引言
在第二三节课中,主要研究的是四个关键网络属性以表征图形:度分布,路径长度,聚类系数和连接组件 。 这些定义主要是针对无向图的,而由于上一节中已经介绍了度分布,以及相应公式和例题,关于路径长度,简单来讲就是一个图中所需占比最短的一条或者多条路径,该路径并不唯一,讲深点,就得从过程遍历来看列举的四种算法了,每种都有每种的优劣,这里也不再详述,主要根据课程助教写的笔记,针对后两个重新复习。
C l u s t e r i n g C o e f f i c i e n t Clustering \ \ Coefficient Clustering Coefficient
聚类系数(针对无向图)用于衡量节点 i i i 的邻居所占比例。 对于度数为 k i k_{i} ki的节点 i i i,我们计算聚类系数为 C i = 2 e i k i ( k i − 1 ) C_{i}=\frac{2e_{i}}{k_{i}(k_{i}-1)} Ci=ki(ki−1)2ei 其中 e i e_{i} ei 是节点 i i i 的相邻节点之间的边数。 注意 C i ∈ [ 0 , 1 ] C_{i}\in[0,1] Ci∈[0,1] 。 此外,对于度数为0或1的节点,聚类系数是不确定的。
同样,可以计算平均聚类系数为: C = 1 N ∑ i N C i C=\frac{1}{N}\sum_{i}^{N}C_{i} C=N1i∑NCi 平均聚类系数使我们能够看到边在网络的某些部分是否显得更加密集。 在社交网络中,平均聚类系数趋于很高,表明如我们期望的那样,朋友的朋友倾向于彼此认识。
该点还会在之后提到,这里只做简单概述
C o n n e c t i v i t y Connectivity Connectivity
图的连通性可衡量最大连通组件的大小。 最大的连通组件是可以通过路径将任意两个顶点连接在一起的图的最大的集合。
查找连接的组件:
- 从随机节点开始并执行广度优先搜索(BFS)
- 标记BFS访问的节点
- 如果访问了所有节点,则表明网络是连通的
- 否则,找到一个未访问的节点并重复BFS
课程链接与相关工具介绍
| 斯坦福原版视频 |
https://www.youtube.com/watch?v=3IS7UhNMQ3U&list=PLoROMvodv4rPLKxIpqhjhPgdQy7imNkDn&index=4
https://www.youtube.com/watch?v=4dVwlE9jYxY&list=PLoROMvodv4rPLKxIpqhjhPgdQy7imNkDn&index=5
https://www.youtube.com/watch?v=buzsHTa4Hgs&list=PLoROMvodv4rPLKxIpqhjhPgdQy7imNkDn&index=6
| 本节课学习资料与工具 |
本节的助教笔记:https://snap-stanford.github.io/cs224w-notes/preliminaries/measuring-networks-random-graphs
同济子豪的笔记:https://github.com/TommyZihao/zihao_course/blob/main/CS224W/2-tradition-ml.md
NetworkX-常用图数据挖掘算法:https://networkx.org/documentation/stable/reference/algorithms/index.html
NetworkX-节点重要度算法:https://networkx.org/documentation/stable/reference/algorithms/centrality.html
NetworkX-Clustering算法:https://networkx.org/documentation/stable/reference/algorithms/clustering.html
NetworkX-最短路径算法:https://networkx.org/documentation/stable/reference/algorithms/shortest_paths.html
