简易版:
from urllib.request import urlopen
from bs4 import BeautifulSoup
from urllib.error import HTTPError
import re
import requests
headers = {
'User-Agent': 'Mozilla/5.0(WindowsNT10.0;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/109.0.0.0Safari/537.36'
}
def save_file(save_path,content):
with open(save_path,'w+',encoding='utf8') as f:
f.write(content)
def getLinks(url):
#1、获取网页HTML源代码
html = requests.get(url,headers=headers)
bs = BeautifulSoup(html.content,'html.parser')
#2、解析HTML,获取病例链接
links = bs.find_all('a',{'href':re.compile('https:\/\/jbk\.39\.net\/[a-z]*[0-9]*\/$')})
links.pop(0)
links.pop()
links.pop()
for link in links:
try:
url2 = link.attrs['href']+'jbzs/'
except HTTPError as e:
print(e)
html2 = requests.get(url2, headers=headers)
bs2 = BeautifulSoup(html2.content, 'html.parser')
introductions = bs2.find_all('p',{'class':'introduction'})
name = bs2.find_all('h1')
for i in introductions:
#print(name[0].get_text()+':'+i.get_text())
save_path = '../files/{}.txt'.format(name[0].get_text())
content = i.get_text()
save_file(save_path,content)
if __name__ == "__main__":
url='https://jbk.39.net/bw/huxineike/'
try:
getLinks(url)
except:
print("爬取异常中断!")
print("数据获取完毕!")

高级版:
from urllib.request import urlopen
from urllib.error import HTTPError,URLError
from bs4 import BeautifulSoup
import requests
import time
import random
import re
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/109.0.0.0 Safari/537.36'}
def save_file(page_content,save_path):
f = open(save_path,'w+',encoding='utf-8')
f.write(page_content)
f.close()
#在综合页面https://jbk.39.net/bw/p{}'.format(i)获取病例链接
def getLink(url):
#获取网页内容
html=requests.get(url,headers=headers)
bs = BeautifulSoup(html.content,'html.parser')
#获取病例名称链接
nameLink = bs.find_all('a',{'href':re.compile('https:\/\/jbk.39.net\/[a-z]*[0-9]*\/$')})
#将不合理的链接弹出
nameLink.pop(0)
nameLink.pop()
nameLink.pop()
