
序言:
在Postgre数据库中,执行引擎作为一个连接查询引擎与存储引擎的中间部件,其主要的作用就是根据查询引擎传递的计划进行执行,获取数据。
Portal(门户),相当于执行引擎的入口。当一条SQL在经过查询引擎处理的词法、语法、查询优化、访问路径的创建后,都要经过Portal来决定执行器的路径,并将结果返回给用户,来完成数据的存取工作。
在近期的直播中,HashData内核研发工程师介绍了Portal基本理论和实现。以下内容根据直播文字整理。
导语:
Portal,也称为策略选择模块,这也代表了Portal最核心的功能。通常,Portal会根据SQL语句的类型,选择不同的执行模块(ProcessUtility、Executor等)。
SQL语句类型包括:可优化语句、数据定义语句。
-
可优化语句
包括DML(insert/update/select)等语句,这类语句特点是查询满足条件的元组,返回给用户或者元组操作后写入磁盘。之所以称其为可优化语句,是因为这类语句通常会被优化器进行重写与优化,从而加快查询速度。
-
数据定义语句
主要是功能性语句,例如:DDL(Create、Alter、Drop)、DCL(Grant、COMMIT、ROLLBACK)等。
下图为Portal在整个SQL执行过程中所承担的职责。图中上面SQL为可优化语句,下面为数据定义语句。
1.Portal内核揭秘:
简单来说,Portal负责驱动执行器,是执行器中的一部分。
1.1入口层

如上图所示,Portal通常分为两类:
QD执行会从exec_simple_query进入;
QE执行从exec_mpp_query进入;
然后统一由 portal 来根据语句类型进行决策,调用不同的执行器结构。
•ProcessUtilitySlow(事件触发类语句)
•ExecutorStart
初始化Estate、QueryDesc,调用InitPlan
•ExecutorRun
执行各个节点获取数据
•ExecutorFinish
执行ModifyTable节点
1.2 Portal层