CSC641-Fall2015-Module-2-Centrality-Measures:https://www.jsums.edu/nmeghanathan/files/2015/08/CSC641-Fall2015-Module-2-Centrality-Measures.pdf?x61976
网络图的特征
社会网络分析(非224w,实为经济学(简单,复杂的不会,emmm))
1736年,瑞上:的著名数学家欧拉(L.Euler,1707~1783 )用图论方法解决了柯尼斯堡桥问题(Konigsberg Bridge Problem)(参见张贵新,1989:140~146)。他的解决方法是把与该桥相关的数学规念转换为由点和线构成的图形、从而给出相应的证明。
这种观念在数学和很多应用科学领域中得到多次体现。在统计学中,学者们发展出了马尔可夫随机链(Markov random chains);在物理学中,学者们利用图形来理解欧氏空间中相互联络的各个分子之间的关系,即使按照相对论,大尺度空间是弯曲的黎曼空间,也可以利用图论方法研究物理空间结构;在运筹学(operations research)中,人们利用树形图法表达物品的位置以及物资流通的渠道。
图可以有多种类型:条形图、趋势分析图等等,这些作为我们所熟悉的,可以统称为“变量图”,它表征的是变量的频次等属性。而网络社群图,主要由三要素构成:
- 行动者(actors): 比如人组成的网络,班级组成的网络,学校组成的网络。
- 联系(ties): 即线(边),代表着行动者之间的关系,比如维系人和人的社会关系如亲情、友情和爱情,班级内部交流,学校组的5G等等。
- 边界(boundary): 这些行动者和边需要确定一个界限,比如一个地区人口,比如政府单位人员,或者在某种限定条件下做同一件事情的人。
如果一个图符合上述三个要素,那么就是一个社交网络图,作为网络图的一种,它和上一篇中提到的整个图框架是被包含的关系,即它也有无向图和有向图,能用矩阵去表示,但是因为值域不同,所以操作还是有所限制,具体的一个过程见如下导图:

社网图中心性
上节相当于介绍了社会网络图的一个概念与数据准备工作,预先构造关系矩阵,本节即是介绍怎么评价一个网络图的指标,即特征的中心性,这里介绍主要的几种,见如下表格:
| 度数中心性(Degree) | 中间(介性)中心性(betweenness) | 接近中心性(Closeness) | |
|---|---|---|---|
| 绝对点度中心度 | C A D i = d ( i ) = ∑ j X i j C_{ADi}=d\left( i \right) =\sum_j{X}_{ij} CADi=d(i)=j∑Xij | C A B i = ∑ j < k b j k ( i ) = ∑ j < k g j k ( i ) / g j k C_{A B i}=\sum_{j<k} b_{j k}(i)=\sum_{j<k} g_{j k}(i) / g_{j k} CABi=j<k∑bjk(i)=j<k∑gjk(i)/gjk | C A P i − 1 = ∑ j d i j C_{A P i}^{-1}=\sum_{j} d_{i j} CAPi−1=j∑dij |
| 相对点度中心度 | C R D i = d ( i ) / ( n − 1 ) C_{RDi}^{}=d\left( i \right) /\left( n-1 \right) CRDi=d(i)/(n−1) | C R B i = 2 C A B i / [ ( n − 1 ) ( n − 2 ) ] C_{RBi}^{}=2C_{ABi}^{}/\left[ \left( n-1 \right) \left( n-2 \right) \right] CRBi=2CABi/[(n−1)(n−2)] | C R P i − 1 = 2 C A P i − 1 / ( n − 1 ) C_{RPi}^{-1}=2C_{APi}^{-1}/\left( n-1 \right) CRPi−1=2CAPi−1/(n−1) |
