文章目录
一、perf 工具下载
-
系统级性能优化通常包括两个阶段:性能剖析(performance profiling)和代码优化。
-
性能剖析的目标是寻找性能瓶颈,查找引发性能问题的原因及热点代码。
-
代码优化的目标是针对具体性能问题而优化代码或编译选项,以改善软件性能。
-
在性能剖析阶段,需要借助于现有的profiling工具,如perf等。在代码优化阶段往往需要借助开发者的经验,编写简洁高效的代码,甚至在汇编级别合理使用各种指令,合理安排各种指令的执行顺序。
-
perf是一款Linux性能分析工具。Linux性能计数器是一个新的基于内核的子系统,它提供一个性能分析框架,比如硬件(CPU、PMU(Performance Monitoring Unit))功能和软件(软件计数器、tracepoint)功能。
-
通过perf,应用程序可以利用PMU、tracepoint和内核中的计数器来进行性能统计。它不但可以分析制定应用程序的性能问题(per thread),也可以用来分析内核的性能问题,当然也可以同事分析应用程序和内核,从而全面理解应用程序中的性能瓶颈。
-
使用perf,可以分析程序运行期间发生的硬件事件,比如instructions retired、processor clock cycles等;也可以分析软件时间,比如page fault和进程切换。
perf是一款综合性分析工具,大到系统全局性性能,再小到进程线程级别,甚至到函数及汇编级别。
perf工具
1.在centos7下离线安装
tar -xvf perf-5.9.0.tar.gz
cd perf-5.9.0
cd tools/perf/
make
sudo cp perf /usr/local/bin
其中安装会出现以下问题:
2.安装flex
Warning: Kernel ABI header at 'tools/include/uapi/drm/i915_drm.h' differs from latest version at 'include/uapi/drm/i915_drm.h'
Warning: Kernel ABI header at 'tools/include/uapi/linux/kvm.h' differs from latest version at 'include/uapi/linux/kvm.h'
Warning: Kernel ABI header at 'tools/include/uapi/linux/prctl.h' differs from latest version at 'include/uapi/linux/prctl.h'
Warning: Kernel ABI header at 'tools/arch/x86/include/asm/disabled-features.h' differs from latest version at 'arch/x86/include/asm/disabled-features.h'
Warning: Kernel ABI header at 'tools/arch/x86/include/asm/cpufeatures.h' differs from latest version at 'arch/x86/include/asm/cpufeatures.h'
Warning: Kernel ABI header at 'tools/arch/x86/include/uapi/asm/kvm.h' differs from latest version at 'arch/x86/include/uapi/asm/kvm.h'
Warning: Kernel ABI header at 'tools/arch/powerpc/include/uapi/asm/kvm.h' differs from latest version at 'arch/powerpc/include/uapi/asm/kvm.h'
Warning: Kernel ABI header at 'tools/arch/s390/include/uapi/asm/kvm.h' differs from latest version at 'arch/s390/include/uapi/asm/kvm.h'
Makefile.config:137: *** Error: flex is missing on this system, please install it. Stop.
Makefile.perf:203: recipe for target 'sub-make' failed
make[1]: *** [sub-make] Error 2
Makefile:69: recipe for target 'all' failed
make: *** [all] Error 2
flex如果不安装,后面在编译的时候,会出现信赖报错。
flex安装命令:
yum install flex -y
3.安装bison
bison如果没有安装,会报以下错误。
BUILD: Doing 'make -j4' parallel build
Warning: Kernel ABI header at 'tools/include/uapi/drm/i915_drm.h' differs from latest version at 'include/uapi/drm/i915_drm.h'
Warning: Kernel ABI header at 'tools/include/uapi/linux/kvm.h' differs from latest version at 'include/uapi/linux/kvm.h'
Warning: Kernel ABI header at 'tools/include/uapi/linux/prctl.h' differs from latest version at 'include/uapi/linux/prctl.h'
Warning: Kernel ABI header at 'tools/arch/x86/include/asm/disabled-features.h' differs from latest version at 'arch/x86/include/asm/disabled-features.h'
Warning: Kernel ABI header at 'tools/arch/x86/include/asm/cpufeatures.h' differs from latest version at 'arch/x86/include/asm/cpufeatures.h'
Warning: Kernel ABI header at 'tools/arch/x86/include/uapi/asm/kvm.h' differs from latest version at 'arch/x86/include/uapi/asm/kvm.h'
Warning: Kernel ABI header at 'tools/arch/powerpc/include/uapi/asm/kvm.h' differs from latest version at 'arch/powerpc/include/uapi/asm/kvm.h'
Warning: Kernel ABI header at 'tools/arch/s390/include/uapi/asm/kvm.h' differs from latest version at 'arch/s390/include/uapi/asm/kvm.h'
Makefile.config:141: *** Error: bison is missing on this system, please install it. Stop.
Makefile.perf:203: recipe for target 'sub-make' failed
make[1]: *** [sub-make] Error 2
Makefile:69: recipe for target 'all' failed
make: *** [all] Error 2
安装命令:
yum install bison -y
二、设置环境变量
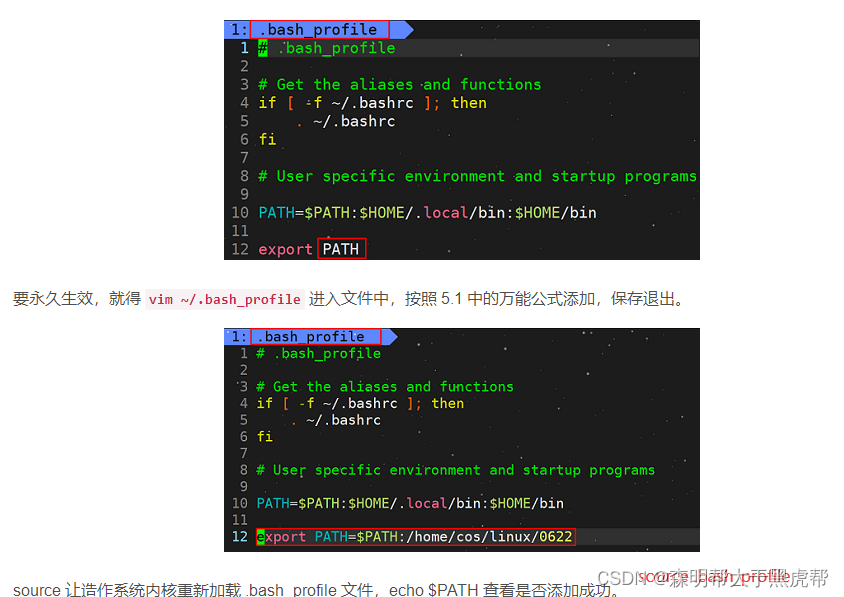
永久生效我们普通用户一般在 ~/.bashrc 或者 ~/.bash_profile 添加就可以了,不要往 /etc/bashrc 里添加。注意:以 . 开头的文件时隐藏文件。
三、用MobaXterm 在linux和windows之间上传/下载文件
MobaXterm实现linux和windows之间传输文件的具体步骤,以下就是具体的操作教程:
下载软件路径:
MobaXterm
可以选择免安装版(我已经试过非常好用,免费哦!)
注意:我测试的centos服务器是在某某云上购买的远程服务器。不是虚拟机。
1.连接服务器
打开MobaXterm客户端。
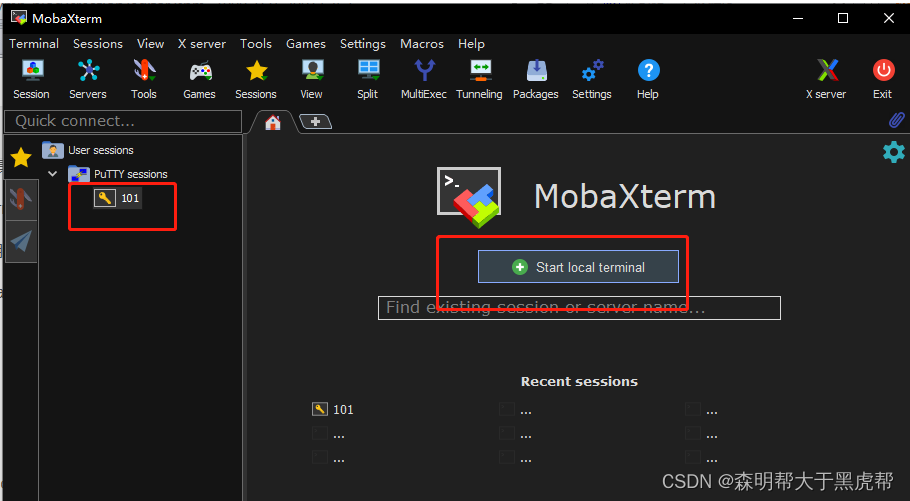
点击session列表,或者直接点击“Start local terminal”。然后输入:ssh root@ -p。
@前面是登录用户名,@后面是ip地址。-p后面跟地是密码。
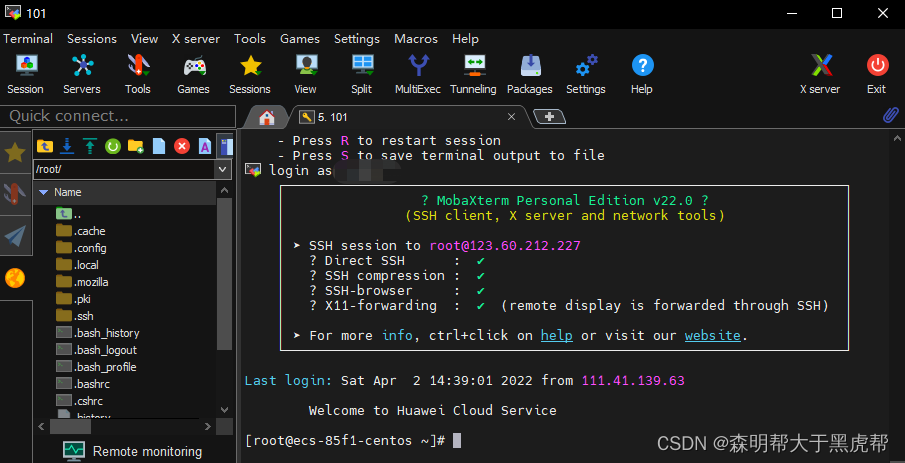
弹出来提示,输入密码,确认后登录linux服务。在左侧可以看到服务器的文件列表。
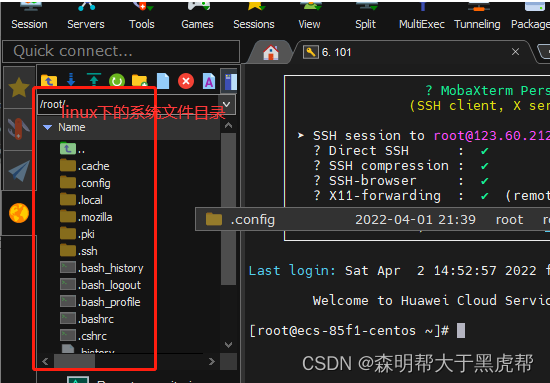
2.上传文件
在地址栏输入,要上传到的目录位置。例如:上传到/root/.config/下面。在地址栏的位置输入:/root/.config/,点击回车跳转到该目录下。
