正则化(regularization),是指在线性代数理论中,不适定问题通常是由一组线性代数方程定义的,而且这组方程组通常来源于有着很大的条件数的不适定反问题。大条件数意味着舍入误差或其它误差会严重地影响问题的结果。
通俗定义:就是给平面上不可约代数曲线以某种形式的全纯参数表示。
主要解决的问题
1、正则化就是对最小化经验误差函数加上约束(比如在分类损失函数中,交叉熵后面的那一项就是约束项,也就是正则),这样的约束可以解释为先验知识(正则化参数等价于参数引入先验分布:也就是说约束中的参数服从某个已知分布,这就是先验知识)。约束有引导作用,在优化误差函数时倾向于选择满足约束的梯度减小的方向,使最终的解倾向于符合先验知识(如某一个分布)比如:常用的L-正则先验,表示原问题更可能是比较简单的,这样的优化倾向于产生参数值量级小的解,一般对应于稀疏参数的平滑解。
2、同时,正则化解决了逆问题的不适定性,产生的解是存在,唯一同时也依赖于数据的,噪声对不适定的影响就弱,解就不会过拟合,而且如果先验(正则化)合适,则解就倾向于是符合真解(更不会过拟合了),即使训练集中彼此间不相关的样本数很少。
上面这段话比较学术,通俗一点说,就是正则化可以防止过拟合,提高模型泛化能力。
什么是过拟合?
过拟合(overfitting)是指一个模型训练的非常准确,准确的容不得一粒沙子,只要你的数据有一丁点的变化,模型就认不出来该数据的类别,换句话说,模型在训练集上的准确率是100%,在测试集上的准确率是10%,差距非常大,此时说明模型过拟合了。
用函数图表示如下
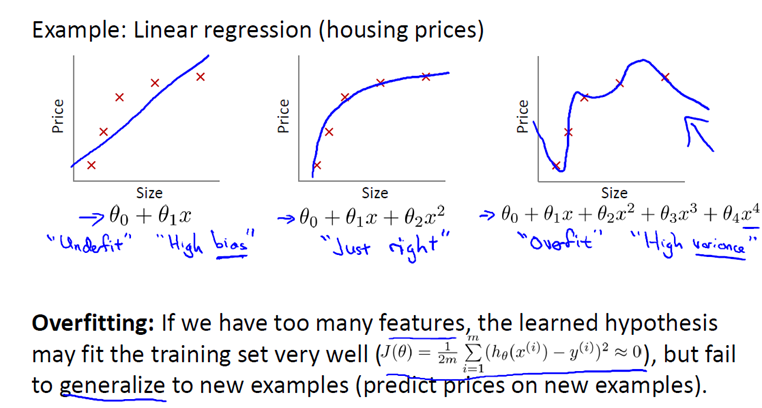
这是一个用线性回归做房价预测的例子。在第三幅图中,所有的点都在函数曲线上,这就是过拟合的表现,函数曲线在复杂,泛化能力差。又叫高方差(high variance),方差是样本与预测结果的差的平方和。如果我们拟合一个高阶多项式,那训练集中的所有数据都可以拟合在这个上述上,但是会面临函数太复杂,参数太多的问题,如果没有足够多的数据约束这个变量过多的模型,就会发生过拟合。
现在看第一幅图,根据图下面的函数,这是对数据做线性回归,显然线性回归不能很好的拟合数据,根据给出的数据,很明显,随着房子大小的增加,价格趋于稳定,而不是一直上升。因此线性回归不能很好的拟合数据,这种情况称为欠拟合(underfitting),又叫高偏差(high bias),偏差是样本与模型预测结果的平方差
看第二幅图,在线性函数后面加一个二次项,按照二次函数来拟合,事实证明这种函数拟合的效果很好。
过拟合问题通常发生在变量(特征)过多的时候,在训练集上准确率很高,在测试集上准确率非常低。
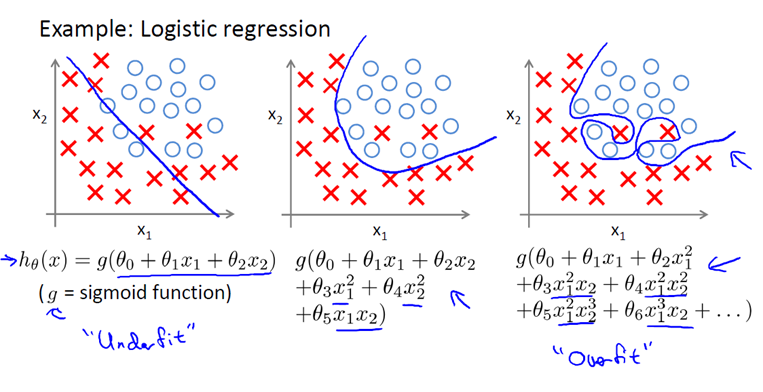
第三个图就是过拟合,函数曲线过于复杂,以至于模型没有泛化能力,不能适用于新数据。
如何处理过拟合?