| 图的中心势 | C A D = ∑ i ( C A D max − C A D i ) ( n − 1 ) ( n − 2 ) C R D = ∑ i ( C R D max − C R D i ) n − 2 \begin{array}{l}{C_{A D}=\frac{\sum_{i}\left(C_{A D \max }-C_{A D i}\right)}{(n-1)(n-2)}} \\ {C_{R D}=\frac{\sum_{i}\left(C_{R D \max }-C_{R D i}\right)}{n-2}}\end{array} CAD=(n−1)(n−2)∑i(CADmax−CADi)CRD=n−2∑i(CRDmax−CRDi) | C B = 2 ∑ i ( C A B max − C A B i ) / [ ( n − 1 ) 2 ( n − 2 ) ] = 2 ∑ i ( C B B max − C R B i ) / ( n − 1 ) C_B=2\sum_i{\left( C_{AB\max}-C_{ABi} \right)}/\left[ \left( n-1 \right) ^2\left( n-2 \right) \right] =2\sum_i{\left( C_{BB\max}-C_{RBi} \right)}/\left( n-1 \right) CB=2i∑(CABmax−CABi)/[(n−1)2(n−2)]=2i∑(CBBmax−CRBi)/(n−1) | C C = ∑ i ( C R C max ′ − C R C i ′ ) ( n − 2 ) ( n − 1 ) ( 2 n − 3 ) C_{C}=\frac{\sum_{i}\left(C_{R C \max }^{\prime}-C_{R C i}^{\prime}\right)}{(n-2)(n-1)}(2 n-3) CC=(n−2)(n−1)∑i(CRCmax′−CRCi′)(2n−3) |
以及第四种特征向量中心性,对于给定的图 G : = ( V , E ) G:=(V,E) G:=(V,E)和 ∣ V ∣ |V| ∣V∣顶点让 A = ( a v , t ) A=(a_{v},t) A=(av,t)是邻接矩阵,即 a v , t = 1 {\displaystyle a_{v,t}=1} av,t=1 如果顶点 v {\displaystyle v} v链接到顶点 t {\displaystyle t} t吨, 和 a v , t = 0 a v , t = 0 {\displaystyle a_{v,t}=0}a_{v,t} = 0 av,t=0av,t=0,否则相对中心性得分 x v {\displaystyle x_{v}} xv 的顶点 v {\displaystyle v} v可以定义为:
x v = 1 λ ∑ t ∈ M ( v ) x t = 1 λ ∑ t ∈ V a v , t x t {\displaystyle x_{v}={\frac {1}{\lambda }}\sum _{t\in M(v)}x_{t}={\frac {1}{\lambda }}\sum _ {t\in V}a_{v,t}x_{t}} xv=λ1t∈M(v)∑xt=λ1t∈V∑av,txt
这可以用矢量符号重写为特征向量方程,即为:
A x = λ x {\displaystyle \mathbf {Ax} =\lambda \mathbf {x} } Ax=λx
这四种中心性就基本概括了一个网络图所能表示的所有指标或者说信息,它们切断了嘈杂的数据,揭示了需要注意的网络部分,但每种代表的具体含义各不相同,以下为我查找资料的时候对每个中心性做的一些解释:
-
点的度中心性(Degree Centrality): 度中心性仅根据每个节点持有的链接数分配重要性分数,它能告诉我们,每个节点与网络中的其他节点之间有多少直接的“一跳”连接。度中心性是节点连接性的最简单度量。有时将入度(入站链接的数量)和出度(出站链接的数量)视为不同的衡量标准很有用,例如在查看交易数据或帐户活动时。
-
点的近性中心度(Closeness Centrality): 近似中心性根据每个节点与网络中所有其他节点的“接近度”对每个节点进行评分。一个点的近性中心度较高,说明该点到网络中其他各点的距离总体来说较近,反之则较远。假如一个物流仓库网络需要选某个仓库作为核心中转站,需要它到其他仓库的距离总体来说最近,那么一种方法就是找到近性中心度最高的那个仓库。
