SCI一区 | MATLAB实现BO-CNN-LSTM-Mutilhead-Attention贝叶斯优化卷积神经网络-长短期记忆网络融合多头注意力机制多变量时间序列预测
目录
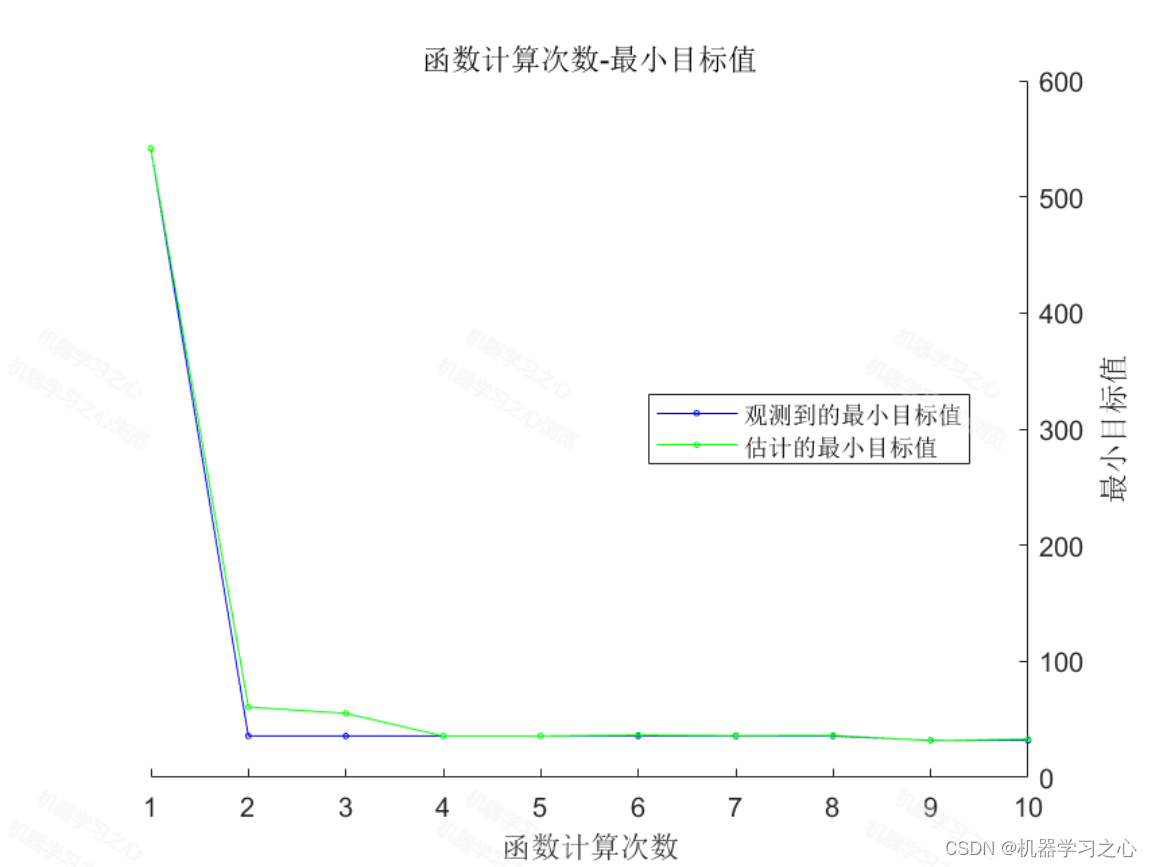
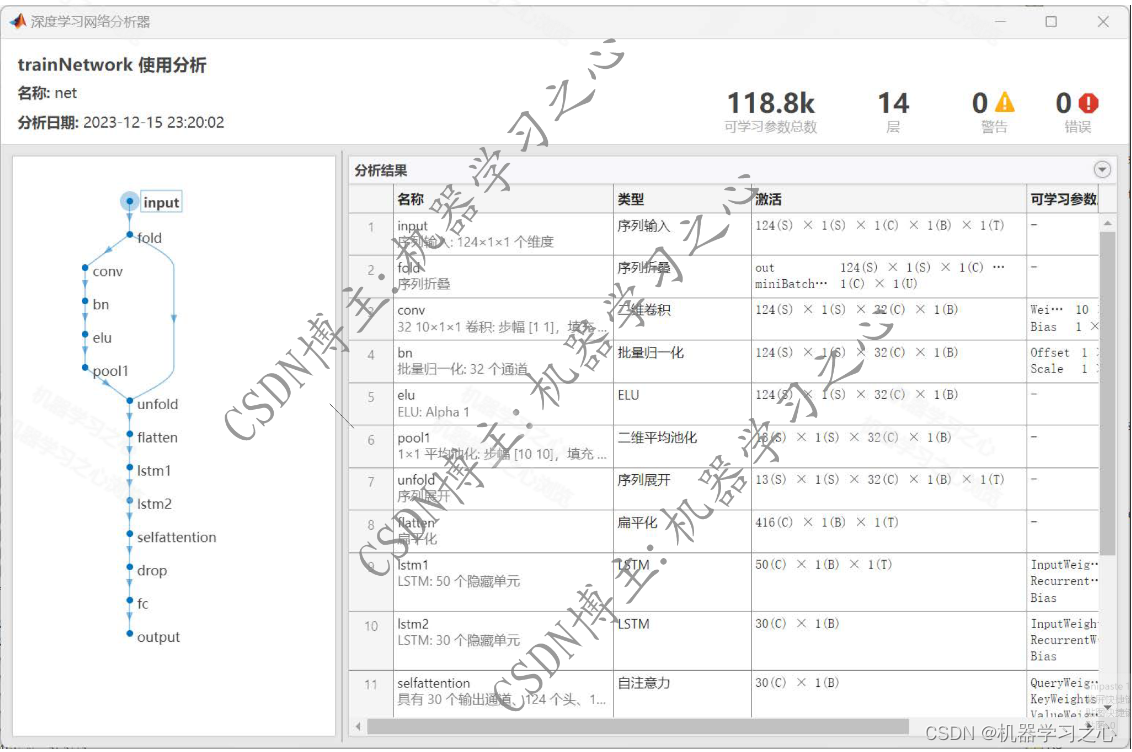
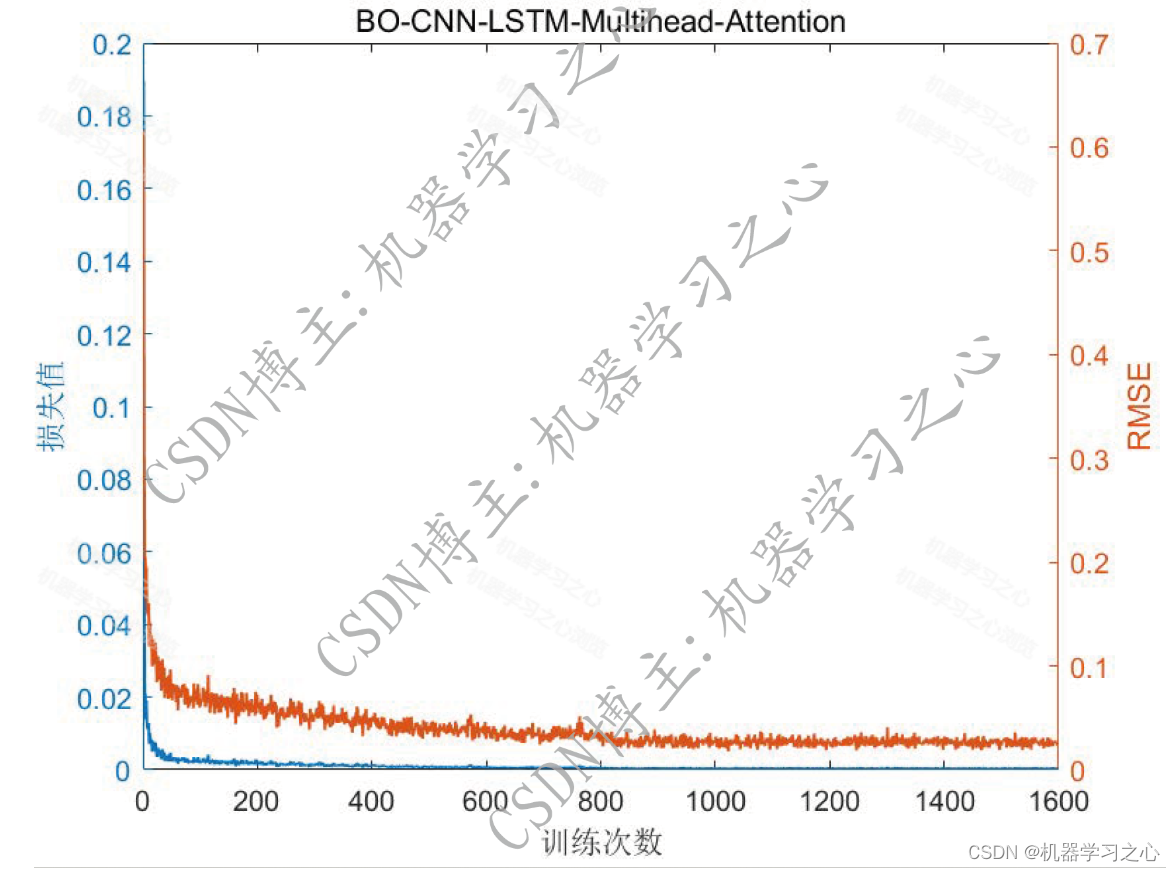
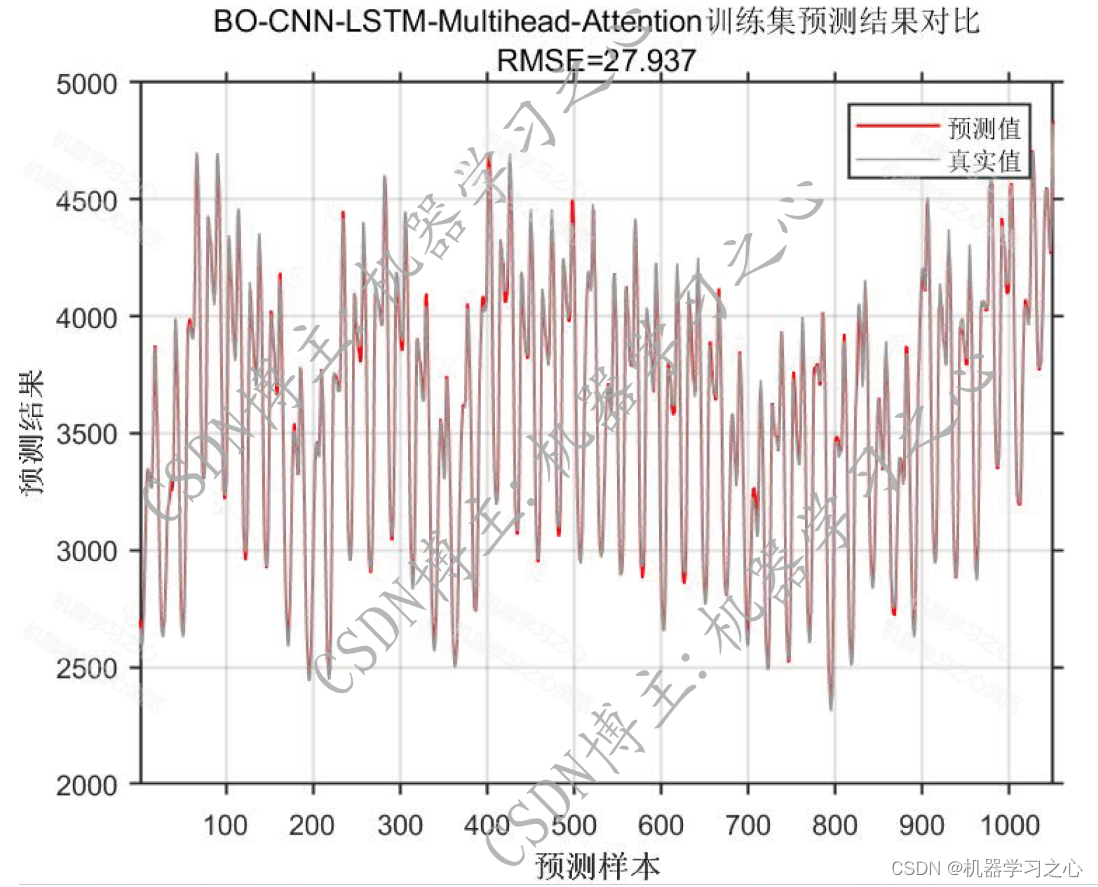
预测效果

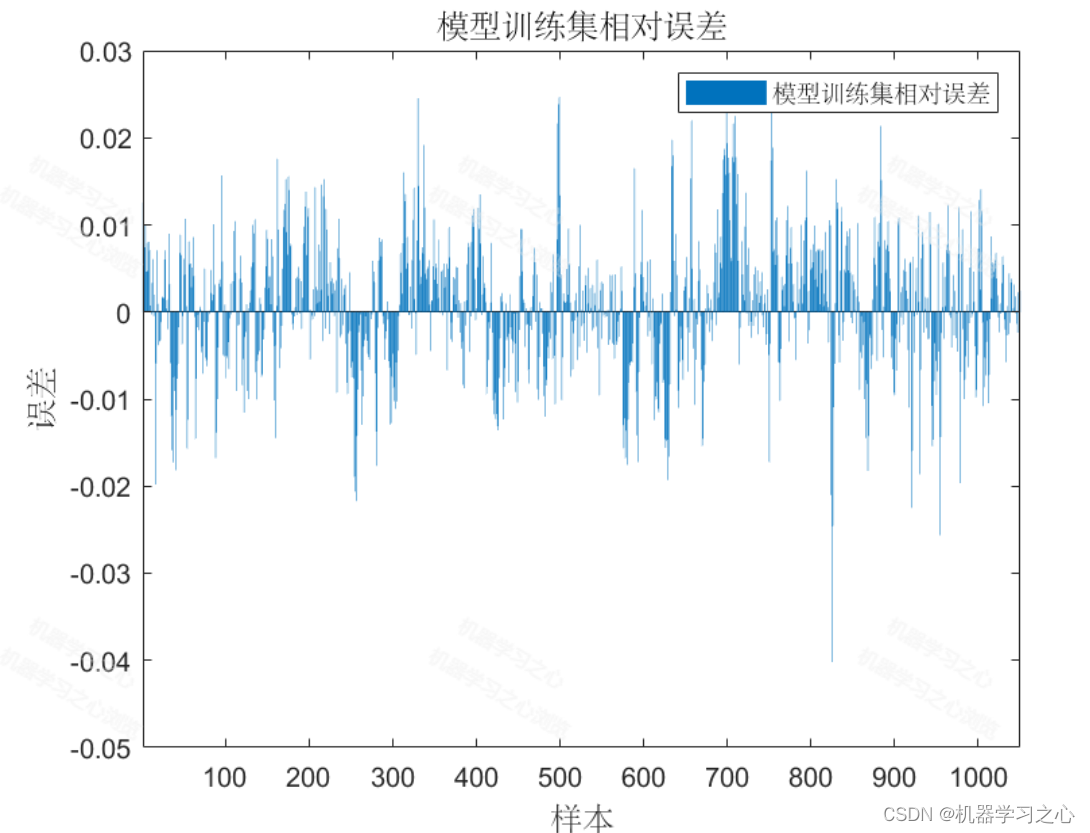
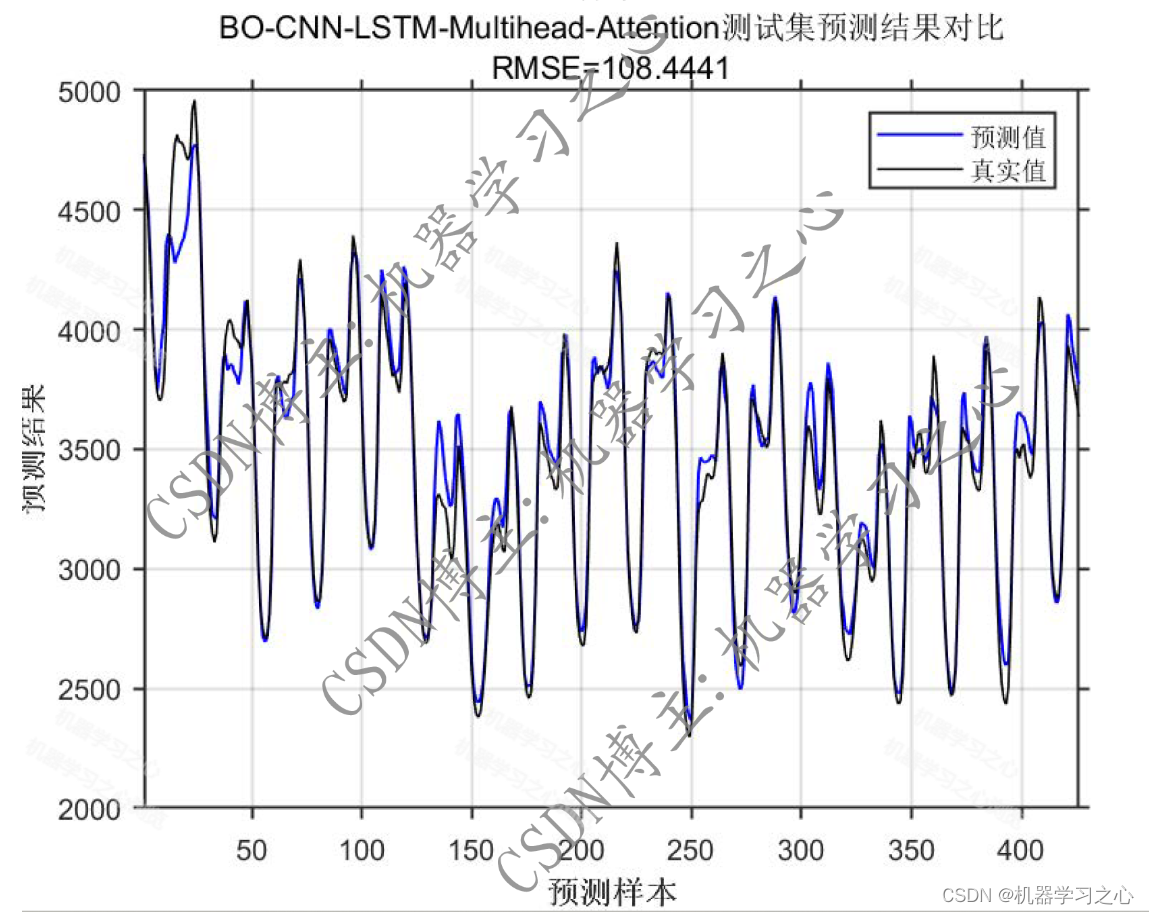





基本介绍
