时间溯回,早在2017年,美图秀秀就曾引入人工智能美化人像而被谷歌誉为“最佳娱乐App”。智能技术奔腾发展,今年的AIGC技术可谓在各行各业大放异彩,从AI绘画、AI写作到AI配音,人工智能技术自动生成内容已经成为继UGC、PGC之后的一种新型内容生产方式。
在AI-GC的背后,AI生成工具在每个迭代阶段流出的产品,总能引发一波“人类下岗”热议。本文就从现阶段人们对AI内容生产的使用情况,聊聊AI让我们“慌”在哪里?
1、AI绘画:“驯服”之前,需要接受随机性?
现在,除了意间绘画小程序和draft.art网站,如美图秀秀、美颜相机这种扎根于美化人像的软件也立刻释放了AI绘画功能。
各个社交平台上涌现出大量使用AI绘制的影像。使用AI绘画,要输入一些限定语。很多网友表示,如果想让AI参考上传的照片/图片画出…不离谱的作品,需要赘述大量“关键词”。
例如:大师之作,极高分辨率,完成度极高,等等(先写20个试试效果),同时还要很清楚地描述参考图,在此基础上,还需接受随机性有概率得到一片混沌。
看到各大社交平台的晒图,有精美的,也不乏一不小心漏掉什么描述,让AI把情侣合影直接变成两位花臂大哥的、无中生“友”的。

大家很开心地看到AI将自己的爱宠拟绘成人,但看到自己精致形象照被AI画成牧羊犬、哈士奇,甚至靠背椅、墙纸贴画……虽无法欣然接受,但也纷纷晒到社交媒体中取乐一下——大家似乎很快习惯了AI绘画这个项目,默认在“驯服AI”之前需要接受AI的随机性。
2、AI建模:会让建模师下岗?
最近让建模师比较关注的AI工具当属英伟达(NVIDIA)推出的Magic3D,基于文本描述自动生成3D模型。据说只需要输入一段文字,AI就能生成出一只色泽、纹理、造型俱全的3D模型。
比如,“一只坐在睡莲上的蓝色箭毒蛙”就可以生成如下结果。

据悉,这一结果耗时大约40分钟(这个生成速度已经比之前的DreamFusion快2倍)。Magic3D还可以执行基于提示的3D网格编辑,只需要修改文字提示,就能够立即生成新的3D模型。
看到这个最终成品,各位模型师朋友是不是松了口气?虽说模型特征算得上有模有样,不过这个小青蛙的样子依然带有随机性。事实就是如此:
如果没有限定词,AI生成的模型随机性会更大;如果增加多个限定词,那么随机性堆积出的事物会与你想要设计的目标相去更远。
所以说至少目前,各个领域中依然需要能够“指哪打哪”的优秀设计师。
有关Magic3D,另一个进步点是质量。据说,Magic3D使用监督方法可合成8倍高分辨率的3D内容。具体来说普通的用户朋友有可能不太好理解,Magic3D用一种“从粗到精”的优化方法,使用多种不同分辨率下的多个扩散先验来优化3D表征,从而生成视图一致的集合形状及高分辨率细节,以生成高保真的3D内容,同时很容易在主流的图形软件中导入和可视化。
可是,问题也来了,AI生成的小青蛙最多能代表存在这样的物种,可是并不存在这样一只小蛙,对于现实生活中并不存在的客观事物,怎样才算是“高保真”呢?
3、什么是真正的高保真三维模型?AI建模还有哪些必经之路?
截至目前,AI绘画、AI建模做的都是人类做过的事情,我们就深入说说3D建模。
我们经常提到的建模有三种:数学建模、实景建模、原生建模。数学模型不是我们要讨论的事情,而另外两种,实景建模基于现实生活中已经存在的物品,逆向工程实现三维数字化,作为模型使用的时候要求的是尺寸颜色甚至质感的高度还原;原生建模是创造现实生活中尚不存在事物,上文中的小青蛙是本不存在的,还有就是从零开始设计各种物品也算。
而这两种模型结果最终的使用方向,无外乎两种:用在现实世界中;用在虚拟空间中。(如下图所示,三维设计涉及人们生活中的方方面面)
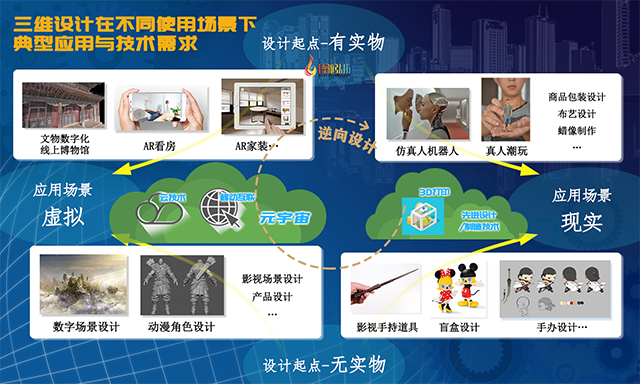
最终使用在现实生活中的三维模型,例如造车、玩具设计,最终都要通过3D打印或者批量生产做出实实在在的物品;用在虚拟空间中的模型,也与近两年比较火的元宇宙话题密不可分,比方说商品的网页展示、动画人物设计。 要说二者区别,例如在影视领域,演员手持的道具就是需要3D打印出来的;角色背后的现实生活中完全不存在的场景,就只需出现在虚拟空间中。当然如果说要开一个影片发布会,现场需要通过实景还原出经典场景,这也需要制作出实际物品。 既然制作3D模型的起点和最终使用场景各不相同,那么就可以有不同的方法来提升各自的效率。
在无实物领域,大家看到了,AI可以制作一个没有角色设定、没有目标的小青蛙,但如果你想用这样的AI替代从绘画到模型的过程是不现实的。
例如,动画作品《哈尔的移动城堡》。

动画中的城堡并不是标准意义的西方古堡,更像一个把人类起居驼在了身上的昆虫。假设已经还原了内部客厅、壁炉、浴室、卧室等房间在空间上与外观的一一对应,并且让AI事先学习“移动城堡”的建筑原型,但是让还在学习理解客观事物的AI接受这个“城堡”是靠一团有意志的火焰来驱动,并且拥有细细的腿脚,是不是有点勉为其难?
同时,现在的AI只是单一领域的工具,例如城堡内部在搬家后的几次结构变化就依然需要人工配置才能体现出作者与导演本身的设计,视情况可能需要大量的人工限定和人工操作。所以说,让3D建模AI在一些领域可控到可以实现创作者原本意图还有很长的路要走(目测跨界喂养,需要大量数据)。
而如果从实物出发去制作模型,因为不需要手绘技能,相对来说更容易让无基础的人来上手。
我们知道,华为推出了建模服务,将AI建模体验带给了非专业的普通用户(华为用户)。苹果公司也在pro系手机/平板中内置LiDAR激光雷达。不过,由于系统的原因,得到的模型尚不能直接以文件的形式导出使用。那这是不是太遗憾了?连博雅仔都想说一句不以导出使用为目的的三维建模都是浪费感情!
如果是这样,建议大家试试易模,研发团队基于在视觉AI领域20多年的积累,设计了这款泛在于Android与iOS系统的移动端轻量化3D建模应用,内置模型编辑功能,让任何人都可以在手机端触屏编辑3D模型,还提供多种文件导出方式和格式,满足将模型导出至标准图形软件二次设计的需求,让专业用户三维处理效率更高,让非专业的普通手机用户均可快速上手体验一键式智能三维创作。

易模,更快更好地创作真正的高保真3D模型
易模拥有五种建模模式(场景/主体/人脸/人像/器物),均为一键拍摄采样+AI建模模式。
用户可上传满足条件的照片组或视频进行建模,也可以直接使用易模拍摄实物进行建模。其中的器物模式可制作无底面的模型或者有底的全息3D模型,还有不同拍摄采样方法以满足不同场景下的文件需求、得到更高标准的三维模型。
易模生成的模型均是根据拍摄到的影像来生成的,AI所见,即为模型所得。模型1:1依托实物而生,颜色根据实拍获得,贴图分辨率根据影像数据决定,易模App真正做到实物尺寸可量测、实现真正意义的高保真。
团队基于视觉AI技术,将专业领域实景影像的图像精密解算过程(遥感测绘领域算法)跨界研发,开发智能算法,让手机用户可在手机端完成三维建模、模型编辑、模型分享、多格式导出,实现3D创作的普及化、便捷化、高效化。
说到高效,很多人关注建模时间。前文提到,Magic3D生成一只小青蛙需要大约40分钟,已经比之前的DreamFusion快2倍,而易模拍摄建模,保守地说,最快出模时间可在5分钟以内,复杂实物也可在20分钟内完成轻量化建模。 相比国外技术与带有技术限制的主机厂商建模方法,易模是国内自主研发的完整、快捷、轻量化的手机端建模应用,横跨Android与iOS系统,最重要的是,随着与不同领域的易模用户的深入交流,目前已经迭代出包括.obj/ .stl/ .3mf等在内的10余种三维文件的通用格式及细分行业常用格式,核心算法经历了多次优化后,易模的建模操作已经越发宽容,对零基础用户更加友好,更加接近目标——使其满足人们对3D扫描的各类想象。
纵然原生领域的AI建模还有很长的路要走,但是依托实景的AI建模已经在3D打印、工业设计、真人手办、元宇宙相关等各个领域迎来突出表现。