-
点的介性中心度(Betweenness Centrality): 介数中心性衡量一个节点位于其他节点之间最短路径上的次数。一个点的介性中心度较高,说明其他点之间的最短路径很多甚至全部都必须经过它中转,相当于显示哪些节点是网络中节点之间的“桥梁”。假如这个点消失了,那么其他点之间的交流会变得困难,甚至可能断开(因为原来的最短路径断开了)。一般用于查找影响系统周围流程的个人,但应该谨慎使用,因其可能表明某人对网络中不同的集群拥有权限,如果被hack将造成不可预估的影响。小概率可能只是他们在两个集群的外围。
-
特征向量中心性(eigenvector centrality): 特征向量中心性基于特征值,这意味着实体的价值基于与其相连的实体的价值:后者越高,前者就越高。但与其它三个中心性不同的是,它表示的是实体的重要性,一个实体本身度数中心性高,或介数中心性高,或接近中心性高,其特征向量中心性不一定高。举个例子,如果一个实体 A 连接到许多其他实体,但这些其他实体本身是外围的并且没有进一步连接到其他实体,则实体 A 将具有高度中心性,但特征向量中心性低。因此,具有高特征向量中心性的实体与网络中的突出/流行/重要实体相关联,即使它本身不受欢迎,也可以利用其连接的流行度和影响力。相当于在人类社会网络中,具有影响力的人可以获取到特殊的待遇以及相应的权利。
总结完中心性的定义,会在最后用一个代码实战案例进行实践,感兴趣的还可以看很早之前也算是我所有博客里数据最好的 ucinet网络分析使用总结,这就是专门的一个社会网络分析工具,那么切回正题。
图模型的分类
ES模型图模型
ES随机图模型(Erdös-Renyi Random Graph Model),用于生成无向图,它有两类:
- G n p G_{np} Gnp: 具有 n n n 个节点的无向图,并且每条边 ( u , v ) (u,v) (u,v) 出现的概率符合概率为 p p p 的独立同步分布
- G n m G_{nm} Gnm: 具有n个节点的无向图,随机地均匀地选择 m m m 条边
然后课上又重新回顾了网络图的四种属性,针对该种网络。
The Clustering Coefficient of G n p G_{np} Gnp
回顾一下,聚类系数的计算公式为 C i = 2 e i k i ( k i − 1 ) C_{i}=\frac{2e_{i}}{k_{i}(k_{i}-1)} Ci=ki(ki−1)2ei 其中 e i e_{i} ei 是节点 i i i 的相邻节点之间的边数。因为在 G n p G_{np} Gnp 中边出现的概率符合概率为 p p p 的独立同分布,所以图 G n p G_{np} Gnp 中期望的 e i e_{i} ei 为 E [ e i ] = p k i ( k i − 1 ) 2 \mathbb{E}\left[e_{i}\right]=p \frac{k_{i}\left(k_{i}-1\right)}{2} E[ei]=p2ki(ki−1) 这是因为 k i ( k i − 1 ) 2 \frac {k_{i}(k_{i}-1)} {2} 2ki(ki−1) 是度为 k i k_{i} ki 的节点 i i i 的邻居的不同对的数量,并且每一对以概率 p p p 相连接。
因此,聚类系数的期望为: E [ C i ] = p ⋅ k i ( k i − 1 ) k i ( k i − 1 ) = p = k ˉ n − 1 ≈ k ˉ n \mathbb{E}\left[C_{i}\right]=\frac{p \cdot k_{i}\left(k_{i}-1\right)}{k_{i}\left(k_{i}-1\right)}=p=\frac{\bar{k}}{n-1} \approx \frac{\bar{k}}{n} E[Ci]=ki(ki−1)p⋅ki(ki−1)=p=n−1kˉ≈nkˉ k ˉ \bar{k} kˉ 表示平均度,平均度系数允许我们查看边缘是否在网络的某些部分出现得更密集。从上面公式可以得到, G n p G_{np} Gnp 的聚类系数非常小,如果我们以固定的平均度 生成 k ˉ \bar{k} kˉ 一个非常非常大的图,那么 C C C 随着规模 n n n 的增大而减小。 E [ C i ] → 0 \mathbb{E}\left[C_{i}\right] \rightarrow 0 E[Ci]→0 as n → ∞ n \rightarrow \infty n→∞。