1.Matlab实现贝叶斯优化CNN-LSTM融合多头注意力机制多变量时间序列预测,BO-CNN-LSTM-Mutilhead-Attention;
MATLAB实现BO-CNN-LSTM-Mutilhead-Attention贝叶斯优化卷积神经网络-长短期记忆网络融合多头注意力机制多变量时间序列预测。多头自注意力层 (Multihead-Self-Attention):Multihead-Self-Attention多头注意力机制是一种用于模型关注输入序列中不同位置相关性的机制。它通过计算每个位置与其他位置之间的注意力权重,进而对输入序列进行加权求和。注意力能够帮助模型在处理序列数据时,对不同位置的信息进行适当的加权,从而更好地捕捉序列中的关键信息。在时序预测任务中,注意力机制可以用于对序列中不同时间步之间的相关性进行建模。
2.data为数据集,格式为excel,4个输入特征,1个输出特征,考虑历史特征的影响,多变量时间序列预测,main.m是主程序,其余为函数文件,无需运行;
3.贝叶斯优化参数为:学习率,隐含层节点,正则化参数;
4.评价指标包括:R2、MAE、MSE、RMSE和MAPE等。
模型描述

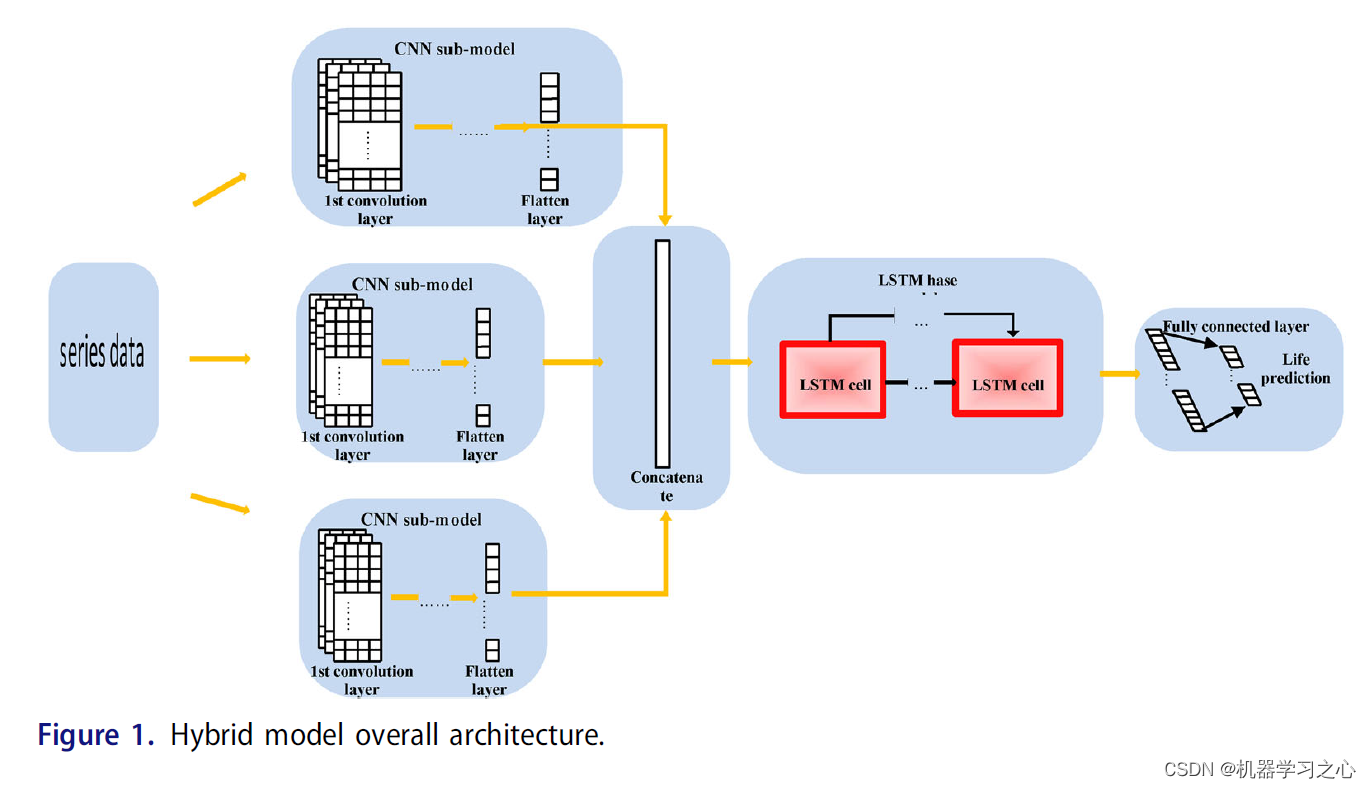
贝叶斯优化卷积神经网络-长短期记忆网络融合多头注意力机制多变量时间序列预测是一种复杂的模型框架,结合了多种神经网络技术和注意力机制,用于处理多变量时间序列数据的预测问题。
贝叶斯优化是一种用于优化问题的方法,它通过建立目标函数的高斯过程模型来预测最优解的位置,并在每次迭代中选择下一个样本点以更新模型。在神经网络中,贝叶斯优化可以用来搜索网络的超参数,如学习率、正则化参数等,以优化模型的性能。
卷积神经网络是一种深度学习模型,特别适用于处理具有网格结构的数据,如图像。CNN可以通过卷积层提取输入数据的局部特征,并通过池化层减小特征图的尺寸。在时间序列预测中,CNN可以用于捕捉时间序列数据中的局部模式和特征。
LSTM是一种递归神经网络(RNN)的变体,用于处理序列数据。LSTM通过门控单元的结构来记忆和控制过去的信息,并在预测时选择性地利用这些信息。LSTM网络对于长期依赖关系的建模具有优势,适用于时间序列数据的预测任务。
多头注意力机制(Multi-Head Attention)是一种用于处理序列数据的注意力机制的扩展形式。它通过使用多个独立的注意力头来捕捉不同方面的关注点,从而更好地捕捉序列数据中的相关性和重要性。在多变量时间序列预测中,多头注意力机制可以帮助模型对各个变量之间的关系进行建模,并从中提取有用的特征。贝叶斯优化卷积神经网络-长短期记忆网络融合多头注意力机制多变量时间序列预测模型可以更好地处理多变量时间序列数据的复杂性。它可以自动搜索最优超参数配置,并通过卷积神经网络提取局部特征,利用LSTM网络建模序列中的长期依赖关系,并借助多头注意力机制捕捉变量之间的关联性,从而提高时间序列预测的准确性和性能。
程序设计
- 完整程序和数据获取方式:私信博主回复SCI一区 | MATLAB实现BO-CNN-LSTM-Mutilhead-Attention贝叶斯优化卷积神经网络-长短期记忆网络融合多头注意力机制多变量时间序列预测获取。
%---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
%% 数据集分析
outdim = 1; % 最后一列为输出
num_size = 0.7; % 训练集占数据集比例
num_train_s = round(num_size * num_samples); % 训练集样本个数
f_ = size(res, 2) - outdim; % 输入特征维度
%---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
%% 划分训练集和测试集
P_train = res(1: num_train_s, 1: f_)';
T_train = res(1: num_train_s, f_ + 1: end)';
M = size(P_train, 2);
%---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
P_test = res(num_train_s + 1: end, 1: f_)';
T_test = res(num_train_s + 1: end, f_ + 1: end)';
N = size(P_test, 2);
————————————————
版权声明:本文为CSDN博主「机器学习之心」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/kjm13182345320/article/details/130471154
参考资料
[1] http://t.csdn.cn/pCWSp
[2] https://download.csdn.net/download/kjm13182345320/87568090?spm=1001.2014.3001.5501
[3] https://blog.csdn.net/kjm13182345320/article/details/129433463?spm=1001.2014.3001.5501