如何查看执行计划
我们先创建三张表。一张课程表,一张老师表,一张老师联系方式表(没有任何索引)。
我们先创建三张表。一张课程表,一张老师表,一张老师联系方式表(没有任何索引)。
DROP TABLE
IF
EXISTS course;
CREATE TABLE `course` ( `cid` INT ( 3 ) DEFAULT NULL, `cname` VARCHAR ( 20 ) DEFAULT NULL, `tid` INT ( 3 ) DEFAULT NULL ) ENGINE = INNODB DEFAULT CHARSET = utf8mb4;
DROP TABLE
IF
EXISTS teacher;
CREATE TABLE `teacher` ( `tid` INT ( 3 ) DEFAULT NULL, `tname` VARCHAR ( 20 ) DEFAULT NULL, `tcid` INT ( 3 ) DEFAULT NULL ) ENGINE = INNODB DEFAULT CHARSET = utf8mb4;
DROP TABLE
IF
EXISTS teacher_contact;
CREATE TABLE `teacher_contact` ( `tcid` INT ( 3 ) DEFAULT NULL, `phone` VARCHAR ( 200 ) DEFAULT NULL ) ENGINE = INNODB DEFAULT CHARSET = utf8mb4;
INSERT INTO `course`
VALUES
( '1', 'mysql', '1' );
INSERT INTO `course`
VALUES
( '2', 'jvm', '1' );
INSERT INTO `course`
VALUES
( '3', 'juc', '2' );
INSERT INTO `course`
VALUES
( '4', 'spring', '3' );
INSERT INTO `teacher`
VALUES
( '1', 'bobo', '1' );
INSERT INTO `teacher`
VALUES
( '2', '老严', '2' );
INSERT INTO `teacher`
VALUES
( '3', 'dahai', '3' );
INSERT INTO `teacher_contact`
VALUES
( '1', '13688888888' );
INSERT INTO `teacher_contact`
VALUES
( '2', '18166669999' );
INSERT INTO `teacher_contact`
VALUES
( '3', '17722225555' );
explain 的结果有很多的字段,我们详细地分析一下。
先确认一下环境:
select version();
show variables like '%engine%';
1. id
id 是查询序列编号。
id 值不同
id 值不同的时候,先查询 id 值大的(先大后小)。
-- 查询 mysql 课程的老师手机号
EXPLAIN SELECT
tc.phone
FROM
teacher_contact tc
WHERE
tcid = ( SELECT tcid FROM teacher t WHERE t.tid = ( SELECT c.tid FROM course c WHERE c.cname = 'mysql' ) );
查询顺序:course c——teacher t——teacher_contact tc。

先查课程表,再查老师表,最后查老师联系方式表。子查询只能以这种方式进行,只有拿到内层的结果之后才能进行外层的查询。
id 值相同(从上往下)
-- 查询课程 ID 为 2,或者联系表 ID 为 3 的老师
EXPLAIN SELECT
t.tname,
c.cname,
tc.phone
FROM
teacher t,
course c,
teacher_contact tc
WHERE
t.tid = c.tid
AND t.tcid = tc.tcid
AND ( c.cid = 2 OR tc.tcid = 3 );

id 值相同时,表的查询顺序是
从上往下顺序执行。例如这次查询的 id 都是 1,查询的顺序是 teacher t(3 条)——course c(4 条)——teacher_contact tc(3 条)。
既有相同也有不同
如果 ID 有相同也有不同,就是 ID 不同的先大后小,ID 相同的从上往下。
2. select type 查询类型
这里并没有列举全部(其它:DEPENDENT UNION、DEPENDENT SUBQUERY、MATERIALIZED、UNCACHEABLE SUBQUERY、UNCACHEABLE UNION)。
下面列举了一些常见的查询类型:
SIMPLE
简单查询,不包含子查询,不包含关联查询 union。
EXPLAIN SELECT * FROM teacher;

