动手学深度学习是李沐教授在哔哩哔哩上发布的专栏视频,专栏链接如下:
https://space.bilibili.com/1567748478/channel/seriesdetail?sid=358497
本专栏主要是我按照自己的学习过程结合教材进行总结复习。
目录
安装jupyter、d2l、torch、torchvision
安装jupyter、d2l、torch、torchvision
深度学习介绍
日常中的机器学习
人工智能、机器学习和深度学习之间的关系
目前很难有明确的定义去区分三者。很容易理解的是:
人工智能是:人工智能是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门技术科学,是一门独立的学科。
机器学习是:能够随着数据量的增加不断改进性能的算法程序
深度学习是:利用更复杂的模型,多层神经网络从数据中学习

深度学习的过程理解
比如我们需要进行语音唤醒词识别,我们不需要开发出一款“明确”能够识别出语音的程序。我们只需要利用深度学习——设计出一个算法,通过给算法“喂”大量的数据集,让它自己去选择合适的参数,调整程序的行为即可。
这里涉及到几个术语:
参数:可以理解为可以控制程度的旋钮开关,并不是开到越大越好(比如水龙头,开得太大会溅一身水),而是要选择一个合适的开关程度。
模型:任一调整参数后的程序,我们称为模型(model)
模型族:通过调整参数而生成的所有不同模型的集合称为“模型族”
学习算法:使用数据集来选择参数的元程序被称为学习算法
在深度学习中,学习(learning)是一个训练模型的过程。 通过这个过程,我们可以发现正确的参数集,从而使模型强制执行所需的行为。 换句话说,我们用数据训练(train)我们的模型。 训练过程通常包含如下步骤:
从一个随机初始化参数的模型开始,这个模型基本不能满足我们理想的需求。
获取一些数据样本称为训练集(例如,语音唤醒词所需要的音频片段及{包含、不包含}标签)。
调整参数,使模型在这些样本中表现得更好。
重复第2步和第3步,直到模型在训练集中的表现令你满意

关键组件
数据
数据是深度学习的核心,深度学习需要靠数据来进行模型的优化。所以数据要尽可能的多且正确!
数据集是模型训练所需要的数据的集合
数据即是数据集中一个一个的样本。这些样本大多时候都遵循 独立同分布。
每个样本有一些属性(比如学生有学号、专业、院系等属性),这些属性在深度学习中称为特征。
而监督学习就是选取其中一个特征称为目标或标签,用剩余的样本特征来进行预测。
模型
模型的定义在上面已给出:调整参数后的程序。
