语音增强之谱减法
原理介绍
谱减法 (Spectral Subtraction) 是最早出现的语音增强算法之一,由于实现简单且实时性较好,获得了广泛的应用。它假设语音和噪声是加性混合,且噪声是缓慢变化的,通过在静音段估计和更新噪声频谱,从带噪语音谱中减去噪声来增强语音。
设 y ( n ) y(n) y(n) 为带噪语音信号,由纯净语音信号 x ( n ) x(n) x(n) 和 噪声信号 d ( n ) d(n) d(n) 混合形成
y ( n ) = x ( n ) + d ( n ) y(n)=x(n)+d(n) y(n)=x(n)+d(n)
对等式两边做傅里叶变换转换到频域
Y ( ω ) = X ( ω ) + D ( ω ) Y(\omega)=X(\omega)+D(\omega) Y(ω)=X(ω)+D(ω)
Y ( ω ) Y(\omega) Y(ω)也可以表示成极坐标形式
Y ( ω ) = ∣ Y ( ω ) ∣ e j ϕ y ( ω ) Y(\omega)=|Y(\omega)|e^{j\phi_{y}(\omega)} Y(ω)=∣Y(ω)∣ejϕy(ω)
其中 ∣ Y ( ω ) ∣ |Y(\omega)| ∣Y(ω)∣为幅度谱, ϕ y ( ω ) \phi_{y}(\omega) ϕy(ω)为相位谱, D ( ω ) D(\omega) D(ω)也可以表示成 D ( ω ) = ∣ D ( ω ) ∣ e j ϕ d ( ω ) D(\omega)=|D(\omega)|e^{j\phi_{d}(\omega)} D(ω)=∣D(ω)∣ejϕd(ω),谱减法是在幅度谱上进行的, ∣ D ( ω ) ∣ |D(\omega)| ∣D(ω)∣无法获得,但是可以用静音段(无语音活动的片段)的平均频谱进行估计和更新,由于相位对于语音的可懂度和质量影响较小,所以用带噪相位 ϕ y ( ω ) \phi_{y}(\omega) ϕy(ω)来代替,纯净语音谱的估计为
X ^ ( ω ) = ( ∣ Y ( ω ) ∣ − ∣ D ^ ( ω ) ∣ ) e j ϕ y ( ω ) \hat{X}(\omega)=(|Y(\omega)|-|\hat{D}(\omega)|)e^{j\phi_{y}(\omega)} X^(ω)=(∣Y(ω)∣−∣D^(ω)∣)ejϕy(ω)
对估计结果做傅里叶逆变换即可得到增强后的语音。上述的 ∣ Y ( ω ) ∣ − ∣ D ^ ( ω ) ∣ |Y(\omega)|-|\hat{D}(\omega)| ∣Y(ω)∣−∣D^(ω)∣过程可能会产生负的幅度值,这显然是有问题的,早期的做法是通过半波整流将负值直接置零
∣ X ^ ( ω ) ∣ = { ∣ Y ( ω ) ∣ − ∣ D ^ ( ω ) ∣ if ∣ Y ( ω ) ∣ > ∣ D ^ ( ω ) ∣ 0 else |\hat{X}(\omega)|=\begin{cases} |Y(\omega)|-|\hat{D}(\omega)| & \text{ if } |Y(\omega)|>|\hat{D}(\omega)| \\ 0 & \text{ else } \end{cases} ∣X^(ω)∣={
∣Y(ω)∣−∣D^(ω)∣0 if ∣Y(ω)∣>∣D^(ω)∣ else
谱减法可以拓展到功率谱,假定 d ( n ) d(n) d(n)为零均值,且 d ( n ) d(n) d(n)和 x ( n ) x(n) x(n)不相关,由幅度谱减公式两边平方,去掉交叉项后得到
∣ X ^ ( ω ) ∣ 2 = ∣ Y ( ω ) ∣ 2 − ∣ D ^ ( ω ) ∣ 2 |\hat{X}(\omega)|^{2}=|Y(\omega)|^{2}-|\hat{D}(\omega)|^{2} ∣X^(ω)∣2=∣Y(ω)∣2−∣D^(ω)∣2
∣ X ^ ( ω ) ∣ 2 |\hat{X}(\omega)|^{2} ∣X^(ω)∣2也可能出现负值,可用前述的半波整流方法处理,上式也可以写成:
∣ X ^ ( ω ) ∣ 2 = H 2 ( ω ) ∣ Y ( ω ) ∣ 2 |\hat{X}(\omega)|^{2}=H^{2}(\omega)|Y(\omega)|^{2} ∣X^(ω)∣2=H2(ω)∣Y(ω)∣2
其中
H ( ω ) = 1 − ∣ D ^ ( ω ) ∣ 2 ∣ Y ( ω ) ∣ 2 H(\omega)=\sqrt{1-\frac{|\hat{D}(\omega)|^{2}}{|Y(\omega)|^{2}} } H(ω)=1−∣Y(ω)∣2∣D^(ω)∣2
H ( ω ) H(\omega) H(ω)为增益函数或抑制函数,取值范围为 0 ≤ H ( ω ) ≤ 1 0\le H(\omega) \le 1 0≤H(ω)≤1。
综上,谱减法更通用的形式可定义为
∣ X ^ ( ω ) ∣ p = ∣ Y ( ω ) ∣ p − ∣ D ^ ( ω ) ∣ p |\hat{X}(\omega)|^{p}=|Y(\omega)|^{p}-|\hat{D}(\omega)|^{p} ∣X^(ω)∣p=∣Y(ω)∣p−∣D^(ω)∣p
缺点和改进
谱减法最显著的缺点是会引入“音乐噪声”,由于谱减过程中可能出现负的幅度值,半波整流是一种直接的解决办法,但是这种非线性处理会导致频谱随机频率位置上出现小的、独立的峰值,在时域中表现为明显的多频颤音,也称为“音乐噪声”。如果处理不当,在某些语音段,“音乐噪声”的影响甚至比干扰噪声更为明显。造成“音乐噪声”的常见原因有:
- 对谱减过程中负值的非线性处理。
- 噪声谱估计不匹配。静音段的平均噪声谱可能与实际语音段的噪声分量有着较大差别,相减后会有残留的孤立噪声段。
- 谱估计方法的误差。例如周期图等有偏功率谱估计方法带来的偏差。
- 抑制函数有较大的可变性。
为了减小音乐噪声,学者们提出了一系列的改进方法,感兴趣的读者可以自行了解。这里介绍Boll使用的方法,相比直接置零,该方法设置了一个谱值下限。在噪声估计阶段,计算一个最大噪声帧,如果谱减后某时频点的值小于最大噪声帧的对应频点值,则将其替换为相邻帧的最小值。具体可表示为:
∣ X i ^ ( ω ) ∣ = { ∣ Y i ( ω ) ∣ − ∣ D ^ ( ω ) ∣ if ∣ Y i ( ω ) ∣ − ∣ D ^ ( ω ) ∣ > m a x ∣ D ^ ( ω ) ∣ min j = i − 1 , i , i + 1 ∣ X i ^ ( ω ) ∣ else |\hat{X_{i}}(\omega)|=\begin{cases} |Y_{i}(\omega)|-|\hat{D}(\omega)| & \text{ if } |Y_{i}(\omega)|-|\hat{D}(\omega)| > max|\hat{D}(\omega)| \\ \underset{j=i-1,i,i+1}{\min} |\hat{X_{i}}(\omega)| & \text{ else } \end{cases} ∣Xi^(ω)∣={
∣Yi(ω)∣−∣D^(ω)∣j=i−1,i,i+1min∣Xi^(ω)∣ if ∣Yi(ω)∣−∣D^(ω)∣>max∣D^(ω)∣ else
其中 ∣ X i ^ ( ω ) ∣ |\hat{X_{i}}(\omega)| ∣Xi^(ω)∣表示第i帧估计得到的增强谱,该方法的思想在于检测到当前帧能量较低时,则保持语音信息,因此可以减小音乐噪声。但由于需要用到下一帧的信息,该方法的实时性会降低。
代码实现
这里给出Boll改进方法的matlab仿真代码。数据采样率为8kHz,噪声类型为白噪声,输入信噪比5dB。
addpath('./STFT')
clc
clear all
close all
[x,fs]=audioread('s2.wav'); %读取纯净语音信号
[d,fs]=audioread('white.wav'); %读取噪声信号
x=x(1:fs*10);
d=d(1:fs*10);
nfft=256;
stepsize=0.5;
snr=5;
d=sqrt(norm(x)^2/(10^(snr/10)*norm(d)^2))*d; %考虑信噪比
y=[zeros(fs*1,1);x(1:fs*9)]+d(1:fs*10); %生成带噪信号,前1s 为纯噪声段
Y=stft(y,nfft,stepsize*nfft,1);%带噪信号的时频谱
Ya=abs(Y);%幅度谱
Yp=angle(Y);%相位谱
Xa=zeros(size(Ya));
%带噪语音谱平滑
Ys=Ya;
for i=2:(size(Ya,2)-1)
Ys(:,i)=(Ya(:,i-1)+Ya(:,i)+Ya(:,i+1))/3;
end
N=mean(Ya(:,1:10),2); %噪声谱初始化 使用前0.32s的纯噪声段
N_max=zeros(size(N)); %最大噪声残留初始化
alpha=0.9;%噪声谱更新 平滑系数
beta=0.03;
%静音段噪声谱估计和更新
for i=1:floor(fs/256)
N=alpha*N+(1-alpha)*Ya(:,i);
N_max=max(N_max,Ya(:,i)-N);
Xa(:,i)=beta*Ya(:,i);
end
%带噪语音段降噪
for i=(floor(fs/256)+1):size(Y,2)-1
X1=Ys(:,i)-N; %语音谱的初始估计
for j =1:length(X1)
if X1(j)<N_max(j)
X1(j)=min(X1(j),min(Ys(j,i-1)-N(j),Ys(j,i+1)-N(j)));
end
end
Xa(:,i)=max(X1,0);
end
Xa(:,end)=max(Ys(:,end)-N,0);
%反变换得到增强语音
X=Xa.*exp(1i*Yp);
x_est=istft(X,nfft,stepsize*nfft,1);
figure
subplot(311)
plot((0:length(x)-1)/fs,[zeros(fs,1);x(1:fs*9)]);
title('纯净语音')
subplot(312)
plot((0:length(y)-1)/fs,y);
title('带噪语音')
subplot(313)
plot((0:length(x_est)-1)/fs,x_est);
title('增强语音')
figure
subplot(311)
spectrogram(x(1:fs*9),hann(256),50,256,fs,'yaxis')
title('纯净语谱图')
subplot(312)
spectrogram(y(fs+1:end),hann(256),50,256,fs,'yaxis')
title('带噪语谱图')
subplot(313)
spectrogram(x_est(fs+1:end),hann(256),50,256,fs,'yaxis')
title('增强语谱图')
仿真结果
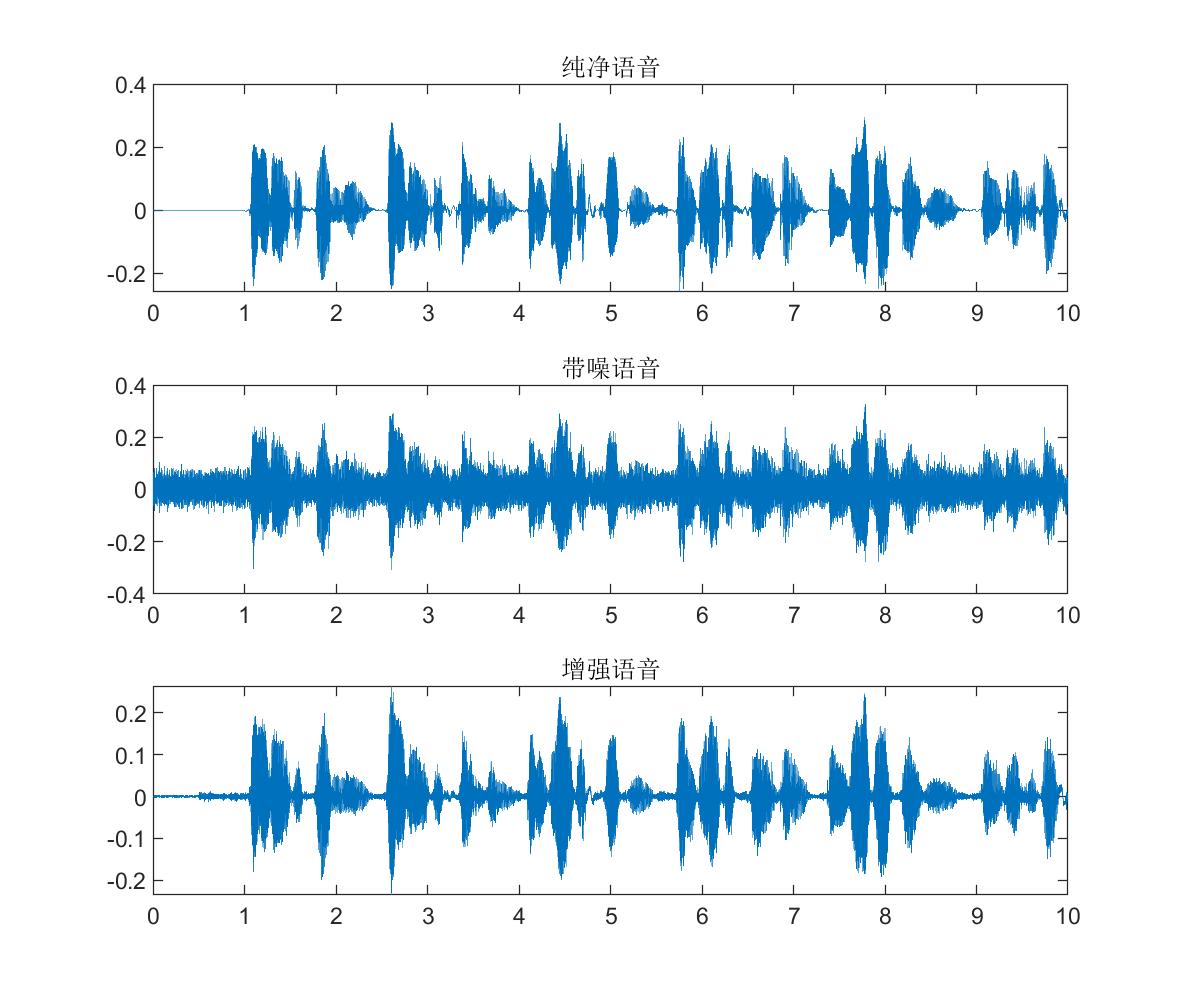
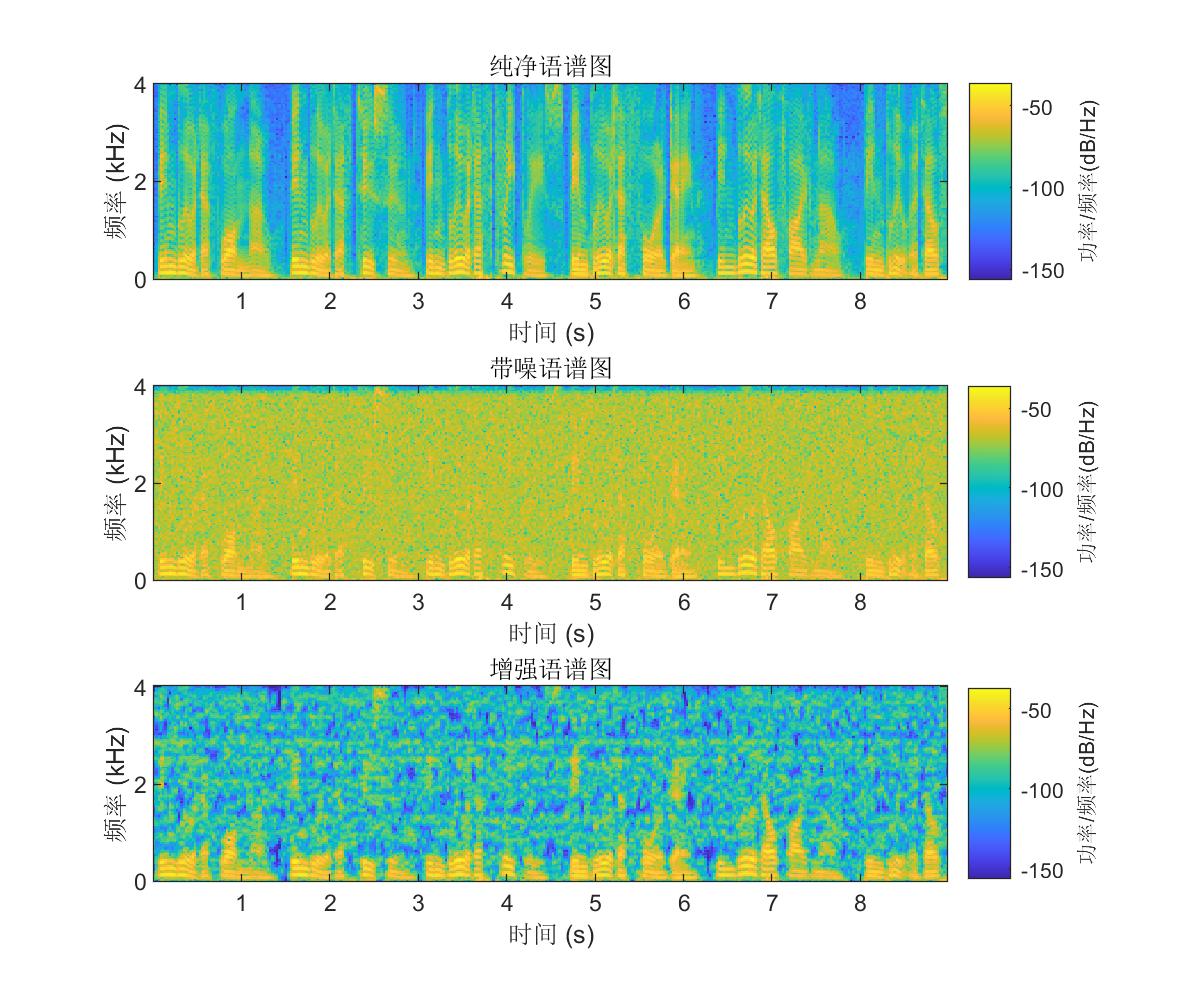
由图中可以看出纯净语音的时域波形有明显的谐波细节,语谱图的能量主要集中在低频;添加噪声污染后,语音的波形细节被淹没,语谱图时频点也变得模糊;经过谱减法增强后,波形得到了明显的恢复,语谱图的噪声点被抑制,同时低频特征得到了保留,不过中高频的一些本属于语音的时频点也有不同程度的削减,也就是常说的语音失真。如何最大程度的抑制噪声,同时减小失真,是语音增强的一大难点,也是学者们不断研究的方向。
参考文献
[1] Philipos C.Loizou. 语音增强:理论与实践:theory and practice[M]. 电子科技大学出版社, 2012.
[2] Boll S. Suppression of acoustic noise in speech using spectral subtraction[J]. IEEE Transactions on acoustics, speech, and signal processing, 1979, 27(2): 113-120