再看一个包含子查询的案例:
-- 查询 mysql 课程的老师手机号
EXPLAIN SELECT
tc.phone
FROM
teacher_contact tc
WHERE
tcid = ( SELECT tcid FROM teacher t WHERE t.tid = ( SELECT c.tid FROM course c WHERE c.cname = 'mysql' ) );

PRIMARY
子查询 SQL 语句中的主查询,也就是最外面的那层查询。
SUBQUERY
子查询中所有的内层查询都是 SUBQUERY 类型的。
DERIVED
衍生查询,表示在得到最终查询结果之前会用到临时表。例如:
-- 查询 ID 为 1 或 2 的老师教授的课程
EXPLAIN SELECT
cr.cname
FROM
( SELECT * FROM course WHERE tid = 1 UNION SELECT * FROM course WHERE tid = 2 ) cr;

对于关联查询,先执行右边的 table(UNION),再执行左边的 table,类型是DERIVED
UNION
用到了 UNION 查询。同上例。
UNION RESULT
主要是显示哪些表之间存在 UNION 查询。<union2,3>代表 id=2 和 id=3 的查询存在 UNION。同上例。
3. type 连接类型
https://dev.mysql.com/doc/refman/5.7/en/explain-output.html#explain-join-types
所有的连接类型中,上面的最好,越往下越差。
在常用的链接类型中:system > const > eq_ref > ref > range > index > all
这 里 并 没 有 列 举 全 部 ( 其 他 : fulltext 、 ref_or_null 、 index_merger 、unique_subquery、index_subquery)。
以上访问类型除了 all,都能用到索引。
const
主键索引或者唯一索引,只能查到一条数据的 SQL。
DROP TABLE
IF
EXISTS single_data;
CREATE TABLE single_data ( id INT ( 3 ) PRIMARY KEY, content VARCHAR ( 20 ) );
INSERT INTO single_data
VALUES
( 1, 'a' );
EXPLAIN SELECT
*
FROM
single_data a
WHERE
id = 1;
system
system 是 const 的一种特例,只有一行满足条件。例如:只有一条数据的系统表。
EXPLAIN SELECT * FROM mysql.proxies_priv;

eq_ref
通常出现在多表的 join 查询,表示对于前表的每一个结果,,都只能匹配到后表的一行结果。一般是唯一性索引的查询(UNIQUE 或 PRIMARY KEY)。
eq_ref 是除 const 之外最好的访问类型。
先删除 teacher 表中多余的数据,teacher_contact 有 3 条数据,teacher 表有 3条数据。
DELETE
FROM
teacher
WHERE
tid IN ( 4, 5, 6 );
COMMIT;
-- 备份
INSERT INTO `teacher`
VALUES
( 4, '老严', 4 );
INSERT INTO `teacher`
VALUES
( 5, 'bobo', 5 );
INSERT INTO `teacher`
VALUES
( 6, 'seven', 6 );
COMMIT;
为 teacher_contact 表的 tcid(第一个字段)创建主键索引。
-- ALTER TABLE teacher_contact DROP PRIMARY KEY;
ALTER TABLE teacher_contact ADD PRIMARY KEY(tcid);
为 teacher 表的 tcid(第三个字段)创建普通索引。
-- ALTER TABLE teacher DROP INDEX idx_tcid;
ALTER TABLE teacher ADD INDEX idx_tcid (tcid);
执行以下 SQL 语句:
select t.tcid from teacher t,teacher_contact tc where t.tcid = tc.tcid;
此时的执行计划(teacher_contact 表是 eq_ref):