#打印正确的链接
list=[]
for link in nameLink:
list.append(link['href'])
return list
#通过链接获取我们想得到的数据
def getDetails(links):
i=0
for link in links:
page = ''
link_details=link+'jbzs/'
link_symptom=link+'zztz/'
#print(link_details)
#print(link_symptom)
#打开连接
html=requests.get(link_details,headers=headers)
#获取源码
bs = BeautifulSoup(html.content,'html.parser')
# 数据解析*************************************************************
# 获取名称
name1 = bs.find_all('h1')[0].get_text()
name2 = bs.find_all('h2')[0].get_text()
#print("病例名称:"+name1)
page += name1 + '\n'
#print("病例别名:" + name2)
page += name2 + '\n'
# 获取简介
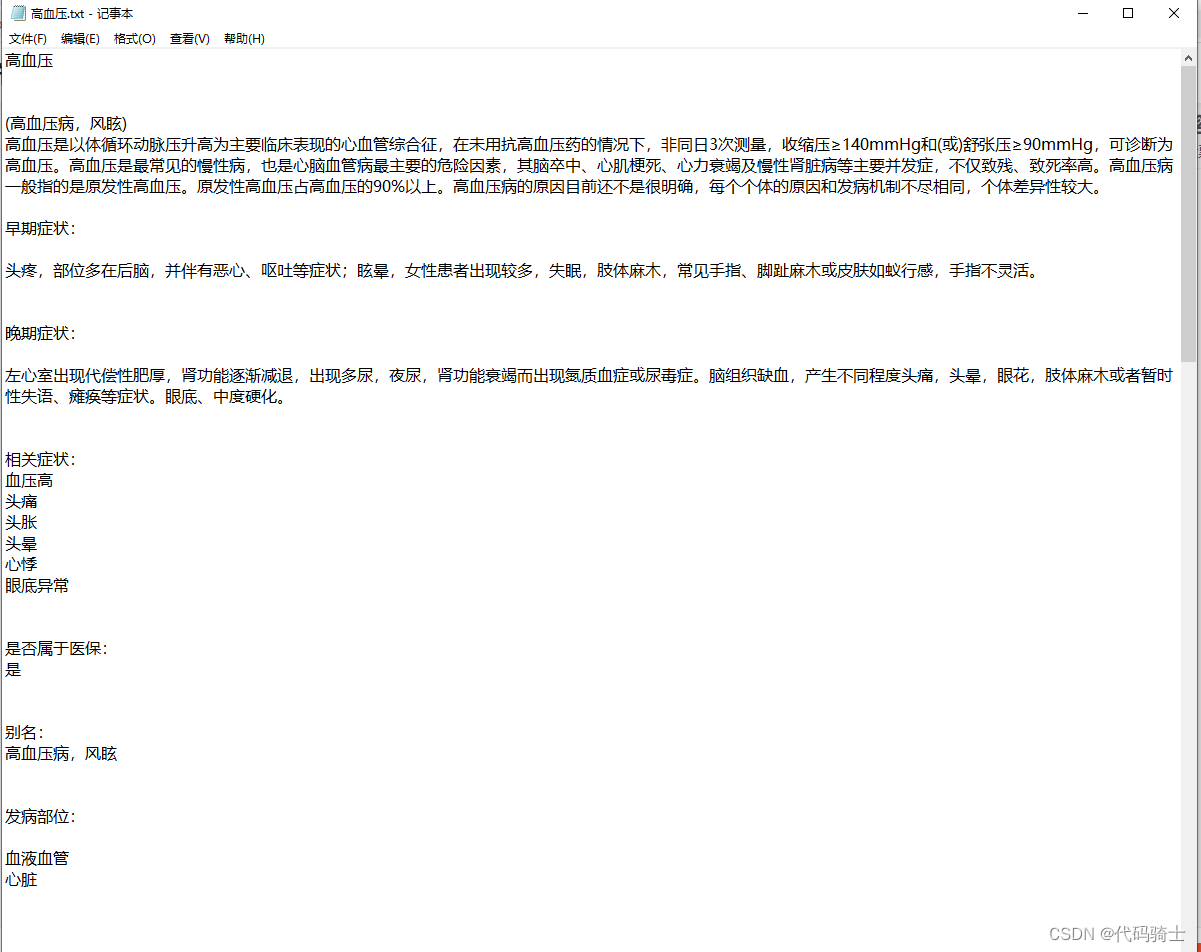
introduction = bs.find_all('p',{'class':'introduction'})[0].get_text()
#print("简介:"+introduction)
page += introduction + '\n'
# 获取症状
htmls = requests.get(link_symptom,headers=headers)
sy = BeautifulSoup(htmls.content,'html.parser')
symbol = sy.find_all('p',{'class':'article_text'})
try:
symbols = symbol[0].get_text().replace(' ','')+symbol[1].get_text().replace(' ','')+symbol[2].get_text().replace(' ','')
except:
try:
symbols = symbol[0].get_text().replace(' ','')+symbol[1].get_text().replace(' ','')
except:
symbols = symbol[0].get_text().replace(' ', '')
#print('症状:'+symbols)
page += symbols + '\n'
#其他信息
insurance = '' # 医保
position = '' # 部位
infection = '' # 传染性
crowd = '' # 多发人群
department = '' # 科室
period = '' # 治疗周期
method = '' # 治疗方法
drug = '' # 治疗药物
others = bs.find_all('li')
for o in others[23:45]:
page += o.get_text()+'\n'
print(page)
save_path= '../case/{}.txt'.format(name1)
save_file(page, save_path)
print("-----------------------------第%d条已经爬取----------------------------"%(i+1))
i+=1
if __name__ == "__main__":
links=[]
#获取到的连接存放在links列表中
for i in range(6,8):#页数(b-a)页
time.sleep(random.randint(1,3))#延时
url='https://jbk.39.net/bw/p{}'.format(i)
links = links + getLink(url)
#print(links)
#通过链接获取详情内容
getDetails(links)