深度学习与以往研究极大地不同就是模型的更加复杂:由许多神经网络层所组成
目标函数
用来评价模型的好坏,目标函数其值一般是越小越好,因此又被称为损失函数。
常见的目标函数:
监督学习中预测数值——平方误差目标函数
监督学习中的图像分类预测——交叉熵目标函数
一般我们将数据集分为训练集和测试集(有的还有验证集,用来进一步调参使模型的效果更好),训练集是用来寻找较好的参数来调整模型,测试集则是评估模型的好坏,所以一般我们看的都是测试集上的loss值
优化算法
优化算法是用来搜索最佳的参数的算法,目前大多数优化算法都是基于梯度下降的方法——在每个步骤中,梯度下降法都会检查每个参数,看看如果你仅对该参数进行少量变动,训练集损失会朝哪个方向移动。 然后,它在可以减少损失的方向上优化参数。
常见的机器学习问题
监督学习
监督学习即是给定需要的输入特征能够预测标签的深度学习问题。监督学习所解决的问题可以通俗的形容为:在给定一组特定的可用数据的情况下,估计某事物的概率。比如:
- 根据若干天的股票开盘价变化,预测未来几天的股票开盘价——序列学习
- 根据给定的花朵图片,预测其种类——分类
- 在给定的图片中有许多生物,标出其可能是哪种生物——标记问题
监督学习中的数据集通常都是“输入特征—标签对”
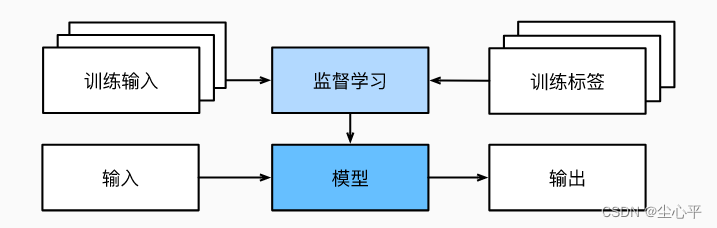
监督学习学习过程
回归
回归是监督学习中的预测标签是数值的问题,一般都是预测“多少”的问题
回归问题中一般采用最小化平方误差损失函数
分类
分类是监督学习中的预测标签是哪一类别的问题,一般都是预测“哪一个哪一种”的问题,比如之前深度学习博客所做的MNIST手写数字识别(映射到0-9类别)、天气类别、花朵分类等问题。
分类问题根据给定的训练集的标签种类数可以分为二元分类问题和多元分类问题
分类问题中一般采用交叉熵损失函数
标记问题
标记问题又称为多标签分类问题,与分类问题很像,不同的是标记问题的给定特征中(如图片)存在多个类别且互不冲突,而分类问题的给定特征中只有一个类别
如下面图片,需要标记出每个是什么:

搜索
在信息检索领域我们需要对给定关键字所对应的各个结果进行一个排序,这个排序可能是基于时效性、点击率等等。监督学习中的搜索则是给定最近一段时间的点击率或者其他特征给出这样一个排序
推荐系统
推荐系统和搜索很像,只不过考虑的因素不再聚焦于点击率而是用户个性化的喜好
序列学习
序列学习是深度学习一个十分重要的方向,因为存在大量的数据集内的数据样本不是孤立的,之间有一定的联系,这种数据集的训练就需要通过序列学习来解决。
