目录
摘要:
长短期记忆网络(LSTM)对大数据训练具有很强的适应性和出色的扩展性,相较于RNN无法处理长期依赖的问题具有很大的优势。基于LSTM神经网络,针对人为经验调参困难的问题,提出了一种基于贝叶斯优化的LSTM模型,使用贝叶斯对LSTM的超参数进行优化,得到最佳的LSTM参数设置情况,并使用该最佳网络进行实际回归预测,结果表明,基于贝叶斯优化的LSTM模型表现出了良好的性能,预测精度较高。本模型为多输入单输出。
研究背景:
在现如今的大数据时代背景下,数据的规模不断增大,累积的数据颠覆了传统数据的规模,甚至可以达到PB级别。基于传统统计模型的数学方法已很难处理这些海量数据,而利用大数据平台所提供的强存储和强计算能力,结合一些神经网络模型、机器学习算法等,可以较好地对大规模数据进行回归预测。
早期的预测模型,如整合移动平均自回归法(ARIMA)、支持向量机(SVM)、马尔科夫链模型(Markovchainmodel)等,虽然取得了不错的预测效果,但无法深入挖掘数据之间的内在联系。长短期记忆神经网络LSTM可以挖掘大数据之间的深层关系,而且能满足神经网络需要大量数据训练的特征,因此该