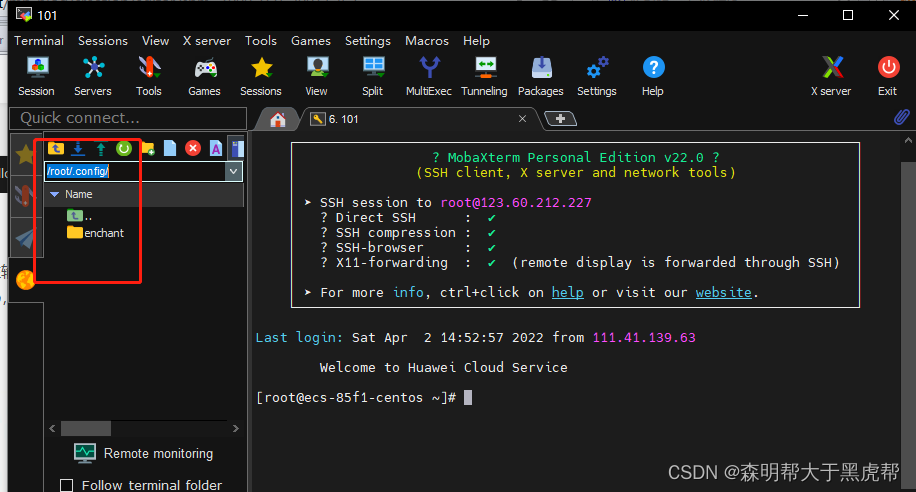
如图,点击上传按钮。或右键选择“upload to current folder”。
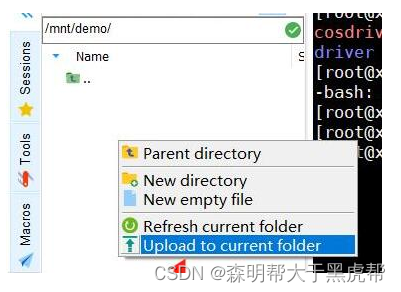
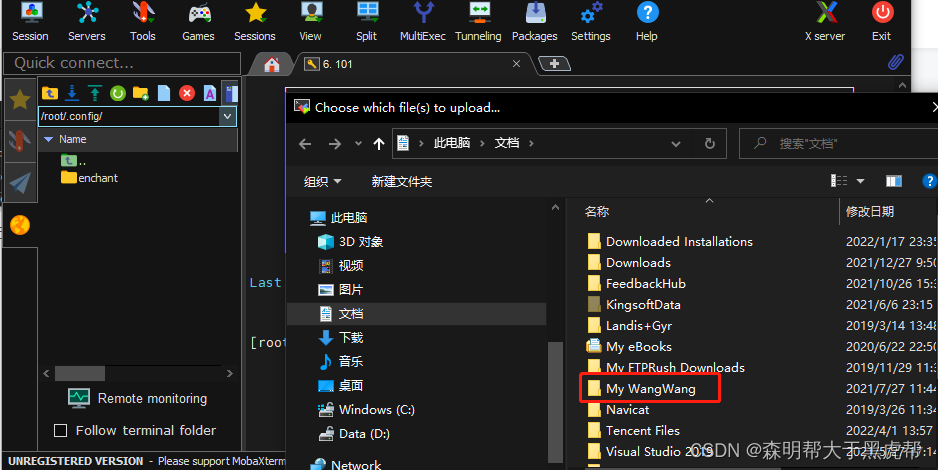
3.下载
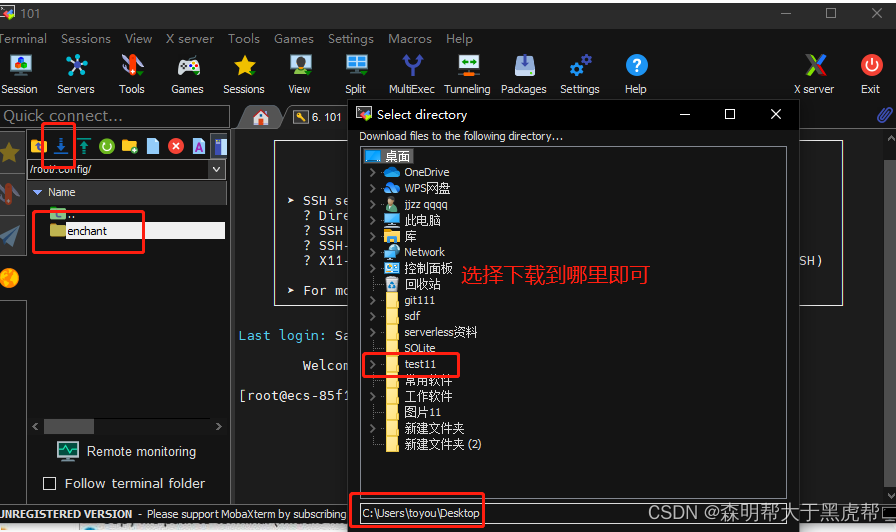
在服务器点击选择要下载的文件或目录。点击下载按钮,或右键点击文件/目录,选择“download”。
四、perf原理
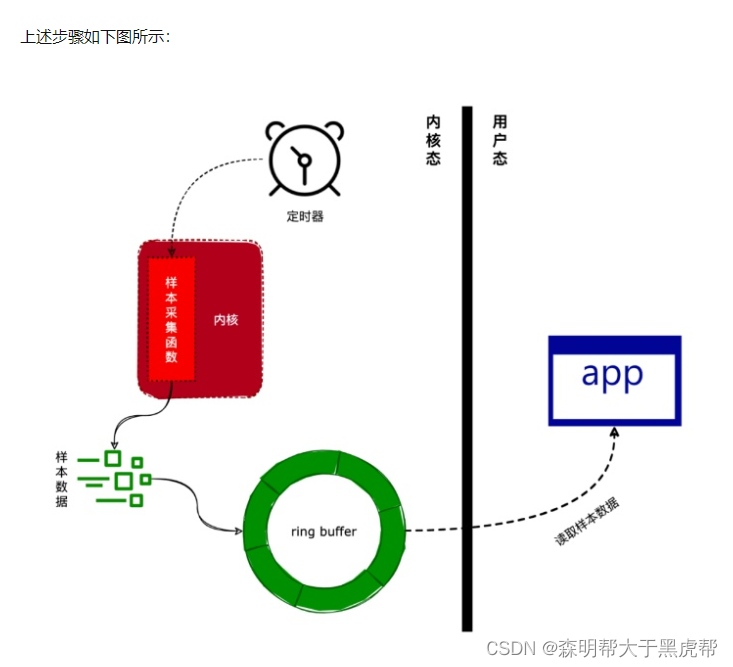
- 通过设置一个定时器,定时器的触发时间可以由用户设定。
- 定时器被触发后,将会调用采集函数收集当前运行环境的数据(如当前正在执行的进程和函数等)。
- 将采集到的数据写入到一个环形缓冲区(ring buffer)中。
- 应用层可以通过内存映射来读取环形缓冲区中的采样数据。
trace的跟踪方法是一种总体跟踪法,换句话说,你统计了一个事件到下一个事件所有的时间长度,然后把它们放到时间轴上,你可以知道整个系统运行在时间轴上的分布。
这种方法很准确,但跟踪成本很高。所以,我们也需要一种抽样形态的跟踪方法。perf提供的就是这样的跟踪方法。
perf的原理是这样的:每隔一个固定的时间,就在CPU上(每个核上都有)产生一个中断,在中断上看看,当前是哪个pid,哪个函数,然后给对应的pid和函数加一个统计值,这样,我们就知道CPU有百分几的时间在某个pid,或者某个函数上了。这个原理图示如下:
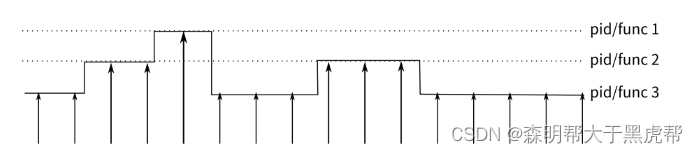
很明显可以看出,这是一种采样的模式,我们预期,运行时间越多的函数,被时钟中断击中的机会越大,从而推测,那个函数(或者pid等)的CPU占用率就越高。
当然,如果某个进程运气特别好,它每次都刚好躲过你发起探测的位置,你的统计结果可能就完全是错的了。这是所有采样统计都有可能遇到的问题了。
1.perf的使用
perf --help之后可以看到perf的二级命令。
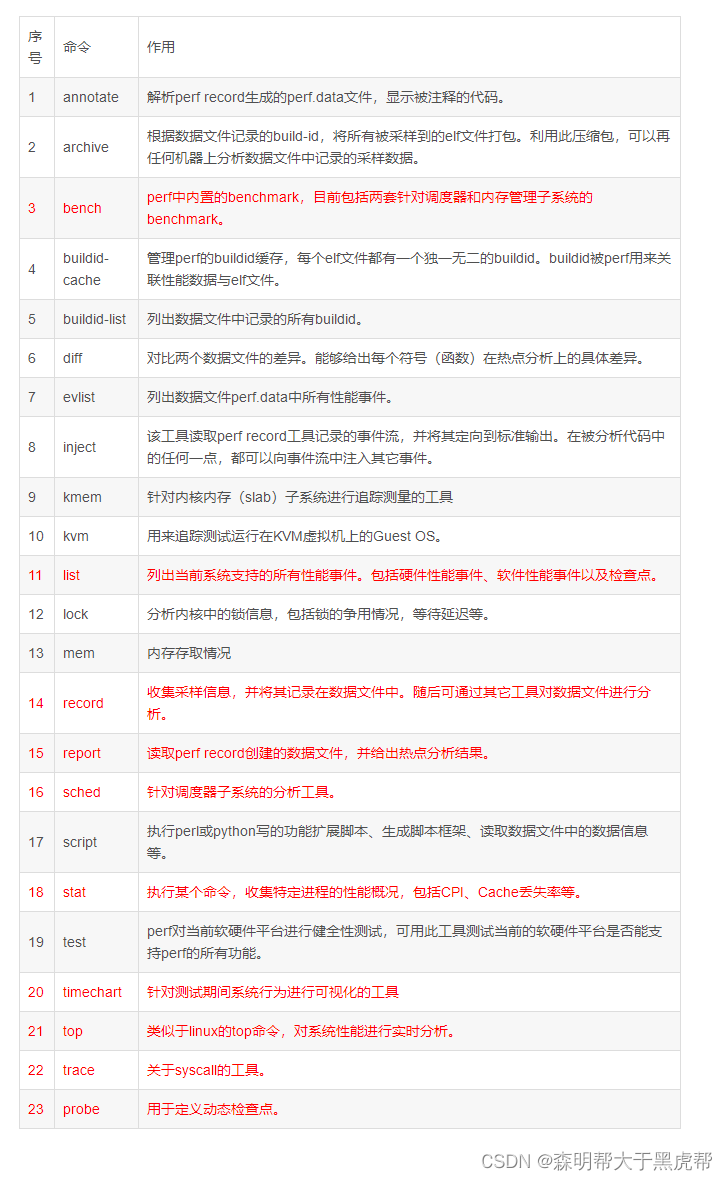
全局性概况:
perf list查看当前系统支持的性能事件;
perf bench对系统性能进行摸底;
perf test对系统进行健全性测试;
perf stat对全局性能进行统计;
全局细节:
perf top可以实时查看当前系统进程函数占用率情况;
perf probe可以自定义动态事件;
特定功能分析:
perf kmem针对slab子系统性能分析;
perf kvm针对kvm虚拟化分析;
perf lock分析锁性能;
perf mem分析内存slab性能;
perf sched分析内核调度器性能;
perf trace记录系统调用轨迹;
最常用功能perf record,可以系统全局,也可以具体到某个进程,更甚具体到某一进程某一事件;可宏观,也可以很微观:
pref record记录信息到perf.data;
perf report生成报告;
perf diff对两个记录进行diff;
perf evlist列出记录的性能事件;
perf annotate显示perf.data函数代码;
perf archive将相关符号打包,方便在其它机器进行分析;
perf script将perf.data输出可读性文本;
可视化工具perf timechart:
perf timechart record记录事件;
perf timechart生成output.svg文档;
2.perf简单介绍
执行perf --help命令我们可以看到其支持的一堆子命令:
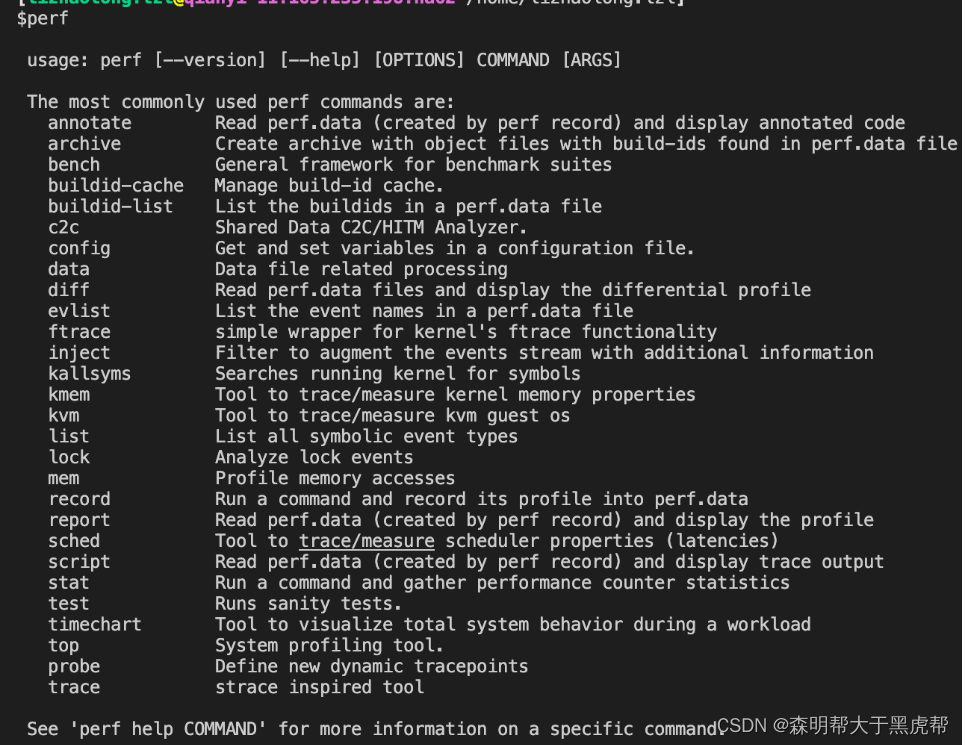
我们可以看到其中很多命令都是非常常用的,比如record(report/script),top,stat等等,尤其是top,甚至可以看到汇编级别的热代码,是十分牛逼的一个分析工具。这些子命令也分别拥有自己的help命令。可以看到perf本身提供的文档并不多,更详细的文档在源码的tools/perf/Documentation中。
perf本身的原理也非常有意思,其把事件源视为perf_event,并分为task和CPU两个维度进行事件触发,本身支持counting,sampling以及bpf作为事件的处理流程。事件源类型(不是机制)被分为Hardware Events,Software Events,Tracepoint,USDT以及Timed Profiling。
bpfTrace内部也是可以基于perf_event机制去做事件源的:
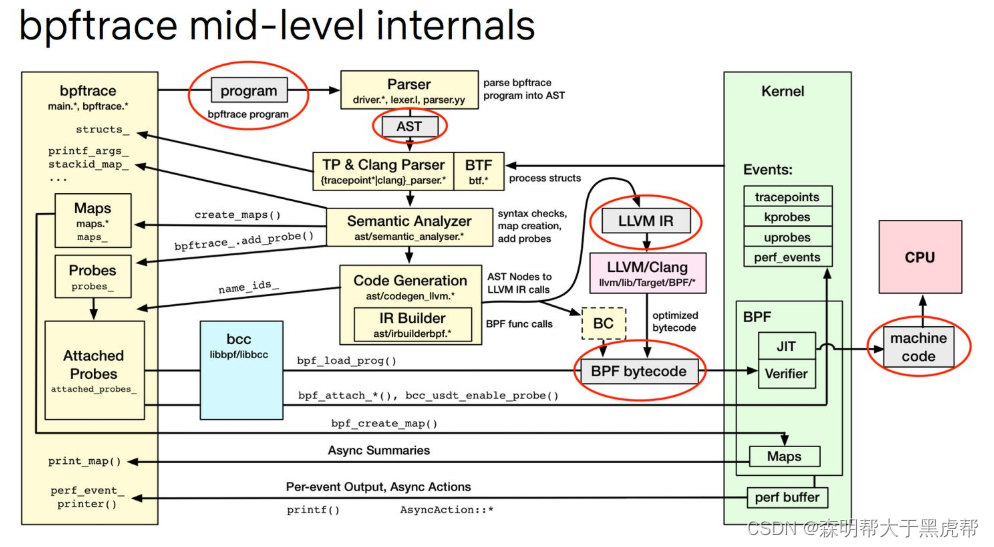
这篇文章先枚举几个基本但使用方法,然后分别介绍不同的事件类型与简单原理,最后进行总结。
3.常用命令格式
这一章节主要是列举一些常用的perf子命令,这些都可以应用到我们平时的排错过程中。
我们介绍几个比较有意思的perf命令,并简单实操下这几个命令,感受下这个神器的威力。
首先执行sudo perf list ‘:’ | less,查看所有支持的Tracepoint Event。
1.perf list
然后可以执行sudo perf record -e ‘sched:sched_switch’ -ag:
这个命令对sched:sched_switch进行检测,并对数据进行聚合,-a对意思是对所有CPU都进行数据采集,-g对意思收集栈帧对消息,最后把数据输出到perf.data文件中。
然后执行sudo perf report,即可以查看perf.data文件,因为我们加了-g,所以可以看到每一项数据的栈帧。
2.perf top