具体介绍可见博客 深度学习——循环神经网络RNN_尘心平的博客-CSDN博客
无监督学习
监督学习给定了大量的数据以及要预测什么,而无监督学习只给定了数据并没有给出要做什么。
无监督学习的相关问题主要有:
聚类问题:在没有标签的情况下类的划分。比如,给定一组照片,我们能把它们分成风景照片、狗、婴儿、猫和山峰的照片吗?同样,给定一组用户的网页浏览记录,我们能否将具有相似行为的用户聚类呢?
主成分分析问题:找到少量的参数来准确地捕捉数据的线性相关属性。比如,一个球的运动轨迹可以用球的速度、直径和质量来描述。
因果关系和概率图模型问题:描述观察到的许多数据的根本原因。例如,有了房价、地理位置、教育资源、生态资源,我们能否描述这些特征之间的影响关系
生成对抗性网络:提供一种合成数据的方法,甚至像图像和音频这样复杂的非结构化数据。潜在的统计机制是检查真实和虚假数据是否相同的测试,它是无监督学习的另一个重要而令人兴奋的领域。
与环境互动和强化学习
上述的深度学习研究是孤立于环境的,即不需要从环境中获取什么,也不对周围环境有什么改变,称之为离线学习。
与环境互动类似Alpha Go,下棋过程中需要捕获棋盘上的信息,进行可能的解棋路线的预测取得分高的预测路线,然后在棋盘中做出举措,接着再捕获棋盘上的信息直至胜利或失败。
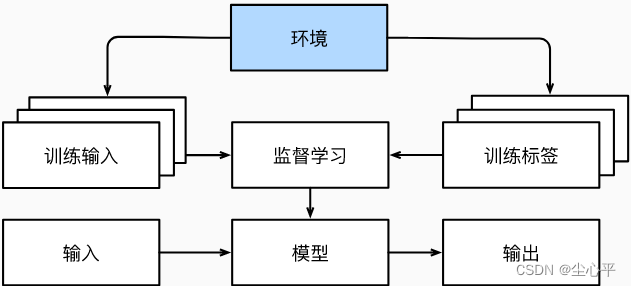
与环境互动的学习过程 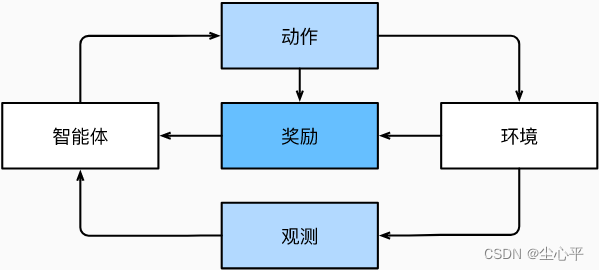
强化学习与环境之间的作用 强化学习即是Alpha Go的学习框架。这个框架十分强大,我们可以把任何监督学习转换为强化学习去解决:假设我们有一个分类问题,我们可以创建一个强化学习agent,每个分类对应一个“动作”。 然后,我们可以创建一个环境,该环境给予agent的奖励。 这个奖励与原始监督学习问题的损失函数是一致的。它也可以解决许多监督学习解决不了的问题。
一般的强化学习问题是一个非常普遍的问题。 agent的动作会影响后续的观察,而奖励只与所选的动作相对应。 环境可以是完整观察到的,也可以是部分观察到的,解释所有这些复杂性可能会对研究人员要求太高。 此外,并不是每个实际问题都表现出所有这些复杂性。 因此,学者们研究了一些特殊情况下的强化学习问题。
当环境可被完全观察到时,我们将强化学习问题称为马尔可夫决策过程(markov decision process)。 当状态不依赖于之前的操作时,我们称该问题为上下文赌博机(contextual bandit problem)。 当没有状态,只有一组最初未知回报的可用动作时,这个问题就是经典的多臂赌博机(multi-armed bandit problem)。