Some Network Properties of G n p G_{np} Gnp
G n p G_{np} Gnp 的度分布符合二项分布,设 P ( k ) P(k) P(k) 表示具有度为 k k k 的节点数,则 P ( k ) = ( n − 1 k ) p k ( 1 − p ) n − 1 − k P(k)=\left(\begin{array}{c} n-1 \\ k \end{array}\right) p^k(1-p)^{n-1-k} P(k)=(n−1k)pk(1−p)n−1−k 二项分布的均值和方差分别为 k ˉ = p ( n − 1 ) \bar{k}=p(n-1) kˉ=p(n−1), σ 2 = p ( 1 − p ) ( n − 1 ) \sigma^{2}=p(1-p)(n-1) σ2=p(1−p)(n−1)
二项式分布的一个特性是,根据数字定律,随着网络规模的增加,分布变得越来越狭窄。
The Path Length of G n p G_{np} Gnp
关于这个我看事后笔记没看懂,又不想回头在翻视频了,因为当时听的时候可能就是以数据结构的理念去听的,这里大致讲一下,要讨论 G n p G_{np} Gnp 的路径长度,需要引入一个扩展系数的概念。即:
α = min S ⊂ V # edges leaving S min ( ∣ S ∣ , ∣ V \ S ∣ ) \alpha=\min _{S \subset V} \frac{\text { \# edges leaving } S}{\min (|S|,|V \backslash S|)} α=S⊂Vminmin(∣S∣,∣V\S∣) # edges leaving S
关于扩展系数的一个重要事实是,在具有 n n n 个节点且扩展系数为 α α α 的图中,对于所有的节点对,将有 O ( ( log n ) / α ) O((\log n)/\alpha) O((logn)/α) 条路径连接他们。它描述了图的任意节点集与剩余节点之间边的数量。
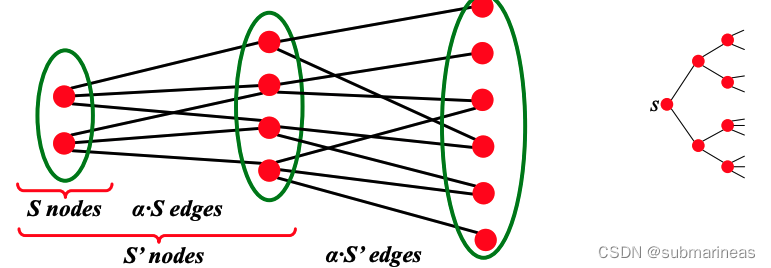
The Connectivity of G n p G_{np} Gnp
下图显示了随机图 G n p G_{np} Gnp 的演变,我们可以看到当平均度 k ˉ = 2 E / n \bar{k}=2E/n kˉ=2E/n 或 p = k ˉ / ( n − 1 ) p=\bar{k}/(n-1) p=kˉ/(n−1) 时,出现了一个巨大的连通组件。
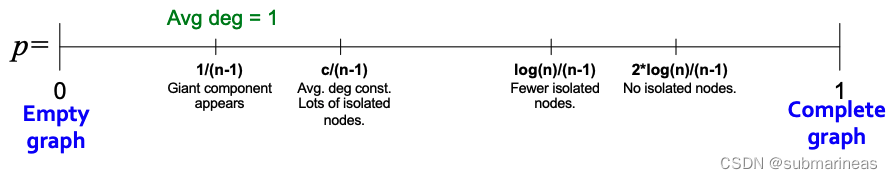
相当于从左到右,数值概率在不断增大,然后图也在发生着改变。然后下一页就是老师做的一个实验,对于10万个节点的图, k = p ( n − 1 ) k=p(n-1) k=p(n−1)从0.5到3对于巨分支的节点占比情况:
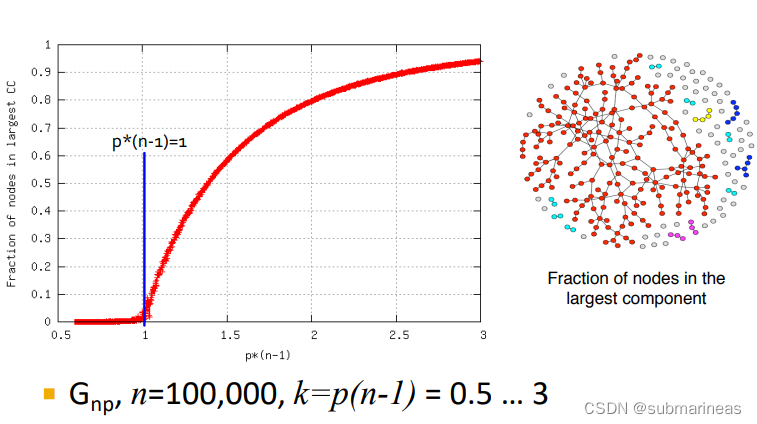
模型对比
而通过该模型网络复习了图的四个概念以及根据该概率图特性做的一些变化后,跟之前的现实模型可以做一个对比,对比图如下:
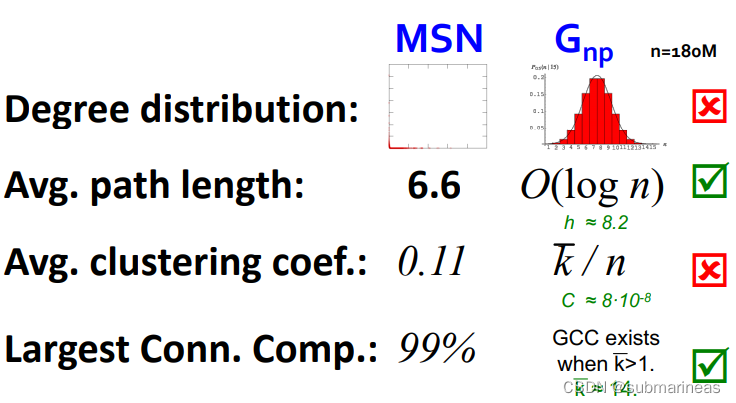
可以看到:
-
优点
- 巨分支所占比例是接近的
- 平均路径长度也比较接近
-
不足
- 度分布差异较大。 现实网络呈现幂律分布,而随机图呈现泊松分布(二项分布)
- 聚类系数相差极大。对于这一属性,这才是应该更关注。
总结一下,随机图模型 G n p G_{np} Gnp很粗糙,对于现实网络的拟合并不好。但是,并不是学习它没有意义,它是后续随机图模型的“迭代”基础。算是地基工程!
随机Kronecker图模型
Kronecker图
随机 Kronecker 图
模型对比
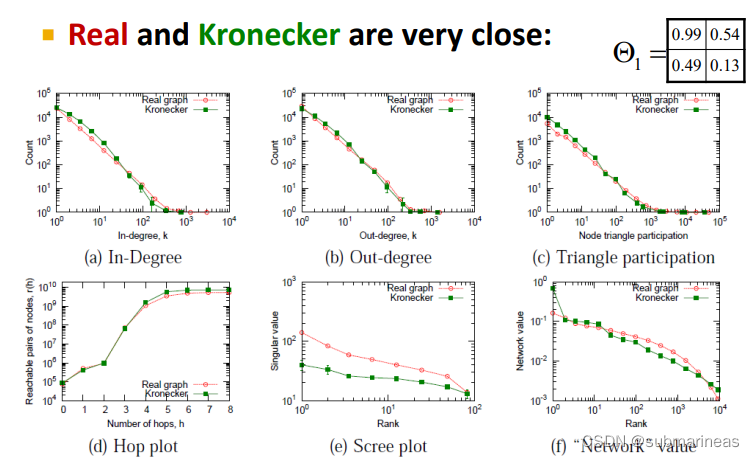
中心性实战
这里主要复现了 苏轼的朋友圈——基于 networkx 进行社交网络分析(SNA) 中的代码与参考了其内容,非常值得推荐。
因为该文是2018年所写,采用的数据库在我查找的时候已经没有了,但所幸,我所使用的2020版本的数据库,与之前的基本一致,以下就是过程。
本次实验与参考环境用的一致,为sqlite,相比于MySQL,它少了事务以及跨主机的复杂功能,但作为优点,就是演示简单,即插即用。而因为我所使用是Linux环境,在Linux中,如果以源码方式编译python,之前一定会经过下载sqlite,即apt-get install libsqlite3-dev,所以一般是默认安装了sqlite,或者可以直接安装anaconda集成环境,就省略了python编译过程。那在确认环境无误后,导入依赖包以及数据库,代码为:
import sqlite3
import numpy as np
import pandas as pd
import networkx as nx
import matplotlib as mpl
import matplotlib.pyplot as plt
plt.style.use('seaborn')
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 数据库文件
db = 'CBDB_20200528.db'
数据来源于 CBDC(China Biographical Database),即中国历代人物传记数据库
去网站上选择download,然后根据所需年份,选择数据库,这里如果用MySQL的话,需要先导入数据库,然后代码层面还需要加一个数据库类,不复杂,但作为一个小demo也有点大材小用,那sqlite就方便多了,直接查询,为:
# 查找 person_id 函数
def getPersonId(person_name):
''' Get person_id
@param person_name: str
@return person_id: str
'''
sql = '''
SELECT c_personid
FROM biog_main
WHERE c_name_chn = '{0}'
'''.format(person_name)
try:
person_id = str(pd.read_sql(sql, con=sqlite3.connect(db)).iloc[0, 0])
return person_id
except:
print("No such person.")
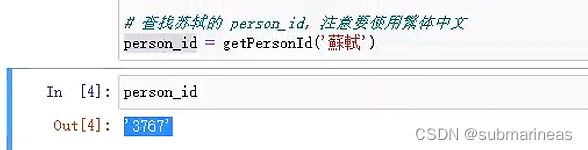
# 查找苏轼的 person_id,注意要使用繁体中文
person_id = getPersonId('蘇軾')
person_id
"""
'3767'
"""
在获得目标人物(苏轼)的 person_id 后,需要通过该 id 在数据库中查找相关记录,得到苏轼与其亲友、及其亲友与其他人的书信往来关系:
sql = '''
SELECT a.c_personid person_id
, b1.c_name_chn person_a
, c_assoc_id assoc_id
, b2.c_name_chn person_b
, a.c_assoc_code assoc_code
, c.c_assoc_desc_chn assoc_desc
FROM assoc_data a
LEFT JOIN biog_main b1
ON a.c_personid = b1.c_personid
LEFT JOIN biog_main b2
ON a.c_assoc_id = b2.c_personid
LEFT JOIN assoc_codes c
ON a.c_assoc_code = c.c_assoc_code
WHERE (a.c_personid = {0}
OR a.c_personid IN (
SELECT c_personid
FROM assoc_data
WHERE c_assoc_id = {0}
AND c_assoc_code IN ('429', '430', '431', '432', '433', '434', '435', '436'))
OR a.c_assoc_id IN (
SELECT c_assoc_id
FROM assoc_data
WHERE c_personid = {0}
AND c_assoc_code IN ('429', '430', '431', '432', '433', '434', '435', '436')))
AND a.c_assoc_code IN ('429', '430', '431', '432', '433', '434', '435', '436')
'''.format(person_id)
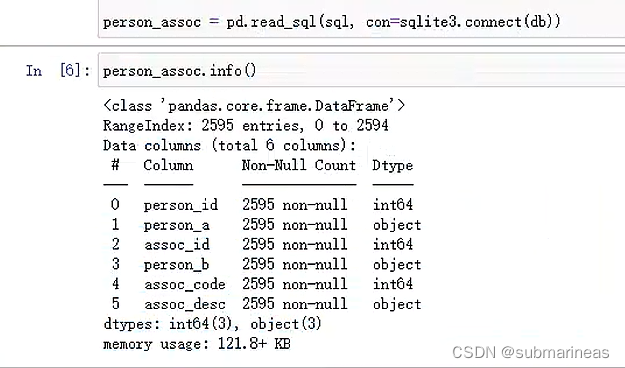
person_assoc = pd.read_sql(sql, con=sqlite3.connect(db))
在对数据库执行了查询操作后,我们将得到一个 DataFrame,其中包括了:
- person_id:关系人A id
- person_a: 关系人A姓名
- assoc_id:关系人B id
- person_b:关系人B姓名
- assoc_code:关系代码
- assoc_desc:关系名称