首先我们可以随意启动一个进程,这里我启动一个redis实例,找到其进程号然后执行sudo perf top -p 23981 -F 300HZ,这个指令的意思是300HZ就执行一个CPU-lock事件,查找进程23981的调用信息。然后我们就可以看到一个调用频率的排行,用方向键和回车可以查看一个事件的详细信息,甚至可以看到汇编级别的热代码。
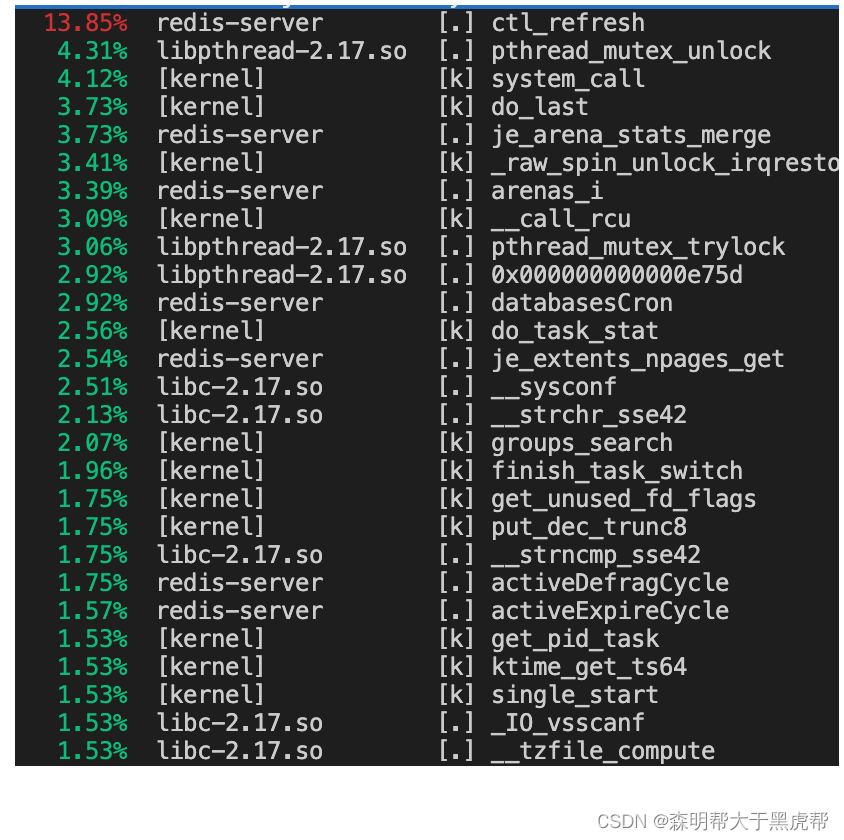
3.perf stat
最经典的计数命令当然也不能少,我们可以执行如下命令sudo perf stat -e ‘sched:*’ -p 23981 sleep 10,可以查看被监控事件的counter数据。
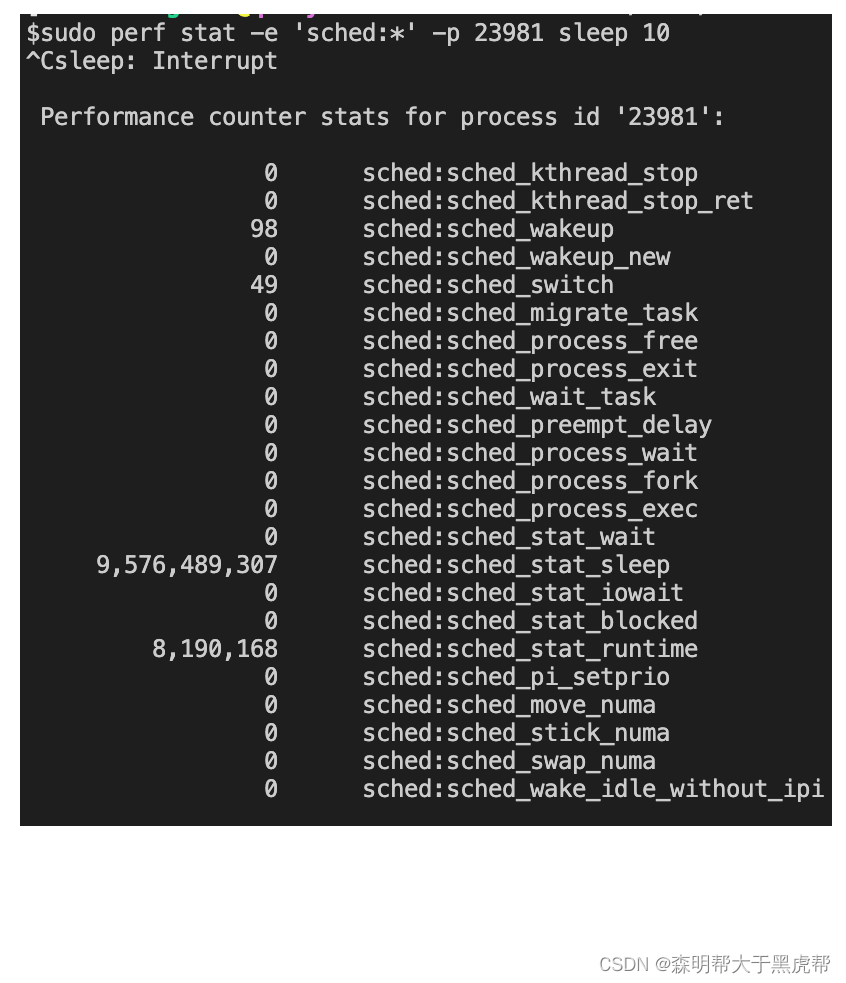
4.perf probe
好了,现在我们用的一直都是pre-defined的事件,现在我们来尝试动态加入一个Tracepoint,执行如下命令sudo perf probe --add udp_sendmsg,这样我们就在udp_sendmsg中埋上了点:

我们可以执行如下指令查看对于指定probe来说有效的局部变量perf probe -V udp_sendmsg:
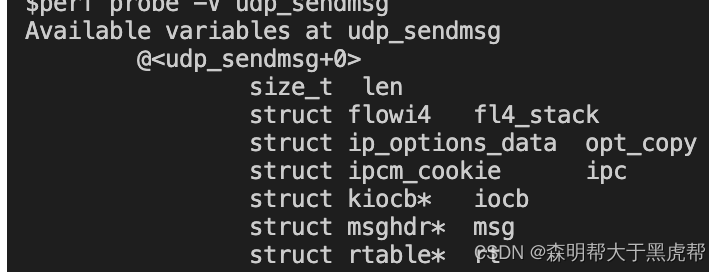
我们可以检测某个局部变量sudo perf probe --add ‘udp_sendmsg len’ -f,因为前面有同名的probe,需要加-f。然后执行sudo perf record -e probe:udp_sendmsg_1 -a采集数据,最后执行sudo perf report,可以看到len的值。我遇到的问题是report中的值都是十六进制数,也就是调试信息没有找到。
在内核的代码中查看Makefile,可以看到在定义了CONFIG_FRAME_POINTER和CONFIG_DEBUG_INFO时才会加载调试信息:
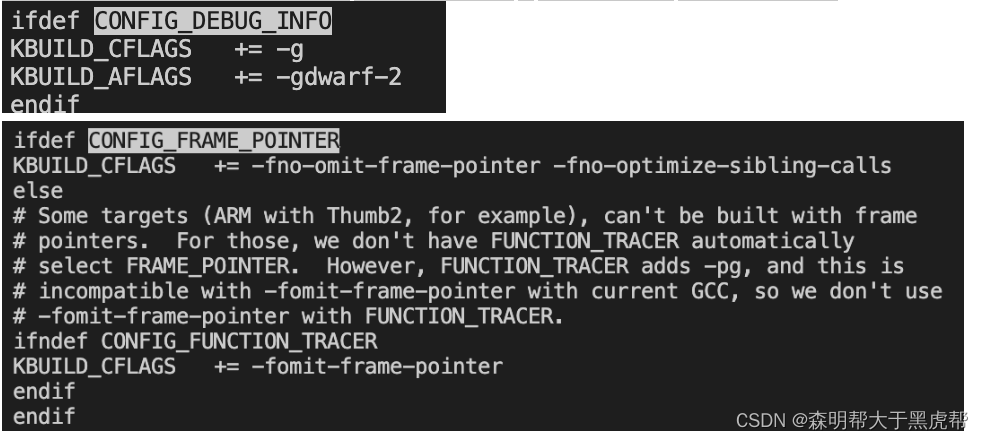