软件安装
软件安装这里我以Ubuntu和Windows两种环境为例进行介绍
Ubuntu
命令行安装miniconda
- apt更新
sudo apt update sudo apt upgrade
- 官网复制链接并下载
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh
- 安装miniconda
bash Miniconda3-latest-Linux-x86_64.shbash后面的名称和链接最后一个/后一致

安装必要的开发工具
sudo apt install build-essential
安装python3和pip
可以利用conda创建虚拟环境,也可以选择本地安装,Ubuntu以本地安装为例
sudo apt install python3 sudo apt install pip
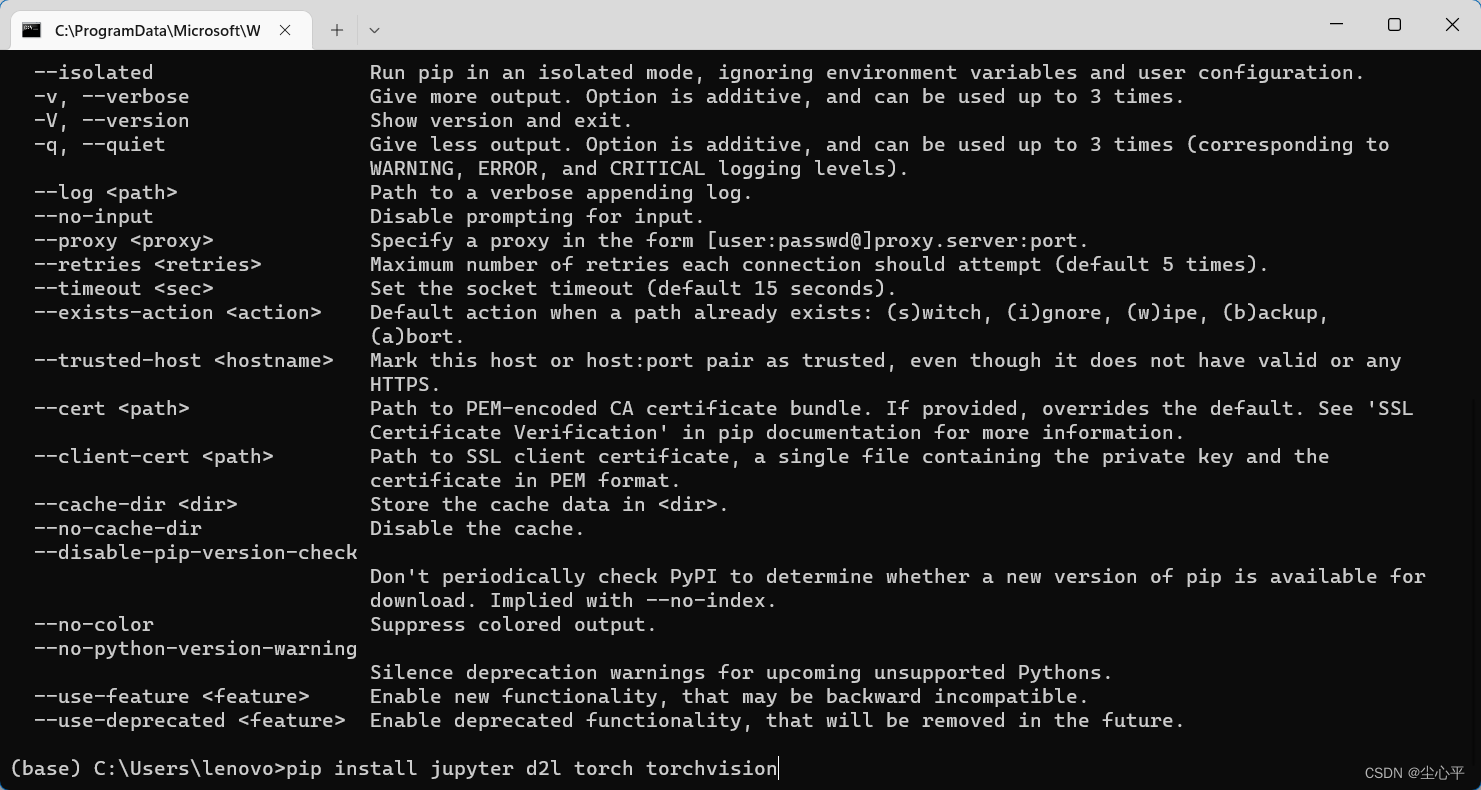
安装jupyter、d2l、torch、torchvision
pip install jupyter d2l torch torchvisiond2l是李沐教授封装好的包,内有一些封装好的函数可以直接调用
最后可以用下列命令,打开jupyter记事本
jupyter notebook
教学资源的下载
在官网序言 — 动手学深度学习 2.0.0-beta1 documentation中下载
解压zip后会有三个文件夹,我们采用的是pytorch版

Windows
安装miniconda
点击链接即可开始下载,下载完成后以管理员身份点击安装程序运行
Next直到设置安装路径
点击Next进入高级选项设置,这里不让我们选择添加环境变量可以用Anaconda Promot代替Windows命令行使用conda
点击Install等待安装完成,之后Finish即可



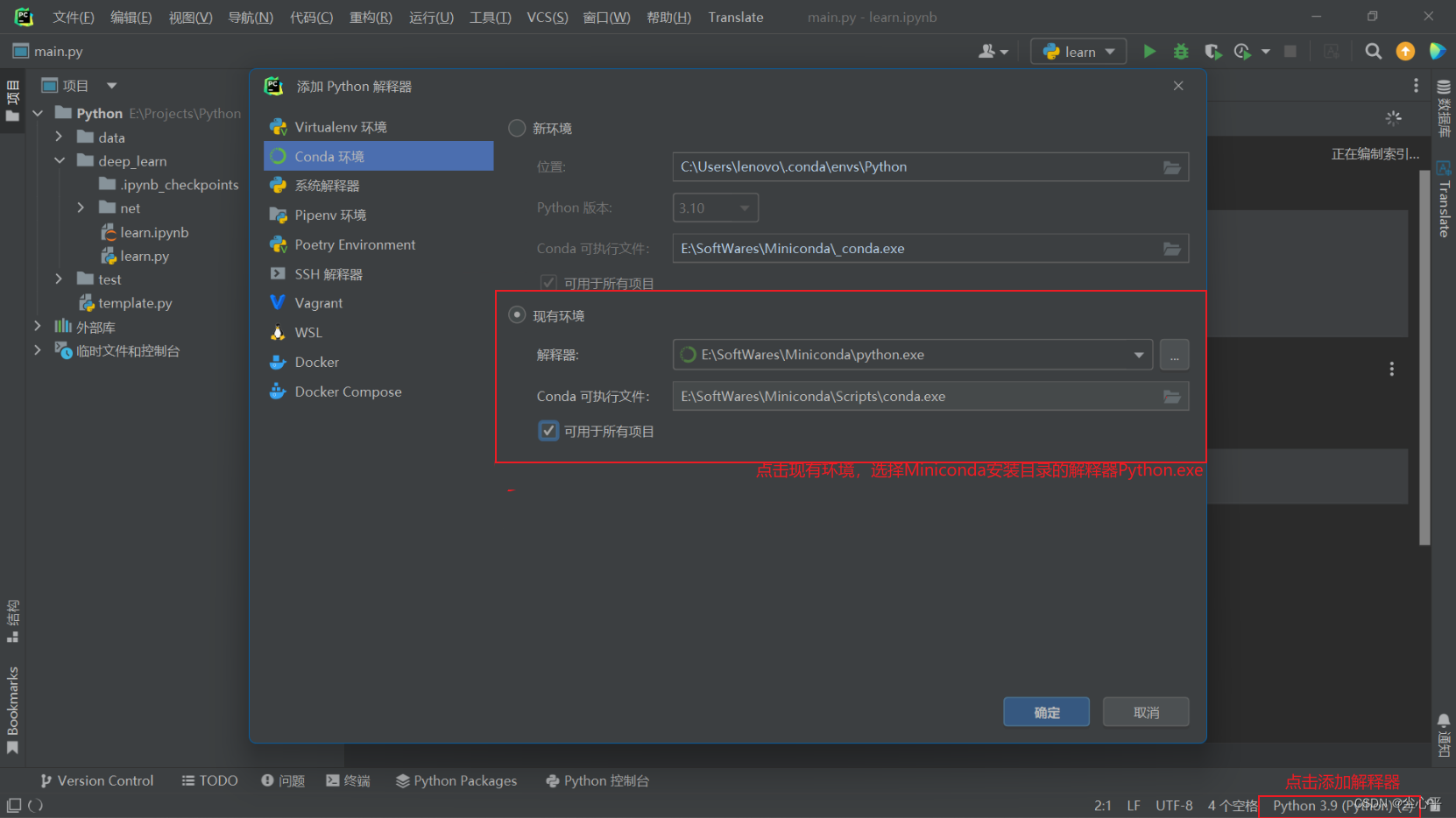
PyCharm添加conda环境及解释器
如图操作即可,填写完成后点击确定再点击右下角的解释器,选择conda解释器
安装jupyter、d2l、torch、torchvision
点击Anaconda Promot程序并运行,输入最后的pip install即开始下载
pip install jupyter d2l torch torchvision