小结:
以上三种 system,const,eq_ref,都是可遇而不可求的,基本上很难优化到这个状态。
ref
查询用到了非唯一性索引,或者关联操作只使用了索引的最左前缀。
例如:使用 tcid 上的普通索引查询:
explain SELECT * FROM teacher where tcid = 3;

range
索引范围扫描。
如果 where 后面是 between and 或 <或 > 或 >= 或 <=或 in 这些,type 类型就为 range。
不走索引一定是全表扫描(ALL),所以先加上普通索引。
-- ALTER TABLE teacher DROP INDEX idx_tid;
ALTER TABLE teacher ADD INDEX idx_tid (tid);
执行范围查询(字段上有普通索引):
EXPLAIN SELECT * FROM teacher t WHERE t.tid <3;
-- 或
EXPLAIN SELECT * FROM teacher t WHERE tid BETWEEN 1 AND 2;

IN 查询也是 range(字段有主键索引)
EXPLAIN SELECT * FROM teacher_contact t WHERE tcid in (1,2,3);
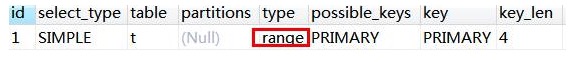
index
Full Index Scan,查询全部索引中的数据(比不走索引要快)。
EXPLAIN SELECT tid FROM teacher;

all
Full Table Scan,如果没有索引或者没有用到索引,type 就是 ALL。代表全表扫描。
小结:
一般来说,需要保证查询至少达到 range 级别,最好能达到 ref。
ALL(全表扫描)和 index(查询全部索引)都是需要优化的。
4. possible_key、key
可能用到的索引和实际用到的索引。如果是 NULL 就代表没有用到索引。
possible_key 可以有一个或者多个,可能用到索引不代表一定用到索引。
反过来,possible_key 为空,key 可能有值吗?
表上创建联合索引:
ALTER TABLE user_innodb DROP INDEX comidx_name_phone;
ALTER TABLE user_innodb add INDEX comidx_name_phone (name,phone);
执行计划(改成 select name 也能用到索引):
explain select phone from user_innodb where phone='126';

结论:是有可能的(这里是覆盖索引的情况)。
如果通过分析发现没有用到索引,就要检查 SQL 或者创建索引。
5. key_len
索引的长度(使用的字节数)。跟索引字段的类型、长度有关。
表上有联合索引:KEY
comidx_name_phone (name,phone)
explain select * from user_innodb where name ='jim';
6. rows
MySQL 认为扫描多少行才能返回请求的数据,是一个预估值。一般来说行数越少越好。
7. filtered
这个字段表示存储引擎返回的数据在 server 层过滤后,剩下多少满足查询的记录数量的比例,它是一个百分比。
8. ref
使用哪个列或者常数和索引一起从表中筛选数据。
9. Extra
执行计划给出的额外的信息说明。
using index
用到了覆盖索引,不需要回表。
EXPLAIN SELECT tid FROM teacher ;
using where
使用了 where 过滤,表示存储引擎返回的记录并不是所有的都满足查询条件,需要在 server 层进行过滤(跟是否使用索引没有关系)。
EXPLAIN select * from user_innodb where phone ='13866667777';

using filesort
不能使用索引来排序,用到了额外的排序(跟磁盘或文件没有关系)。需要优化。(复合索引的前提)
ALTER TABLE user_innodb DROP INDEX comidx_name_phone;
ALTER TABLE user_innodb add INDEX comidx_name_phone (name,phone);
EXPLAIN select * from user_innodb where name ='jim' order by id;
(order by id 引起)

using temporary
用到了临时表。例如(以下不是全部的情况):
1、distinct 非索引列
EXPLAIN select DISTINCT(tid) from teacher t;
2、group by 非索引列
EXPLAIN select tname from teacher group by tname;
3、使用 join 的时候,group 任意列
EXPLAIN select t.tid from teacher t join course c on t.tid = c.tid group by t.tid;
需要优化,例如创建复合索引。
总结一下:
模拟优化器执行 SQL 查询语句的过程,来知道 MySQL 是怎么处理一条 SQL 语句的。通过这种方式我们可以分析语句或者表的性能瓶颈。
分析出问题之后,就是对 SQL 语句的具体优化。