既然没有,说明编译内核的时候没有对应的调试信息,而且/proc/kallsyms文件大小也为零。
那理论我们使用kernel-debuginfo包就可以解决问题。yum下载以后可以执行sudo find / -name "kernel-debuginfo"找到包的下载路径,然后执行record --vmlinux=path,然后发现好像不是这么用的,找到[15]修改了vmlinux的参数为/boot下的文件,发现还是没有办法解决问题。
奇了大怪,到底该怎么找到调试符号呢,可能重新编译内核,加上调试信息就可以吧(但其他但perf信息就可以看到内核但堆栈信息,所以应该是操作问题)。事实上到现在我还是没有解决这个问题。
5.perf lock
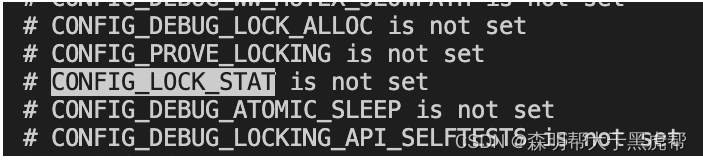
我们可以检测锁的各种信息,但是需要CONFIG_LOCKDEP和CONFIG_LOCK_STAT编译选项的开启,执行如下指令perf lock record ls,然后执行perf lock report,就可以看到详细的信息。相比之SystemTap/bpfTrace就什么也不需要,直接就可以采集到perf可以采集到的所有数据,但是需要脚本编写者自身对内核代码有所了解。
我的机器编译时没有开这个:
6.perf mem
我们可以检测内核中的内存分配情况,首先执行sudo perf kmem record ls,然后执行sudo perf kmem stat --caller --alloc,就可以看到内核中内存分配的信息了:
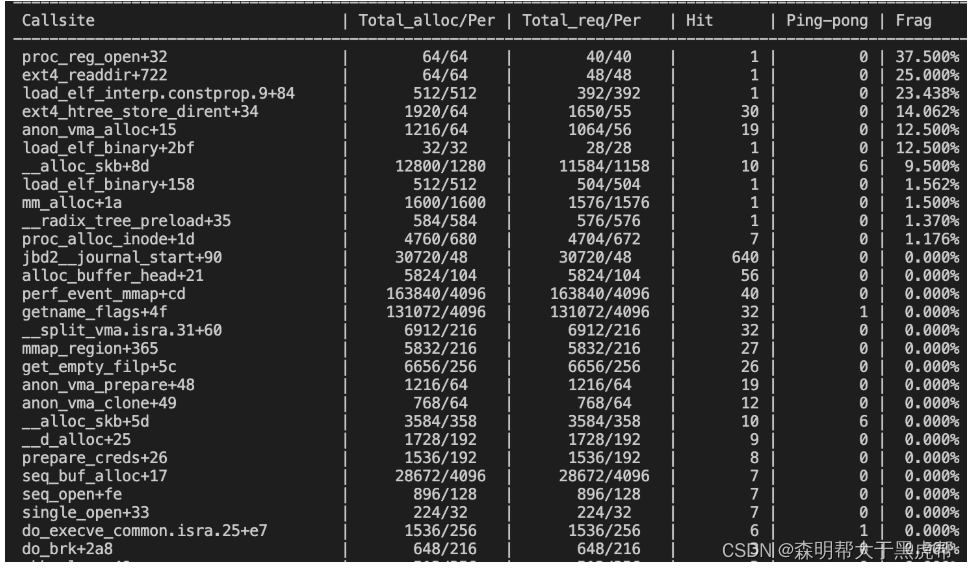
- Callsite:内核代码中调用kmalloc和kfree的地方。
- Total_alloc/Per:总共分配的内存大小,平均每次分配的内存大小。
- Total_req/Per:总共请求的内存大小,平均每次请求的内存大小。
- Hit:调用的次数。