当变量(特征)过多,同时训练数据较少时容易发生过拟合,因此,有两种办法解决过拟合:
一、减少特征(变量)数量
可以人工筛选出比较重要的某些特征(变量),当然,去掉某些特征,也会遗漏掉一些有用的信息,这个无法避免。
二、正则化
正则化中我们会保留所有的特征(变量),但是会减小变量的数量级(参数值的大小θ(j)),这个方法非常有效,当我们有很多特征变量时,每一个特征都会对结果产生影响,因此不希望把特征删掉,所以有了正则化的诞生。
如何应用正则化?什么叫正则化均值?
在上面的例子中,如果用一个二次函数来拟合数据,可以得到一个比较好的结果,如果用更高阶的函数取拟合数据,就会过拟合,训练的模型没有泛化能力。
下面来考虑下面的假设,我们想要加上惩罚项,使高阶项的参数θ3 和 θ4 足够小。

上式就是我们要训练的模型的优化目标,最小化该目标函数,因为我们没有减少特征(变量)的个数,所以目标函数还是一个复杂的高阶函数,此时我们在上式后面加上惩罚项,如下图:
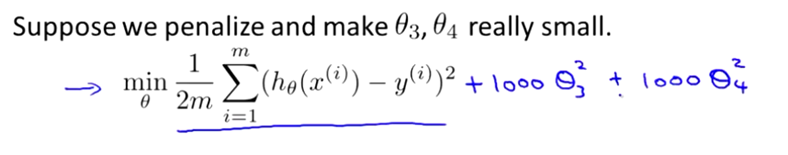
其中,θ3和θ4是在目标函数中存在的参数项,给这两个参数乘以一个很大的系数,构成新的目标函数,现在要最小化这个目标函数,只能是让新加的惩罚项无限接近于0,也就是让θ3和θ4无限接近于0。由于这两个参数在目标函数中对应的是高阶项,当他们接近于0时,高阶项也接近于0。这样就相当于把高阶项去掉了,将复杂的函数简化了,防止过拟合。
那这个让参数变小变相去掉某些特征和直接去掉某些特征的区别是什么呢?
首先人不可能非常精准的获得有用的特征,数据也不可能符合一个完美的函数,对于某些起到非常非常微小的作用的特征,直接去掉该特征会丢掉该特征的信息导致模型训练不准确,不丢掉该特征那这个特征对应的变量会导致模型很复杂,如果不加正则项(引导项)模型会以同样的维度训练每一个变量,高阶参数的取值范围是真个实数界的任意一个数,加入正则项(引导项)之后,相当于加入了一个约束条件,将高阶项的参数的取值范围限制在一个很小的范围内,使整个模型变相变成低阶模型,简化函数,同时保证不丢掉每一个特征(信息),就算是很小的值,毕竟不是0,还是会起一点作用的。
在上面的例子中,我们惩罚的只是 θ3 和 θ4 ,使这两个值均接近于零,从而我们得到了一个更简单的假设,实际上这个假设大抵上是一个二次函数。特征变量只有一个x
那如果给定的数据有100个特征{x1,x2,x3,…x100}来决定房价走势,又该怎么写呢?
有100个特征,每个特征都对应着一个参数θ,我们又不知道那些特征是高阶,那些特征是低阶,就不能去设定如θ3 和 θ4 这么具体。那这种情况如何确定正则项呢?一个简单的方法就是将所有的特征的参数都纳入正则的范围额不仅仅是高阶特征。缩小所有的参数值。
更一般地,这里给出了正规化背后的思路。这种思路就是,如果我们的参数值对应一个较小值的话(参数值比较小),那么往往我们会得到一个形式更简单的假设。
事实上,这些参数的值越小,通常对应于越光滑的曲线,函数的形式就越简单,因此,不容易发生过拟合问题。
顺便说一下,为什么参数是从1到n而不是从0到n呢,事实上这是一个约定俗成的惯例,即使从0开始差别也很小,就是习惯而已。
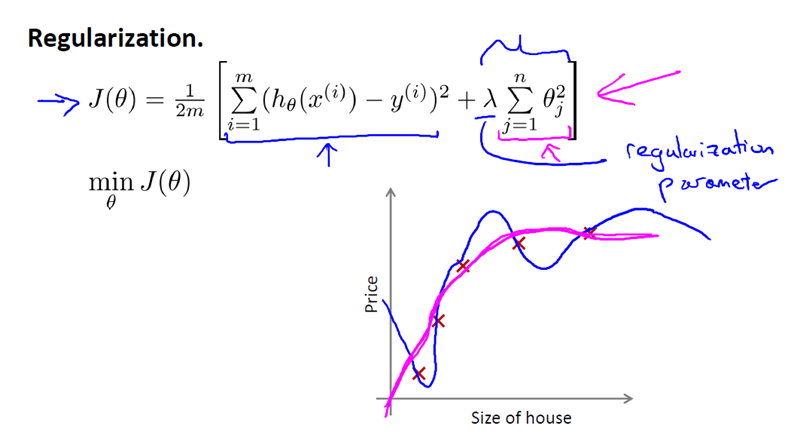
整个目标函数的后面这一项是正则化项,正则化项前面的系数λ叫正则化参数
正则化参数λ的目的就是控制两个不同目标之间的平衡,也就是控制第一项和第二项之间的平衡
第一个目标是训练模型使模型能很好的拟合给定数据,就是较好的训练第一项
第二个目标是我们想要参数保持一个较小的值,这个较小的值通过正则化来约束,是公式中的第二项。
λ这个正则化参数就是要要保证拟合数据和保持参数值较小这两者之间的平衡,从而来保证假设的形式简单,避免过拟合。
比如说我们的房价问题,之前用高阶多项式来拟合训练数据,得到的是以条弯弯曲曲的曲线,函数形式非常复杂,加入正则项之后,得到的是一个近似二次函数的曲线,形式简单了很多,但实际上他不是二次函数,只是相比弯弯曲曲的高阶多项式函数平滑了许多。
在上面的公式中,如果正则化参数λ被定义的很大,会发生什么情况呢?
看公式,如果λ很大,为了最小化目标函数,需要使正则化项最小,因为λ很大,必定要使θ很小,才能保证整个正则化项最小,考虑极端情况,λ非常大,那θ就无限趋近于0,那所有的特征项都会不起作用了,优化目标就会变成常数θ0,如下图:

如果我们这么做,那么就是我们的假设中相当于去掉了这些项,并且使我们只是留下了一个简单的假设,这个假设只能表明房屋价格等于 θ0 的值,那就是类似于拟合了一条水平直线,对于数据来说这就是一个欠拟合 (underfitting)。这种情况下这一假设它是条失败的直线,对于训练集来说这只是一条平滑直线,它没有任何趋势,它不会去趋向大部分训练样本的任何值。
这句话的另一种方式来表达就是这种假设有过于强烈的”偏见” 或者过高的偏差 (bais),认为预测的价格只是等于 θ0 。对于数据来说这只是一条水平线。
显然过大的正则化参数会使训练出来的模型欠拟合,换句话说,就是模型训练不出来,因为θ趋近于0时让所有的特征都失效了。
所以为了得到一个合适的模型需要选取合适的λ值。
好了,现在知道了过拟合和正则化的概念,那L1正则和L2正则有是怎么回事呢?他们和上面的正则化有什么区别呢?
首先来看L1正则和L2正则的定义:
L1正则是指目标函数中参数向量θ(在实际中θ是一个向量)的每一个元素的绝对值之和,通常表示为||θ||1
L2正则是指目标函数中参数向量θ(在实际中θ是一个向量)的各个元素的平方和再求平方根,通常表示为||θ||2
那L1正则和L2正则有什么作用呢?
官方说法:
L1正则化可以产生稀疏矩阵,即生成一个稀疏模型,可以用于特征选择
L2正则化可以防止模型过拟合,一定程度上,L1正则化也可以防止模型过拟合。
从上面的两句话可以看出L1防止过拟合的原理和L2防止过拟合的原理是不一样的,因为L1产生稀疏矩阵用于特征选择,所以它防止过拟合是通过丢掉一部分特征的办法实现的。
什么是稀疏矩阵?
稀疏矩阵是很多元素为0,只有少数元素非0的矩阵,用这个矩阵来选择特征就会使一些特征的稀系数为0从而将该特征变量变相删除,和上面的人工减少特征数来防止过拟合的原理一样。
现在知道了L1正则防止过拟合的原因,核心是L1正则可以产生一个稀疏矩阵,那这个稀疏矩阵是如何产生的呢?
来看L1正则化的目标函数

为了方便书写,我们把上面的目标函数简化为
其中正则项是L1正则,不是平方,是参数向量每一维的绝对值的和,J0就是原本要优化的目标函数。如果参数向量只有两维,那正则项就可以写为L=||θ1||+||θ2||,J0的等值线和L的函数图形如下图:

L=||θ1||+||θ2||的函数图形如图所示,可以想象,多维度的图形也是带棱角的图形且棱角出现在坐标轴上,J0的等值线与L的函数相交的点是整个目标函数取最小值的点,显然,J0与棱角的点(也就是坐标轴上的点)相交的概率比与线相交的概率要大很多,所以参数θ都是位于坐标轴上的,(θ1,θ2)=(0,θ2),所以就出现了很多元素为0的维度,构成了稀疏矩阵,这就是稀疏矩阵的来源。关键是L1正则化是维度的绝对值的和,绝对值画出来的图形是有很多点在坐标轴上的,这就是造成出现很多0元素的根源。
那L2正则化防止过拟合的原因是什么呢?
实际上,在我们上面解释什么是正则化举的例子就是L2正则,现在我们从数学图形的角度直观的解释一下其防止过拟合的原因,淡然主要是为了和L1正则化对比。
现在我们来看L2正则化的定义和公式,L2正则化是参数向量θ中每个维度的值的平方和,仍是以θ有两个维度为例,L2正则化表示为
J0和L的函数图如下:

显然,L函数是一个圆的函数公式,J0与L相交的点不在坐标轴上,这是与L1正则的区别。在这幅图上不容易看出L2防止过拟合的原因,还是通过函数公式解释比较清楚,也就是在介绍正则化时的解释,在此不赘述。
OK,到这里我们解释了过拟合,正则化,L1正则化,L2正则化的概念,原理与联系。
日常记录:
本意是想搞懂L1正则化与L2正则化的区别,没想到写了这么多,迁出这么多知识点,那就在写写这两个的区别
L1正则是由于正则函数的绝对值导致取到的点都在坐标轴上,导致产生了很多值为0的元素,从而产生稀疏矩阵,那元素0对应的特征就被变相舍弃了,从而减少了特征数,防止过拟合。
L2正则是将高阶多项式的高阶项的参数通过L2的约束减小高阶项参数的值来减少目标函数的复杂度,达到简化函数的目的,防止过拟合。