该 DataFrame 详细信息为:
关系人A或关系人B为苏轼的记录数:
person_assoc[(person_assoc['person_id'] == int(person_id)) | (person_assoc['assoc_id'] == int(person_id))].count()
"""
person_id 550
person_a 550
assoc_id 550
person_b 550
assoc_code 550
assoc_desc 550
dtype: int64
"""
DataFrame 中包含了 8 种关系(均为书信往来关系):
# 打印所有关系的名称
for i in person_assoc['assoc_desc'].unique():
print(i)
"""
致書Y
被致書由Y
答Y書
收到Y的答書
致Y啓
收到Y的啓
答Y啓
收到Y的答啓
"""
据此信息,我们可以将dataframe转网络结构数据,上一节中使用的是nx.read_edgelist,而这里,使用nx.from_pandas_edgelist,具体为:
# 生成图
person_G = nx.from_pandas_edgelist(person_assoc, source='person_a', target='person_b', edge_attr='assoc_desc')
# 打印图信息
print(nx.info(person_G))
print('Density: {0}'.format(nx.density(person_G)))
"""
Graph with 614 nodes and 906 edges
Density: 0.004814257855051517
"""
# 补充,求总的平均度
avg_degree = sum(dict(person_G.degree()).values()) / person_G.number_of_nodes()
"""
Number of nodes: 614
Number of edges: 906
Average degree: 2.9511
"""
# networkx的api求单边平均度
nx.average_degree_connectivity(person_G)
"""
{42: 11.619047619047619,
1: 111.63448275862069,
8: 43.854166666666664,
109: 5.321100917431193,
211: 4.938388625592417,
79: 8.012658227848101,
4: 60.1875,
15: 16.866666666666667,
2: 91.11111111111111,
141: 6.368794326241135,
7: 41.22857142857143,
18: 29.083333333333332,
3: 70.26881720430107,
41: 15.292682926829269,
6: 40.129629629629626,
16: 27.34375,
13: 19.0,
19: 28.63157894736842,
9: 45.22222222222222,
37: 13.91891891891892,
5: 48.8,
14: 33.0,
11: 32.5,
10: 44.95}
"""
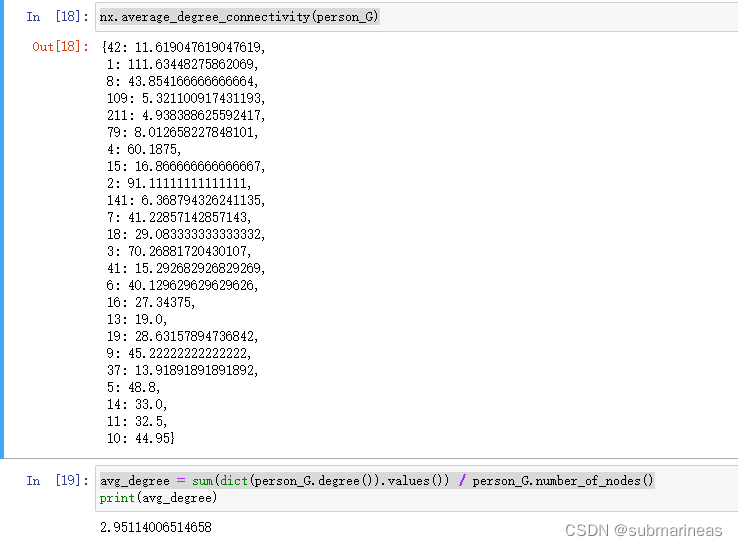
这里因为参考中打印结果与代码不一致,其中节点的度、边以及总平均度没有,所以我根据输出结果反推了一下代码,顺带找到了networkx中的节点平均度,打印了一下输出。图中描述了 906 个关系,其中包含 614 个唯一个体。苏轼的社交网络中的随机个体在社交网络的其余部分平均有近 3 个联系人。由于存在大量与苏轼亲友有书信往来的但与苏轼本人无关系的记录,整个社会网络的密度较低。
基于以上数据分析,对于数据的构成我们已经有一个大致的概括,所以接下来就能直接挖掘特征,这里输出本篇一直在介绍的中心性指标:
person_betweenness = pd.Series(nx.betweenness_centrality(person_G), name='Betweenness')
person_person = pd.Series.to_frame(person_betweenness)
person_person['Closeness'] = pd.Series(nx.closeness_centrality(person_G))
person_person['PageRank'] = pd.Series(nx.pagerank_scipy(person_G))
person_person['eigenvector'] = pd.Series(nx.eigenvector_centrality(person_G))
person_person['Degree'] = pd.Series(dict(nx.degree(person_G)))
desc_betweenness = person_person.sort_values('Betweenness', ascending=False)
desc_betweenness.head(10)
相比于参考的那篇,这里多加了一个eigenvector,即特征向量中心性,其实没有多大必要,因为PageRank可以看成是该中心性的一种特殊形式,不过为了更为直观,我顺带就一起输出了:
| Betweenness | Closeness | PageRank | eigenvector | Degree | |