- Ping-pong:kmalloc和kfree不被同一个CPU执行时的次数,这会导致cache效率降低。
- Frag:碎片所占的百分比,碎片 = 分配的内存 - 请求的内存,这部分是浪费的。
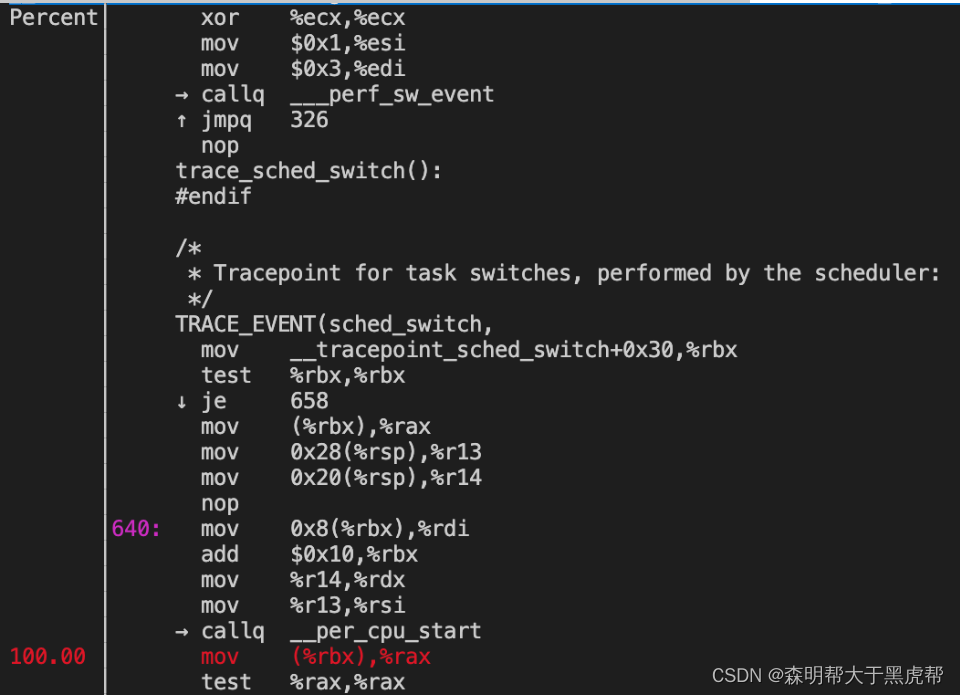
7.perf sched
我们也可以查看调度相关的事件,执行如下命令sudo perf sched record -p 23981,然后执行sudo perf report latency就可以查看一些调度属性。
因为是调度相关,先给redis benchmark上,执行./redis-benchmark -h 127.0.0.1 -p 6379 -c 100 -n 1000000,然后执行第一个命令,一两秒就累计了600MB的数据,然后执行第二个命令,我们可以看到如下输出:

然后调用sudo perf sched script,我们就可以知道这个最高的时延发生的原因是什么:

还有一个子命令非常有意思,就是sudo perf sched map,这可以用图表的方式来查看不同CPU核上任务的转移情况,这种情况下显然前面监控redis的perf.data就不太适合作为例子了,因为绝大多数情况redis实例都是在一个核上跑的,我们先执行:sudo perf sched record – sleep 1,再执行sudo perf sched map,可以看到类似这样的输出:

其中类似A0,B0,C0这样的标识符代表了一个任务,然后*代表CPU刚刚调度一个事件,.代表此CPU目前空闲,这种分析可以很好的观测当前系统中任务切换的情况。但是我认为能解决的问题有限,还是latecny搭配script实用一点。
8.perf annotate
奇怪的一个子命令,这个命令可以看到所监控事件部分的高级语言代码和汇编,但是打印出来好像也没啥用,我发现不管去观察哪一个pref.data,总会有一句汇编是百分百的命中率,如果能够看到这个命令每句指令的命中情况的话就很棒了: