 = 2,500,000个TCP连接。即使不考虑最大连接数限制,建立如此多的TCP连接也是非常低效的。
Ic_Proxy是用LIBUV开发的,默认情况下禁用IC代理,我们可以使用./configure --enable-ic-proxy。
安装完成后,我们还需要设置ic代理网络,它完成了通过设置GUC。例如,如果集群具有一个主节点、一个备用主节点、一个主分段和一个镜像分段, 我们可以像下面这样设置它:
| Go
gp_Interconnect_proxy_addresses
gpconfig --skipvalidation -c gp_Interconnect_proxy_addresses -v "'1:-1:localhost:2000,2:0:localhost:2002,3:0:localhost:2003,4:-1:localhost:2001'" |
它包含所有主服务器、备用服务器、以及主服务器和镜像服务器的信息段,语法如下:
dbid:segid:hostname:port[,dbid:segid:ip:port]。这里要注意,将值指定为单引号字符串很重要,否则将被解析为格式无效的中间体。
2. Ic_proxy逻辑连接
| Go
在 Ic-Tcp 模式下,QE 之间存在 TCP 连接(包括 QD),以一个收集动作举例:
┌ ┐
│ │ <===== [ QE1 ]
│ QD │
│ │ <===== [ QE2 ]
└ ┘
在 Ic-Udp 模式下,没有 TCP 连接,但仍有逻辑连接:如果两个QE相互通信,则存在逻辑连接:
┌ ┐
│ │ <----- [ QE1 ]
│ QD │
│ │ <----- [ QE2 ]
└ ┘
在 Ic_Proxy 模式下,我们仍然使用逻辑连接的概念:
┌ ┐ ┌ ┐
│ │ │ │ <====> [ proxy ] <~~~~> [ QE1 ]
│ QD │ <~~~~> │ proxy │
│ │ │ │ <====> [ proxy ] <~~~~> [ QE2 ]
└ ┘ └ ┘
在 N:1 集合运动中,有 N 个逻辑连接;
在N:N重新分配/广播运动中存在逻辑连接数N*N |
3. Ic_Proxy逻辑连接标识符
为了识别逻辑连接,我们需要知道谁是发送者,谁是接收者。在 Ic_Proxy 中,我们不区分逻辑的方向连接,我们使用名称本地和远程作为端点。终点至少由segindex和PID标识,因此逻辑连接可以通过以下方式标识:
seg1,p1->seg2,p2
然而,这还不足以区分不同查询中的子计划。我们还必须将发送方和接收方切片索引放入考虑:
slice[a->b] seg1,p1->seg2,p2
此外,考虑到后端进程可用于不同的查询会话及其生命周期不是严格同步的,我们还必须将命令 ID 放入标识符中:
cmd1,slice[a->b] seg1,p1->seg2,p2
出于调试目的,我们还将会话ID放在标识符中。在考虑镜像或备用时,我们必须意识到与 SEG1 主节点的连接和与 SEG1 镜像的连接不同,所以我们还需要将 dbid 放入标识符中:
cmd1,slice[a->b] seg1,dbid3,p1->seg2,dbid5,p2
Ic_Proxy数据转发流程介绍
数据转发是Ic_Proxy流程最复杂的部分,按照不同的流程,会产生三种转发类型:
第一种是Loopback,即循环本地;
第二种是proxy client,通过代理去client;
第三种是proxy to proxy,从一个代理发到另一个代理。
然后,按照上述的三种类型再调用对应的route,把数据转发出去,这样就形成了一个完整的数据转发流程。
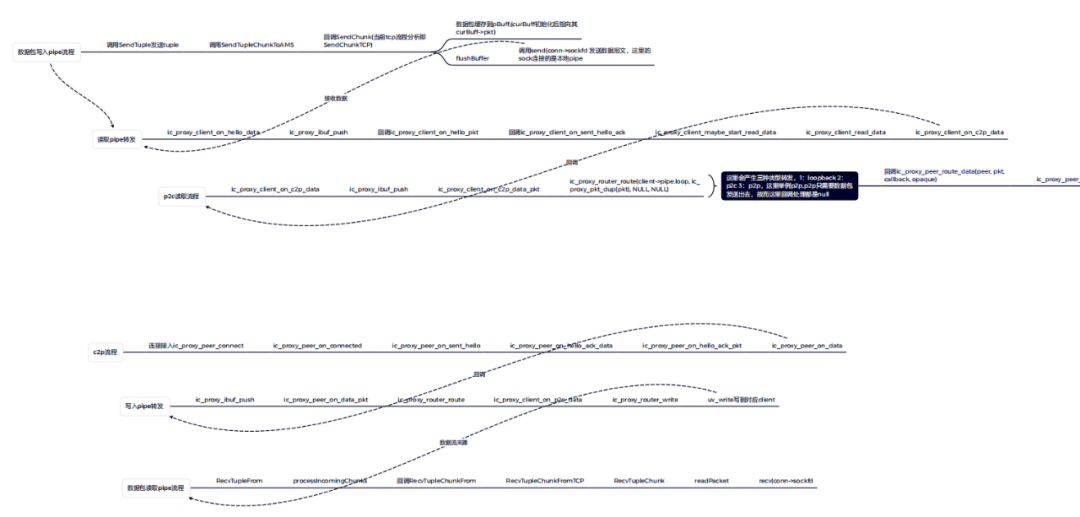
图3:Ic_proxy数据包转发处理流程图
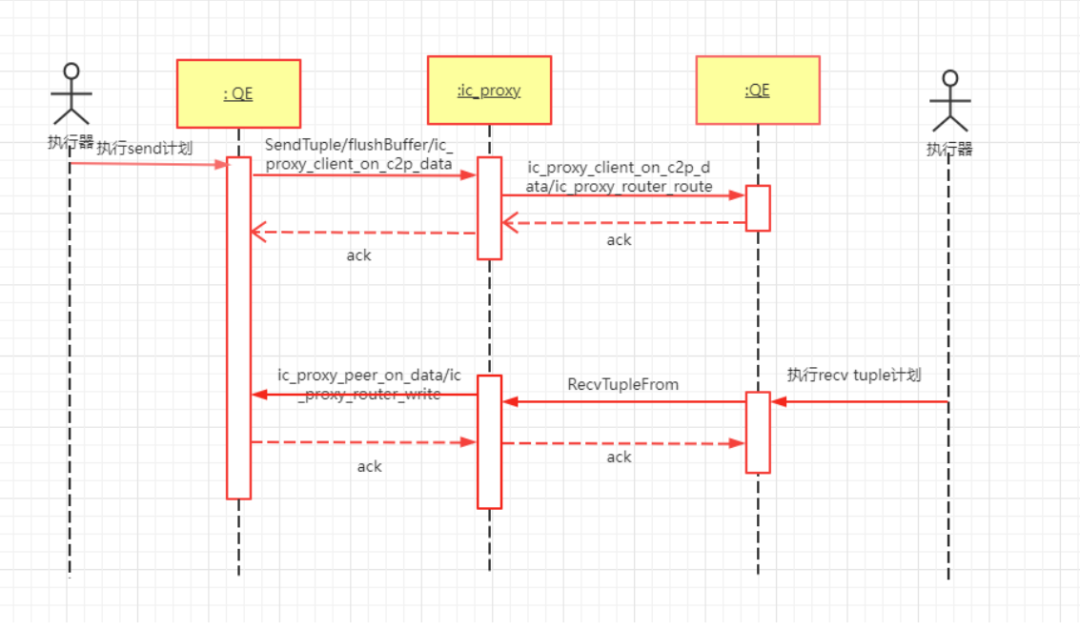
图4:Ic_Proxy流程时序图
今天我们为大家带来Greenplum-Interconnect模块的解析,希望能够帮助大家更好地理解模块的技术特性和实现处理流程。