|---|---|---|---|---|---|
| 蘇軾 | 0.591204 | 0.603941 | 0.111023 | 0.548464 | 211 |
| 歐陽修 | 0.317891 | 0.533507 | 0.070228 | 0.332594 | 141 |
| 黃庭堅 | 0.257789 | 0.475562 | 0.063531 | 0.181748 | 109 |
| 王安石 | 0.146049 | 0.457122 | 0.038774 | 0.189438 | 79 |
| 畢仲游 | 0.086661 | 0.434444 | 0.022120 | 0.106569 | 42 |
| 司馬光 | 0.078387 | 0.456441 | 0.020660 | 0.134297 | 41 |
| 韓琦 | 0.054205 | 0.430175 | 0.016937 | 0.115450 | 37 |
| 張耒 | 0.026246 | 0.418716 | 0.008772 | 0.082129 | 18 |
| 米芾 | 0.023558 | 0.385535 | 0.007968 | 0.047532 | 15 |
| 張方平 | 0.022055 | 0.452399 | 0.007934 | 0.107940 | 18 |
最后,对该数据进行可视化,在绘制可视化图形前,需要提前创建一致的图形布局,这里选用了 kamada_kawai_layout 的图形布局:
#pos = nx.circular_layout(person_G)
pos = nx.kamada_kawai_layout(person_G)
#pos = nx.shell_layout(person_G)
#pos = nx.spring_layout(person_G)
#pos = nx.random_layout(person_G)
绘制图形的函数:
# 绘制函数
def draw_graph(df, top):
''' Draw Graph
@param df: DataFrame
@param top: int, numbers of top
'''
nodes = df.index.values.tolist() #生成节点列表
edges = nx.to_edgelist(person_G) #生成边列表
# 生成无向度量图
metric_G = nx.Graph()
metric_G.add_nodes_from(nodes)
metric_G.add_edges_from(edges)
# 生成 Top n 的标签列表
top_labels = {
}
for node in nodes[:top]:
top_labels[node] = node
# 生成节点尺寸列表
node_sizes = []
for node in nodes:
node_sizes.append(df.loc[node]['Degree'] * 16 ** 2)
# 设置图形尺寸
plt.figure(1, figsize=(64, 64))
# 绘制图形
nx.draw(metric_G, pos=pos, node_color='#cf1322, with_labels=False)
nx.draw_networkx_nodes(metric_G, pos=pos, nodelist=nodes[:top], node_color='#a8071a', node_size=node_sizes[:top])
nx.draw_networkx_nodes(metric_G, pos=pos, nodelist=nodes[top:], node_color='#a3b1bf', node_size=node_sizes[top:])
nx.draw_networkx_edges(metric_G, pos=pos, edgelist=edges, edge_color='#d9d9d9', arrows=False)
nx.draw_networkx_labels(metric_G, pos=pos, font_size=20, font_color='#555555')
nx.draw_networkx_labels(metric_G, pos=pos, labels=top_labels, font_size=28, font_color='#1890ff')
# 保存图片
plt.savefig('tmp.png')
draw_graph(desc_betweenness, 20)
上述代码为生成网络图,图中的每个节点都对应苏轼朋友圈中的一个人,而在朋友圈中与苏轼最亲近的 20 个人的节点以红底蓝字突出显示,节点大小对应程度大小:
参考与推荐
[1]. https://snap-stanford.github.io/cs224w-notes/preliminaries/measuring-networks-random-graphs
[2]. https://github.com/TommyZihao/zihao_course/blob/main/CS224W/2-tradition-ml.md
[3]. ucinet网络分析使用总结
[4]. 知乎社交网络分析(上):基本统计
[5]. https://en.wikipedia.org/wiki/Eigenvector_centrality
[6]. CS224W 学习笔记
[7]. Few but good
The eigenvector centrality and its meaning