首先初识Portal内部数据结构:

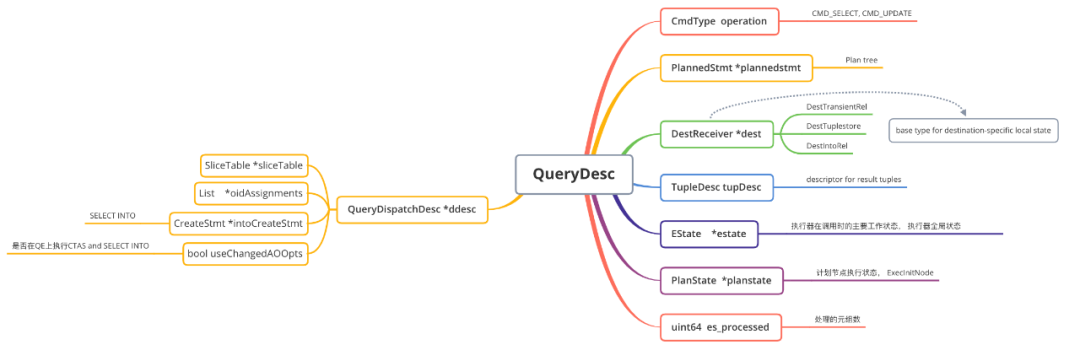
通过上面的整体结构图可以看出,Portal在执行引擎中起到了承上启下的作用:向上,它存储了优化器的相关信息;向下,它存储了执行引擎相关的一些结构。同时,Portal自身也存储了一些比较基础的结构,以及对应游标的结构。
•作为Portal的核心功能,Portal策略通常有五类:
1.PORTAL_ONE_SELECT
只包含一个SELECT查询。
| SQL |
2.PORTAL_ONE_RETURNING
包含一个INSERT/UPDATE/DELETE查询,且带RETURNING条件。
| SQL |
3.PORTAL_ONE_MOD_WITH
包含一个SELECT查询并且有修改的CTE。
| SQL |
需要注意,例如下面这个查询:
| SQL |
这个并不是PORTAL_ONE_MOD_WITH查询,而是PORTAL_MULTI_QUERY。
4.PORTAL_UTIL_SELECT
包含一个utility语句,且该语句执行会返回像SELECT那样有输出结果。
| SQL |
5.其他情况
例如:
PORTAL_MULTI_QUERY + PORTAL_MULTI_QUERY
| SQL |
•状态
○PORTAL_NEW
○PORTAL_DEFINED
○PORTAL_READY
○PORTAL_QUEUE
○PORTAL_ACTIVE
○PORTAL_DONE
○PORTAL_FAILED
这几个状态会在下面依次引入。
1.3 CreatePortal
创建一个新的Portal,传入参数均为: CreatePortal("", true, true),表示创建一个匿名的Portal,允许重复且重复后保持沉默。
CreatePortal逻辑:
| Plain Text |
1.根据传入的第一个参数name从哈希表中查找。
2.根据传入的第二个参数allowDup,如果第一步查找到,从哈希表中决定是否删除。如果true,则删除,否则报错。在哈希表中查找到Portal且允许重复的情况下,在QD节点上会根据第三个参数dupSilent决定是否输出告警信息。
3.创建一个新的Portal,并初始化相应参数。
执行完毕后,便创建好了一个状态为PORTAL_NEW的Portal。
1.4 PortalDefineQuery
定义Portal数据,包含了:查询语句sourceText、PlannedStmts、查询完成标记qc。
注意:QD上根据传递进来的stmt来设置nodeTag,但是QE上为T_Query,因为QE上不是parsed statement,所以不是 T_SelectStmt。
最终设置Portal状态为PORTAL_DEFINED。
1.5 PortalStart
准备好portal,主要有如下几步:
1.设置ddesc,该信息为QD到QE上的额外信息,QD上为NULL,QE上不为NULL。
2.设置全局参数,例如:当前活跃的Portal、resourceOwner、context。
3.设置Portal参数字段:PortalParams,同样QD上为NULL,QE上不为NULL。
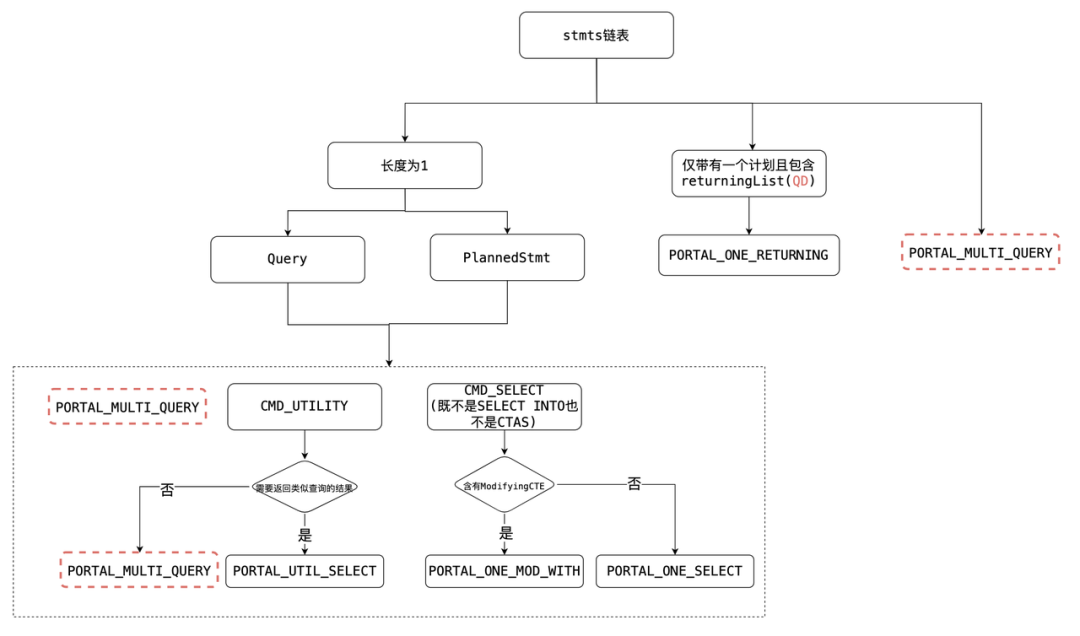
4.设置Portal策略(ChoosePortalStrategy)。
如下图所示:输入为查询计划链表,针对以下情况:
-
PORTAL_ONE_SELECT
-
PORTAL_ONE_MOD_WITH
-
PORTAL_UTIL_SELECT
-
PORTAL_ONE_RETURNING
首先判断是Query还是PlannedStmt,一般情况下的查询语句基本都是PlannedStmt。
对于像PREPARE st(int) as select * from t1之类utility语句,第一次调用ChoosePortalStrategy,返回PORTAL_MULTI_QUERY(命中PlannedStmt),第二次调用返回PORTAL_ONE_SELECT(命中Query)。
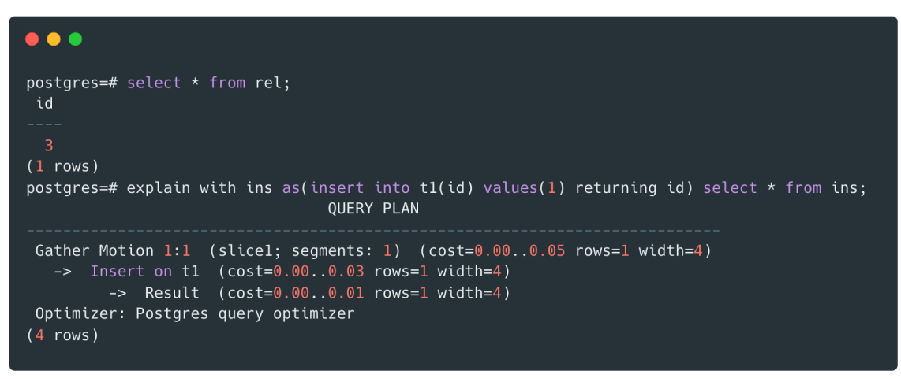
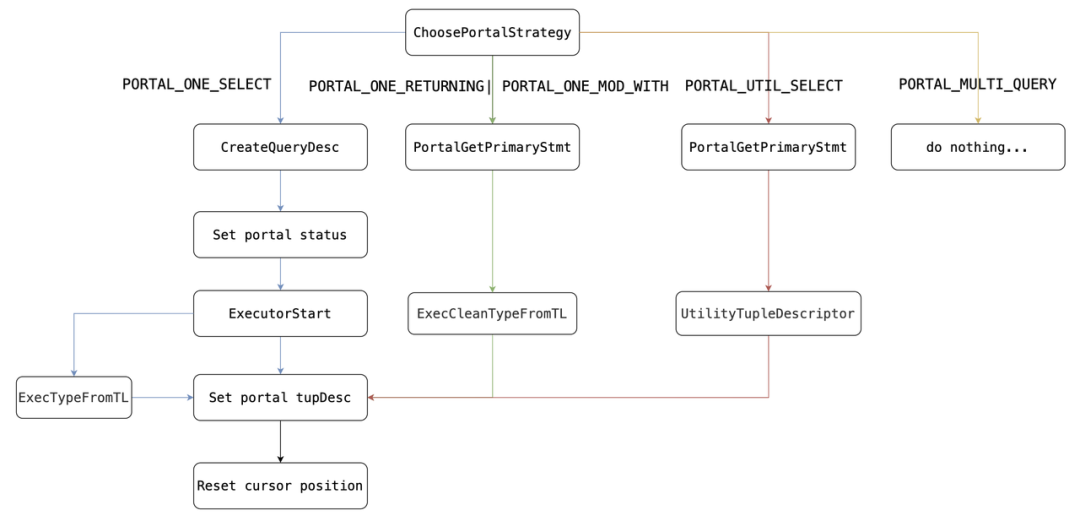
根据Portal策略初始化Portal,最重要的是初始化tupDesc与Cursor postion。
例如:"QUERY PLAN"、"t1_id、col1"就是tupDesc。
| SQL |
•不同tupleDesc函数区别
○ExecTypeFromTL
▪with resjunk column
○ExecCleanTypeFromTL
▪skip resjunk column
1.在执行Portal过程中发生异常,设置Portal的状态为PORTAL_FAILED;否则,下一步。
2.设置Portal状态为PORTAL_READY。
1.6 PortalRun
根据SQL的语句类型选择不同的执行路径,获取元组数据,完成Portal工作,运行完之后执行完毕,或者进行下一轮(READY,而非ACTIVE)。

Portal策略执行路径如下:
•PORTAL_ONE_SELECT
○set result = Portal->atEnd
•PORTAL_ONE_RETURNING|PORTAL_ONE_MOD_WITH|PORTAL_UTIL_SELECT
○填充holdStore(见下方)
○调用PortalRunSelect返回n行数据
▪获取时数据方向包含前进/后退
▪可以从holdStore中获取,也可以从ExectorRun中获取
○设置状态为PORTAL_READY
○设置是否完成运行标记为Portal->atEnd
•PORTAL_MULTI_QUERY
○调用PortalRunMulti
○设置状态为PORTAL_Done
○设置是否完成运行标记为true
此外,上述图中填充holdStore逻辑如下:
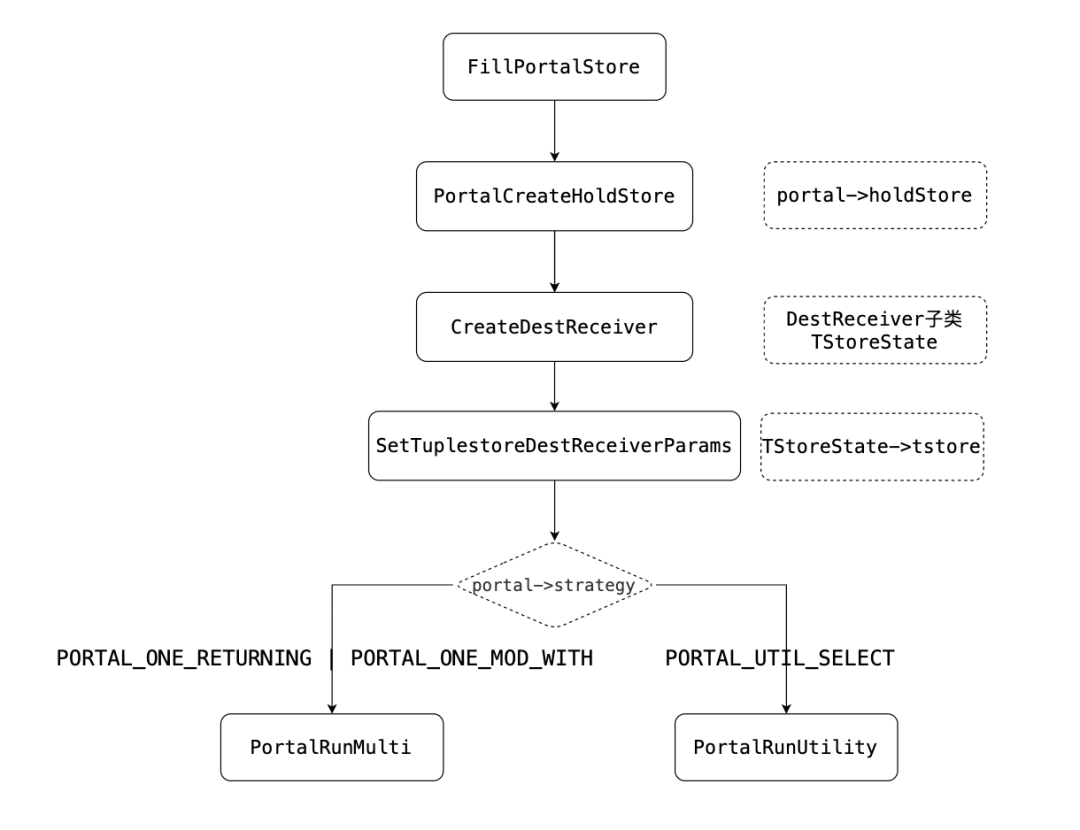
•调用PortalCreateHoldStore,填充portal->holdStore,然后通过工厂函数CreateDestReceiver构造DestReceiver(子类:TStoreState);
•根据Portal策略执行查询:
PORTAL_ONE_RETURNING
PORTAL_ONE_MOD_WITH
这两个策略调用PortalRunMulti
PORTAL_UTIL_SELECT调用PortalRunUtility。
○PORTAL_ONE_RETURNING
○PORTAL_ONE_MOD_WITH
▪PortalRunMulti
•utilityStmt
○PortalRunUtility
•not utilityStmt
○ProcessQuery
○PORTAL_UTIL_SELECT
▪PortalRunUtility
2.游标Cursor
2.1 打开游标
如果不想一次执行整个命令,可以设置一个封装该命令的游标(Cursor), 然后每次读取几行命令结果。
| SQL |
例如:
| SQL |
该命令运行机制为:
首先识别到是一个数据定义语句,便会调用ProcessUtility,随后解析从PlannedStmt中的utilityStmt识别出是一个T_DeclareCursorStmt节点,调用PerformCursorOpen执行Declare cursor命令。
PerformCursorOpen处理逻辑如下:
•query重写
•优化器优化,生成PlannedStmt
•创建Portal(名字为游标名),仅调用PortalStart
2.2 关闭游标
关闭游标,实际就是关闭Portal,调用PerformPortalClose。
如下两个操作:
| SQL |
如果传入的名字为空,则是CLOSE ALL关闭所有非活跃Portal,否则,只关闭指定的Portal(Cursor)。
2.3 FETCH or MOVE
FETCH与MOVE语法分别如下:
| SQL |
FETCH从游标中检索n行到目标中, 目标可以是一个行变量、记录变量、逗号分隔的普通变量列表, 就像SELECT INTO一样, 如果没有获取到数据,目标会设为NULL。
MOVE重新定位一个游标,而不需要检索任何数据,例如:一旦游标位置确定,则可以删除或更新行。
| SQL |
从实现层面两者都会进入到PerformPortalFetch,都被解析为FetchStmt,内部有个成员ismove决定是MOVE还是FETCH。
不管是哪个,都会指定Cursor的名字,有了这个名字,便知道了Portal,随后调用PortalRunFetch来获取结果。
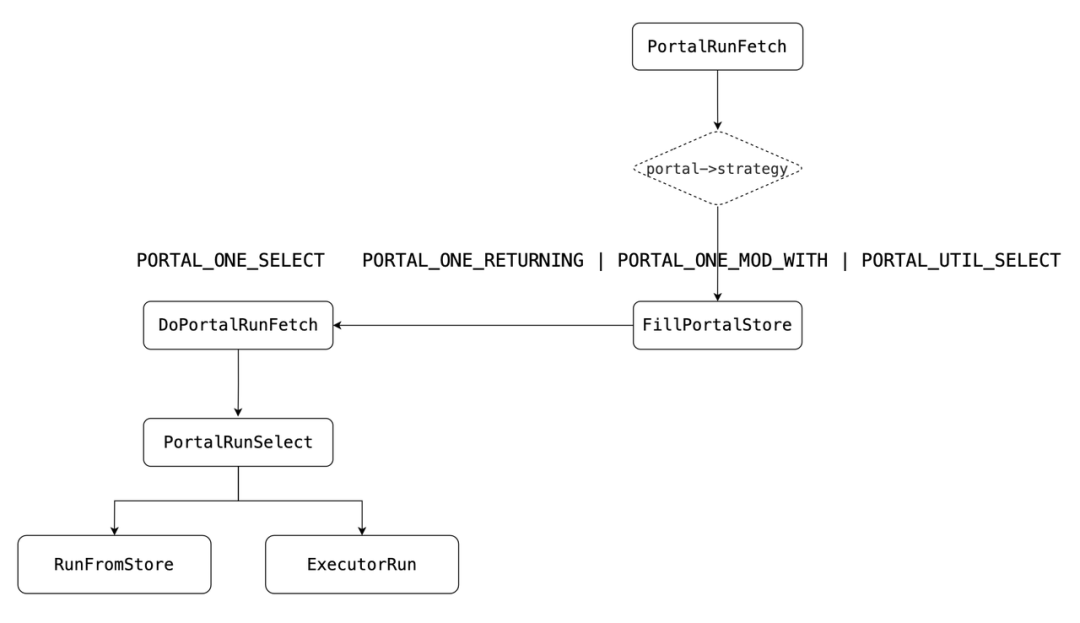
PortalRunFetch内部会像PortalRun运行一样,首先设置Portal状态为Active,随后根据策略选择不同的调用链。
•PORTAL_ONE_SELECT
○调用DoPortalRunFetch
•PORTAL_ONE_RETURNING|PORTAL_ONE_MOD_WITH|PORTAL_UTIL_SELECT
○首先判断portal内部是否有holdStore,如果没有会调用FillPortalStore,随后调用DoPortalRunFetch。
DoPortalRunFetch内部实现,会考虑传入的direction,决定是前向还是后向等不同方向的扫描,最后调用PortalRunSelect获取数据。注意:gpdb不支持backward scan,但是pg支持。
3.Portal内存管理
限制每个用户最大打开的Portal数量为16。
| Plain Text |
Portal内部封装了三个宏,分别是:
-
PortalHashTableLookup
-
PortalHashTableInsert
-
PortalHashTableDelete
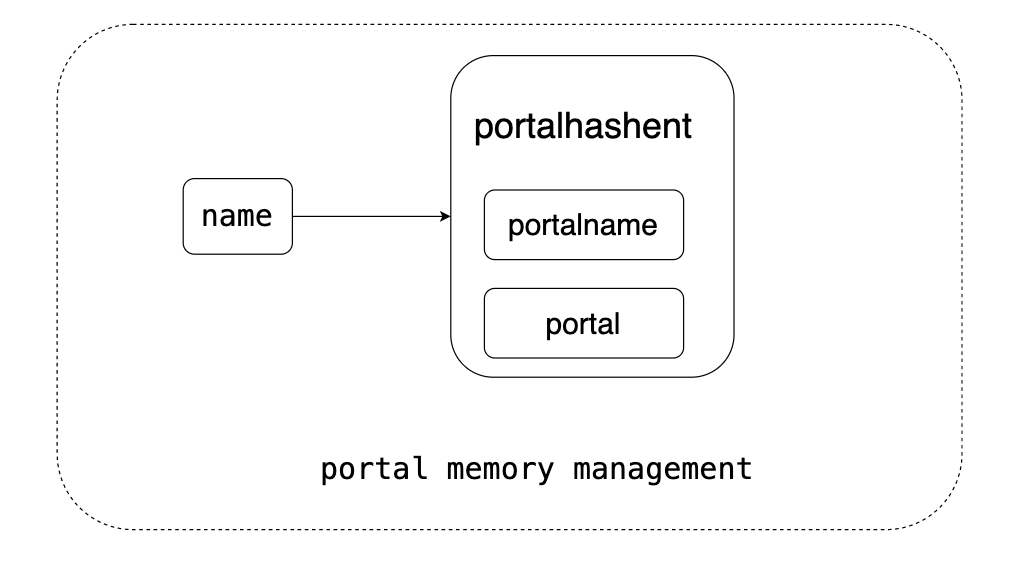
下图左侧是这三个宏的功能,右边是对外核心接口。

结语:
Portal作为执行引擎最基础的部分,其核心功能包括策略选择、启动执行器、设置游标。根据不同的SQL语句类型,Portal会选择不同的执行路径完成数据的存取工作。