模型在交通、电力等领域的预测中应用广泛,并呈现出良好的长期与短期预测性能。
然而,在实际中运用深度学习进行回归时,对超参数的确定主要根据经验或者手工优化,参数优化效率较低,在预测准确率上仍然有提升的空间。
长短期神经网络介绍:
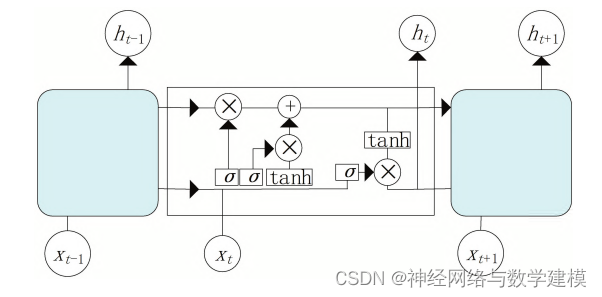
LSTM是一种在RNN的基础上提出的特殊循环神经网络。相较于传统的循环神经网络,LSTM可以很好地解决梯度消失和梯度爆炸的问题。其核心之处在于设计一个记忆细胞,具备选择记忆的功能,可以选择记忆重要信息,过滤掉噪声信息,减轻记忆负担。LSTM使用遗忘门、输入门、输出门来控制信息,完成该网络功能的实现。
贝叶斯优化算法:
普通求函数极值的问题,可以利用基于梯度的优化来解决。但在LSTM模型调参的过程中,不能够直接确定对应的函数关系,所以无法使用传统的优化算法来对超参数进行调优。而贝叶斯优化算法是一种blackbox优化算法,不需要知道目标函数的表达式,以极其简洁的框架来寻找全局最优解,非常适用于LSTM模型的调参。
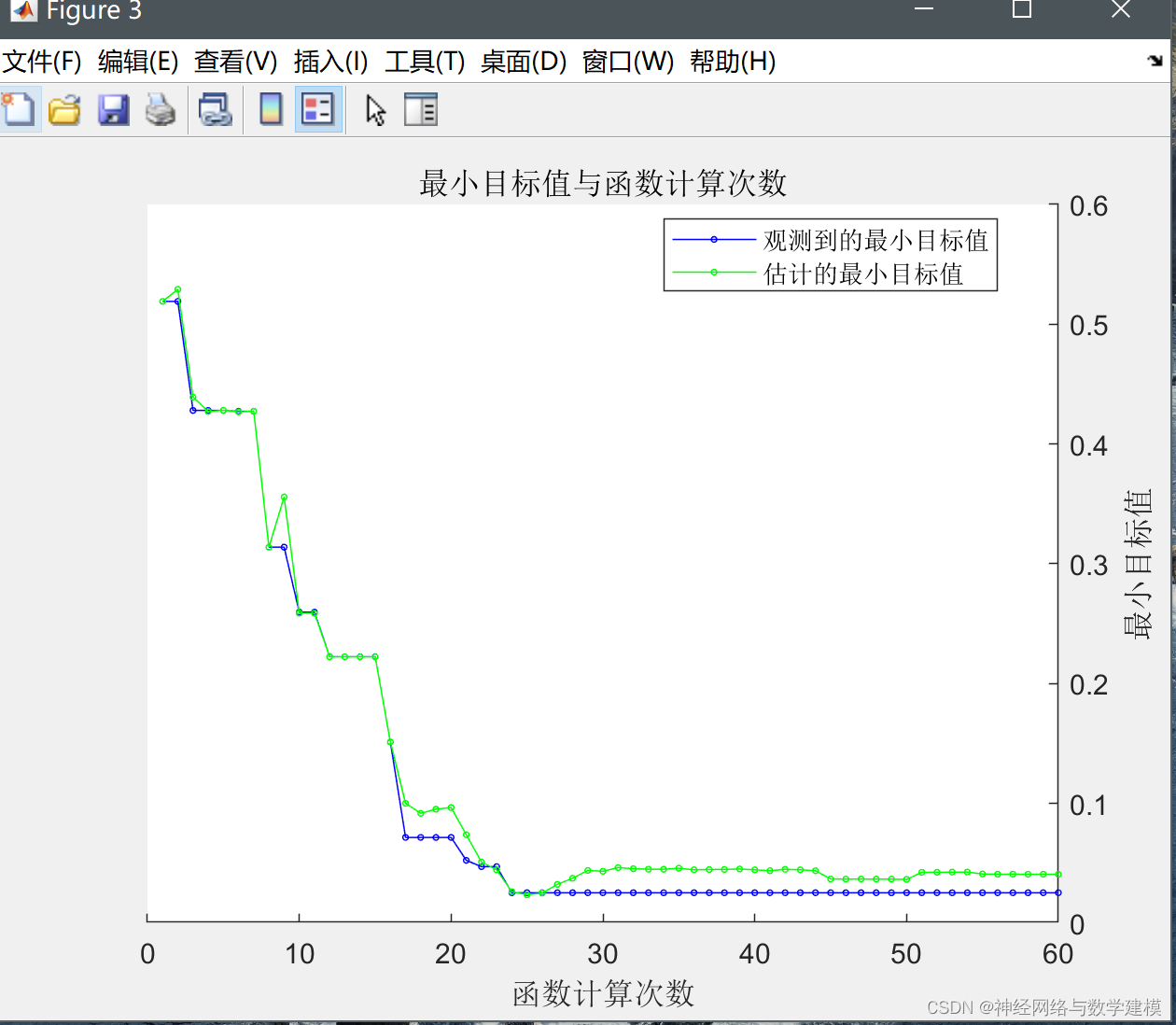
算法的思路是利用目标函数的先验概率分布及已知观测点来更新后验概率分布,然后根据后验概率分布寻找下一个极小值点,使极小值不断减小,最终得到最优超参数。
基于贝叶斯优化的LSTM:
在传统的LSTM神经网络训练过程中,需要人为调节超参数。超参数的取值对模型的性能有很大的影响,但超参数的选择无规律性,且具有很大的偶然性,这对人为调参很不友好,往往无法得到最优超参数。针对这一问题,本文引入贝叶斯优化算法,贝叶斯优化算法主要包含概率代理模型和采集函数两个部分。概率代理模型可以利用高斯过程寻找目标函数的近似,得到目标函数的后验概率分布;采集函数根据后验概率分布,在未知区域和已观测到出现最优结果的区域进行采样,选择合适的样本点使得目标函数取极值。
综上分析,本文引入基于贝叶斯优化的LSTM模型。该模型分为三个阶段,第一阶段训练LSTM模型,第二阶段将需要进行优化的超参数传入贝叶斯优化模型,第三阶段利用优化后的LSTM模型输出预测结果。
(1)LSTM训练阶段:
步骤1超参数初始化。
步骤2输入训练集进行LSTM神经网络的训练。
步骤3输出与训练集维度一致的数据,并不断地对超参数进行更新。
(2)贝叶斯优化阶段:
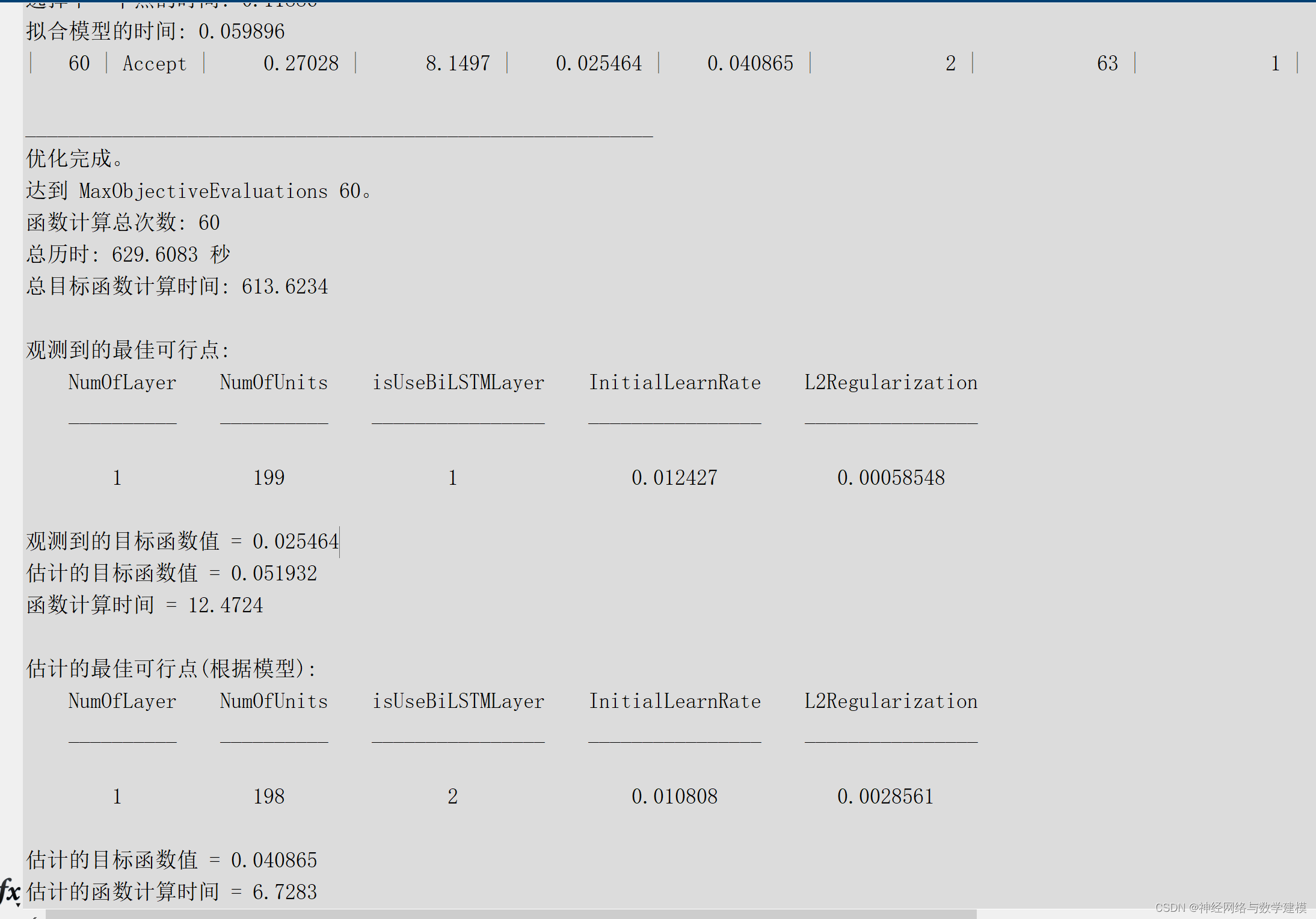
步骤1定义需要优化的超参数,并设置参数空间。
步骤2定义优化目标函数,并将定义的超参数带入LSTM模型进行训练。
步骤3利用高斯过程求目标函数的后验概率分布,根据后验概率分布对超参数样本点进行采样,优先选择最优超参数,实现对超参数的更新。
步骤4不断更新目标函数的后验概率分布和超参数,直至满足模型的要求。
(3)LSTM预测阶段:
步骤1将验证集传入训练好的LSTM模型,输出预测结果。
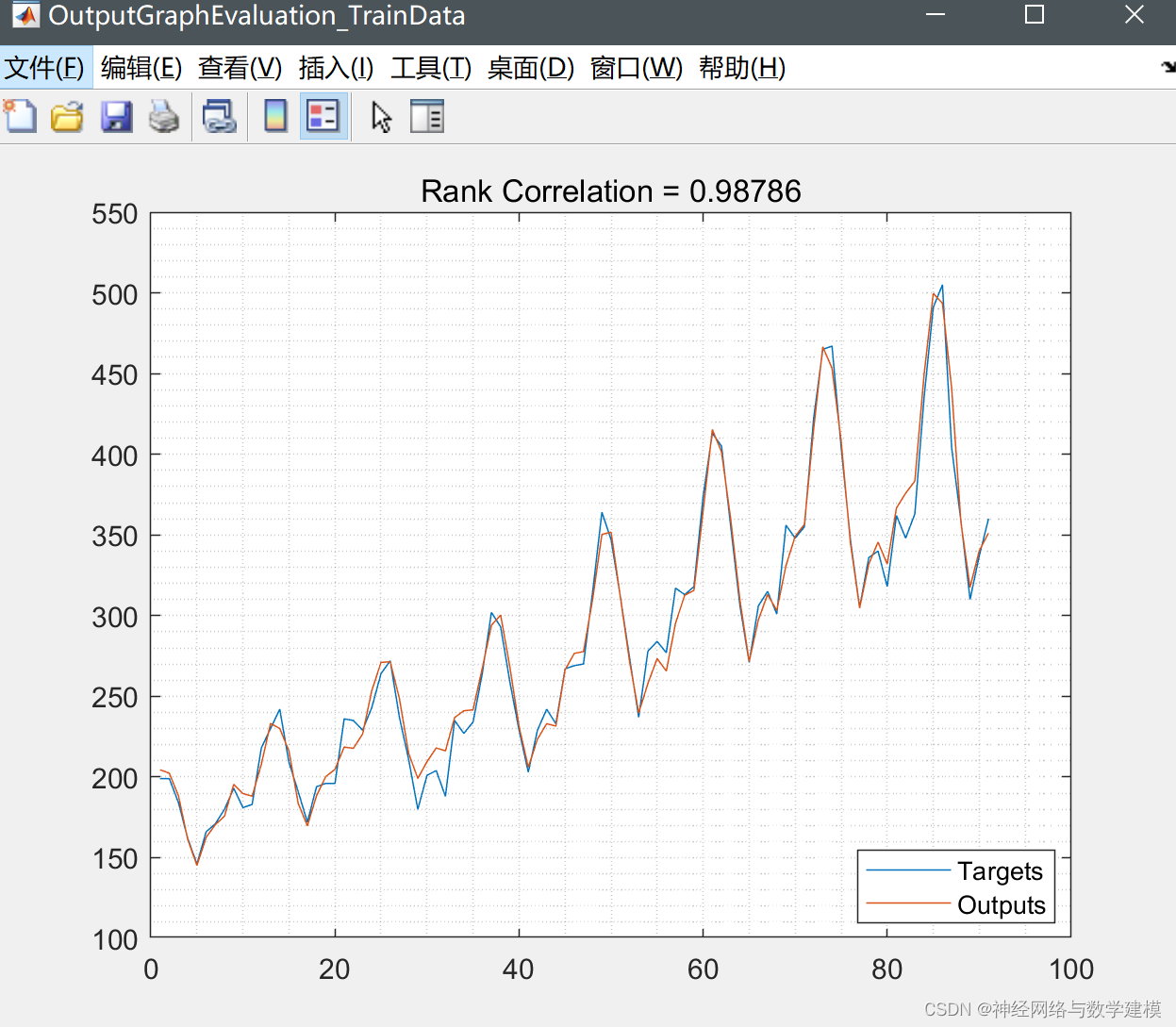
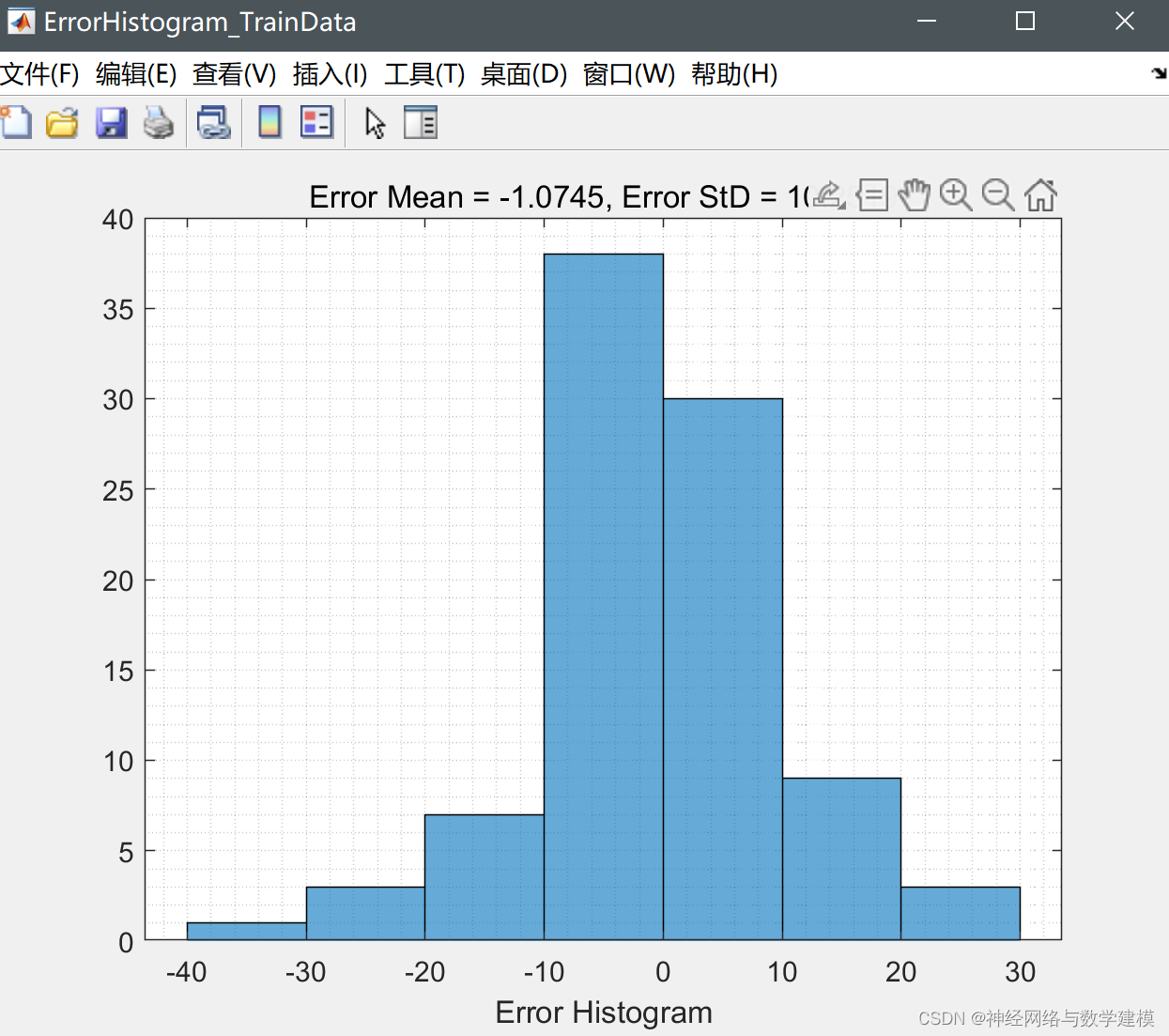
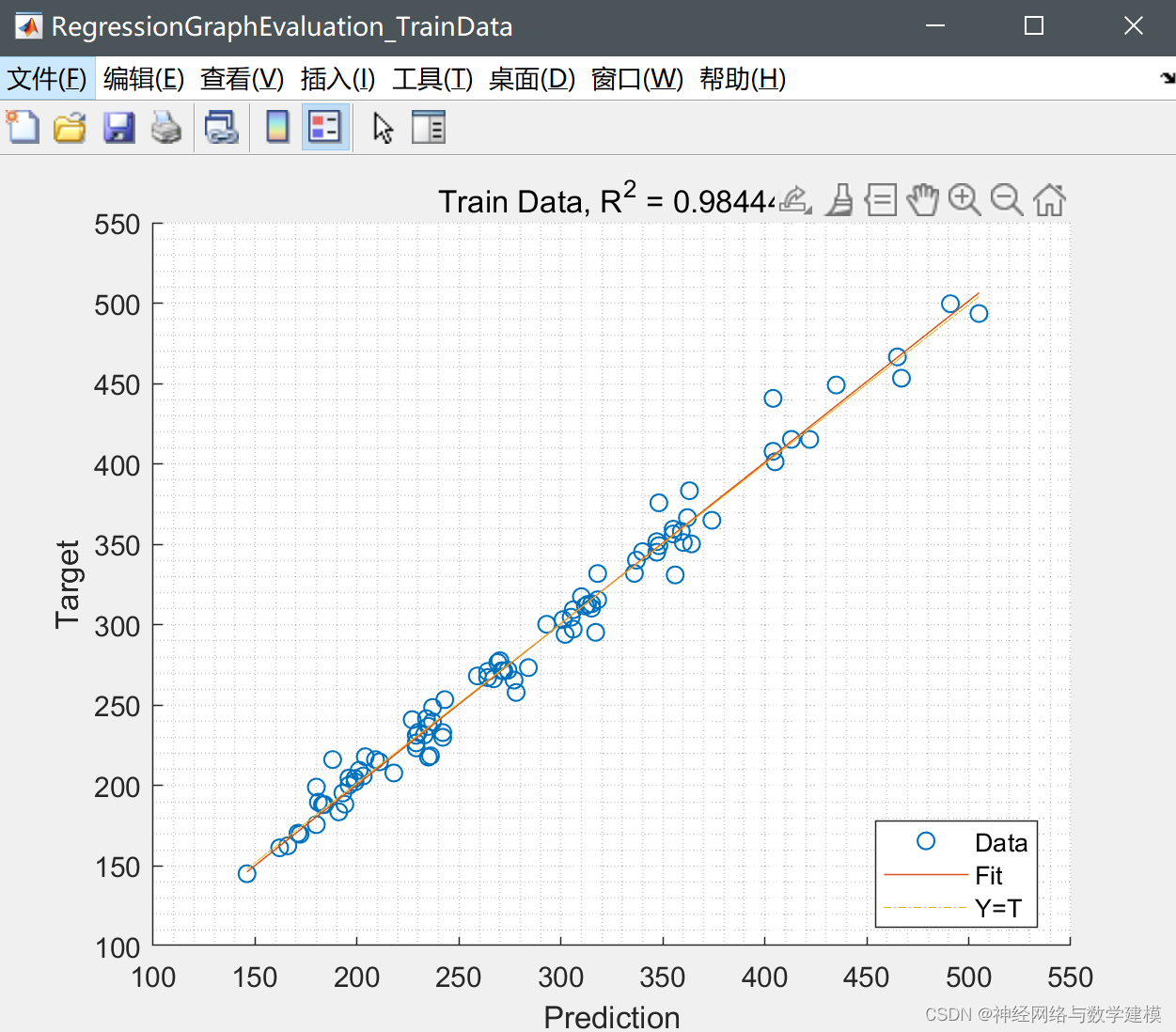
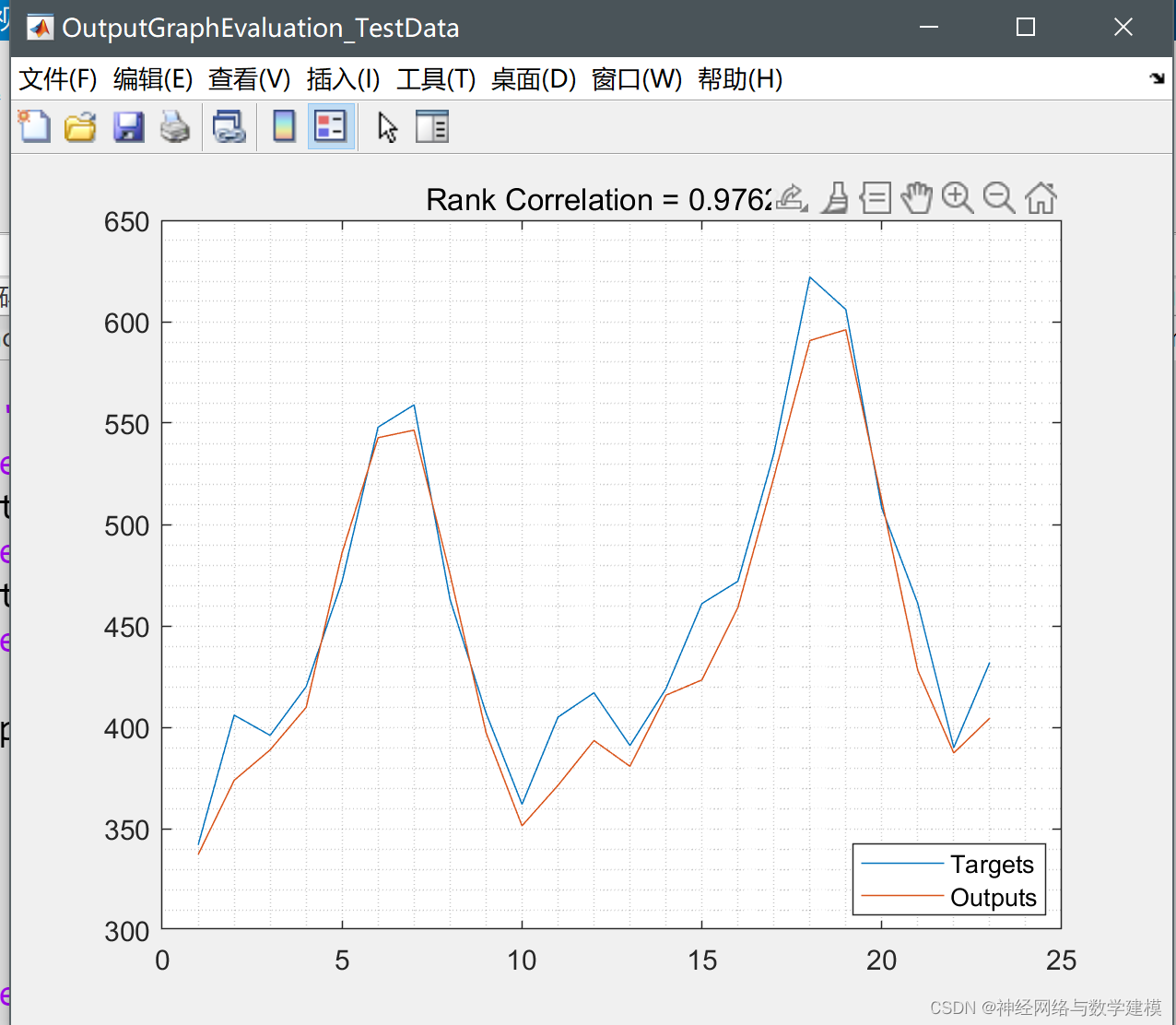
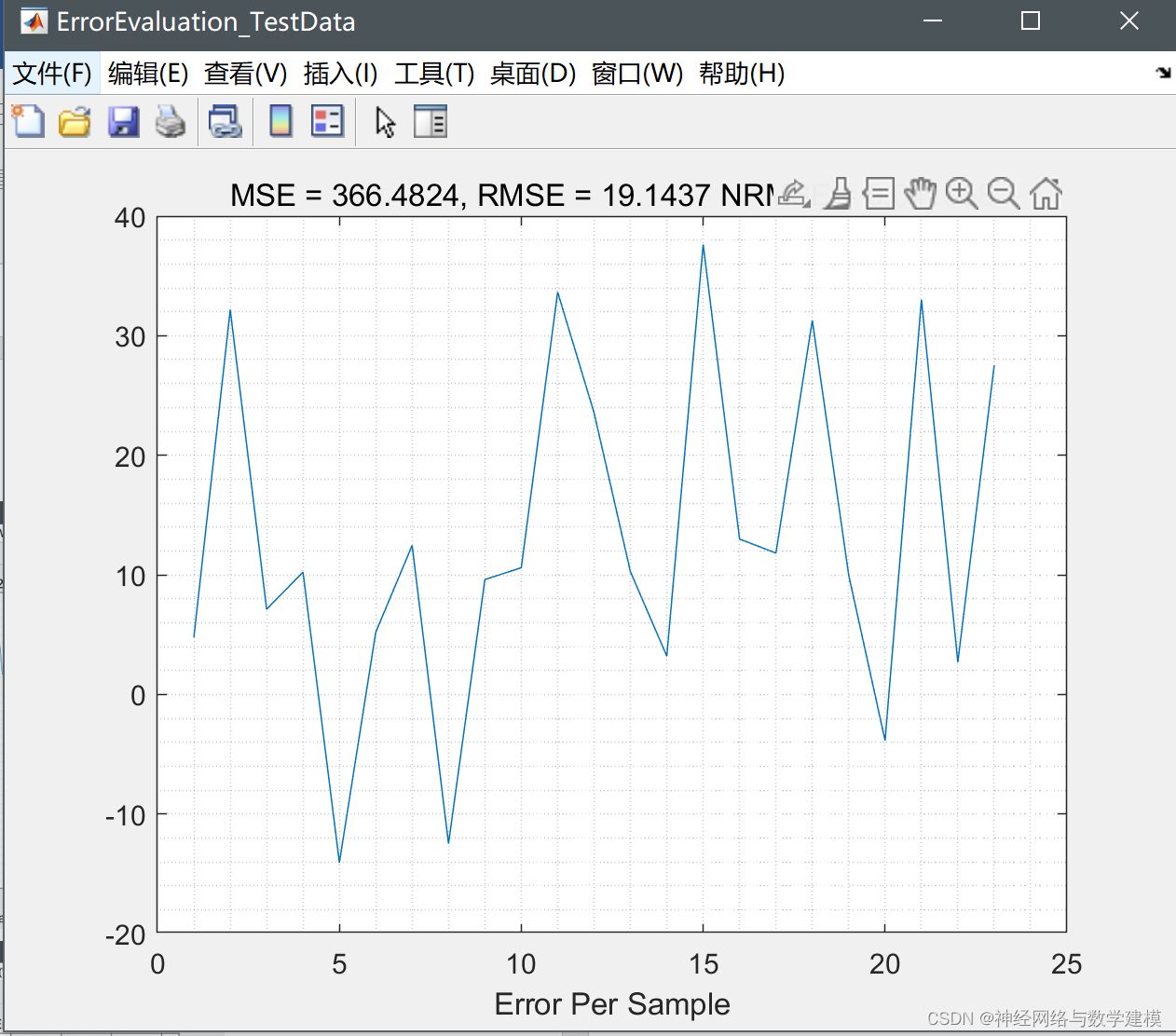
程序运行结果:
参考文献:基于贝叶斯优化的LSTM高速交通流量预测

本文Matalb代码分享:
