牢骚一下
我的某大电影APP平台 一直薅朋友的会员共享,最近到期了,也不见续费。。。这几年生活不易~ 加上没啥好新电影吧。 这饭点看个小片已成习惯, 没有新电影看个老片也聊胜于无啊。
但是,这点开的广告时长已经可以把饭吃完了,别说中途的广告了。
那就网上搜索一些电影有一些xx影视平台,虽然有免费的,但是有时候卡网也烦恼。于是各种网上找办法想下载下来慢慢看吧。
于是找到了FFmpeg 这个开源的好东西,网上教程也大把。如下载网上视频用下面命令就基本OK了。
ffmpeg -i https://xxx.xxx.xxx/hls/index.m3u8 -c copy -bsf:a aac_adtstoasc output.mp4
只要下载了FFmpeg工具,配置系统路径环境,在命令窗口输入命令,加上m3u8的地址就等结果行了。
但是!毕竟她不是专门的下载工具,碰到网络或者服务器连接不稳定,可能你下了大半天的电影卡在最后一点,那就芭比Q了。 没得继续接收。(或者有高人可顺便指点一下其实有方法的)
于是想到了以前用Python 下过视频,我想这方面的脚本应该也不少吧,于是搜索了不少相关文章,自己也测试,最后找了一个靠谱的,看着也舒适的,参考改了一个适合我自己习惯的。
经过几天的下载视频测试与改进,觉得可以分享给大家,送给爱折腾有需要的人~
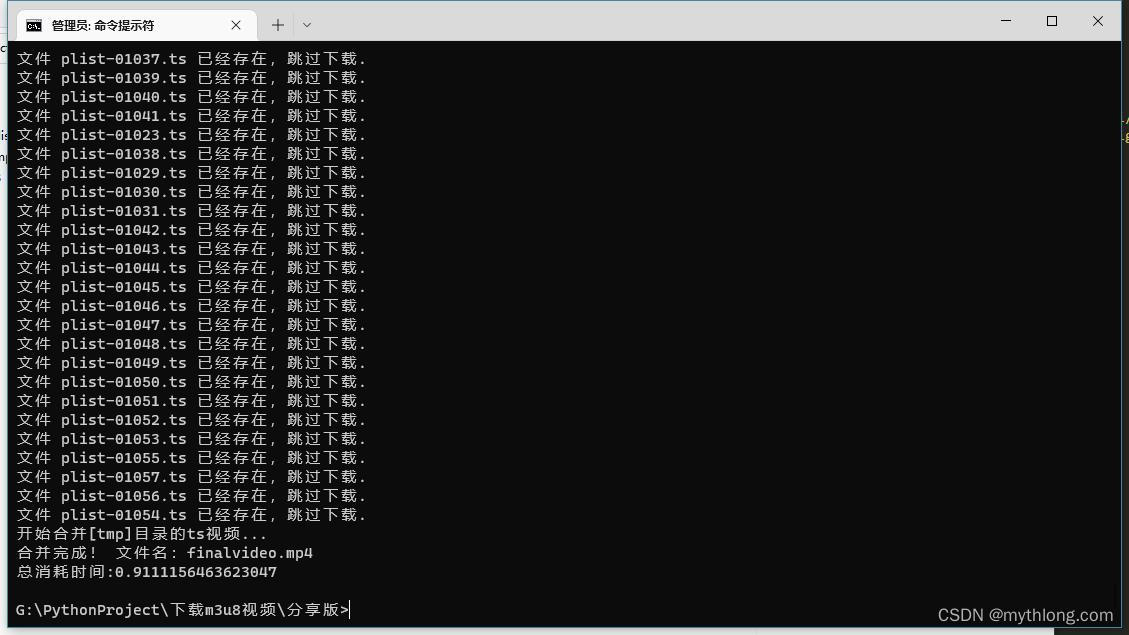
先来张截图, 后面放脚本与方法~



如何找m3u8视频的文件地址?
1。搜索你的电影并打开正在播放的页面
2。打开“开发者工具” ,浏览器一般快捷键是:F12 。 如果没有反应,就找设置菜单的工具里找,什么?你浏览器没有? 那你换个正常点的浏览器吧。 我反正用谷歌、傲游、还有win10 自带的Microsoft Edge都是有的!
3。找到网络(Network)一栏,在搜索过渡栏里输入m3u8 。记得,这里要按 F5把页面重新打开刷新一次,因为刚开始打开时没开工具栏,所以看不到之前下载的信息。如图:

注意上图中的 index.m3u8 , 不一定所有网站都是这名字,只要看后辍是m3u8就可以了,如果是有多个,就点最下面那一个。 在上面点右键 》 复制 》复制链接地址。 然后把复制的地址先存起来,我习惯性开个记事本做中转。

好了! m3u8文件链接就算找到了! 后面就交给脚本去执行吧。
脚本使用步骤
(PS:以下给python专业人士可随便忽略)
如果你对以下内容表示头晕!就直接下载这里打包好的工具EXE文件(win10打包,其它win版本我没试过不确定能否使用:)。
下载工具后,直接放到你要下载电影的目录,双击打开,输入你的m3u8文件地址就可。
1 。脚本是Python的,所以第一要安装Python 呀。 这个安装没啥特殊的,直接点下一步,注意有一个添加系统 Path 要勾上, 这样你后面运行Python就不需要指定路径了。
2 。先选一块好地吧,比如你要下载的电影位置,取个电影名文件夹。然后打开记事本,复制以下脚本 , 然后保存,保存时编码选择 UTF-8 .我取名为: m3u8dl.py (记得把保存类型改成:所有类型*.*)

3. 最后一步 ,在当前目录打开CMD 命令窗口 或者终端 ,不会啊?
win7。。。还有人用吗? 我一直挺喜欢的,但是好多软件不给用了,哎, 不过我双系统还留着win7。按着 shift , 在目录空白位置点鼠标右键,就看到 打开命令窗口的项了。
win10.... 就尴尬了,用上面的方法默认打开的是powershell 吧 ,这玩意一直没搞懂有什么好处,好多dos命令也用不了。 那就直接 win键+R 打开运行窗口,输入cmd 运行好了!如果你安装 了win10版终端也可以都一样。这不是重点我很矛盾是不是我太啰嗦了。
如图,输入m3u8.py 你刚才复制的m3u8链接地址 ,回车运行就好。比如:
m3u8dl.py https://xx.xxx.com/play/QbYMnMbz/index.m3u8如果网络正常没有错误就会出现下载任务提示了。

m3u8dl.py 代码
#这是一个下载m3u8 视频资源的脚本 无指定序号版,根据资源数组排序 非ffmpeg合并版
import os
import re
import sys
import m3u8
import glob
import time
import requests
import concurrent.futures
from Crypto.Cipher import AES
from concurrent.futures import as_completed
#请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.82 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'Zh-CN, zh;q=0.9, en-gb;q=0.8, en;q=0.7'
}
#判断是否为网站地址
def reurl(url):
pattern = re.compile(r'^((https|http|ftp|rtsp|mms)?:\/\/)[^\s]+')
m=pattern.search(url)
if m is None:
return False
else:
return True
#获取密钥(针对有些m3u8文件中的视频需要key去解密下载的视频)
def getKey(keystr,url):
keyinfo= str(keystr)
method_pos= keyinfo.find('METHOD')
comma_pos = keyinfo.find(",")
method = keyinfo[method_pos:comma_pos].split('=')[1]
uri_pos = keyinfo.find("URI")
quotation_mark_pos = keyinfo.rfind('"')
key_url = keyinfo[uri_pos:quotation_mark_pos].split('"')[1]
if reurl(key_url) == False:
key_url = url.rsplit("/", 1)[0] + "/" + key_url
res = requests.get(key_url,headers=headers)
key = res.content
print(method)
print(key.decode('utf-8','ignore'))
return method, key
#下载文件
#down_url:ts文件地址
#url:*.m3u8文件地址
#decrypt:是否加密
#down_path:下载地址
#key:密钥
def download(down_url,url,decrypt,down_path,key,nameid):
if reurl(down_url) == False:
if len(down_url.rsplit("/", 1))>1:
filename = down_url.rsplit("/", 1)[1]
else:
filename = down_url
down_url = url.rsplit("/", 1)[0] + "/" + down_url
else:
filename = down_url.rsplit("/", 1)[1]
down_ts_path = down_path+"/{0}".format(filename)
if os.path.exists(down_ts_path):
print('文件 '+filename+' 已经存在,跳过下载.')
else:
try:
res = requests.get(down_url, stream=True, verify=False,headers=headers)
print('正在下载资源:'+filename+'')
except Exception as e:
print('requests error:',e)
return
if decrypt:
cryptor = AES.new(key, AES.MODE_CBC, key)
with open(down_ts_path,"wb+") as file:
for chunk in res.iter_content(chunk_size=1024):
if chunk:
if decrypt:
file.write(cryptor.decrypt(chunk))
else:
file.write(chunk)
print('文件:['+filename+']已保存到['+down_path+']目录.')
#合并ts文件
#dest_file:合成文件名
#source_path:ts文件目录
#ts_list:文件列表
#delete:合成结束是否删除ts文件
def merge_to_mp4(dest_file, source_path,ts_list, delete=False):
files = glob.glob(source_path + '/*.ts')
if len(files)!=len(ts_list):
print("文件不完整,已取消合并!请重新执行一次脚本,完成未下载的文件。\n如果确认已下载完所有文件,请检查下载目录移除其它无关的ts文件。")
return
print('开始合并['+source_path+']目录的ts视频...')
with open(dest_file, 'wb') as fw:
for file in ts_list:
with open(source_path+"/"+file, 'rb') as fr:
fw.write(fr.read())
if delete:
os.remove(file)
print('合并完成! 文件名:'+dest_file+'')
def main():
url = "https://xxxx/hls/index.m3u8" #下载地址,通过 cmd 传入或输入
print('\n')
print('参数说明:脚本后面面添加 m3u8地址参数,如打开CMD(终端命令)模式输入:m3u8dl http://xxx.xxx.com/xxx.m3u8')
print('\n')
print(' 如果m3u8地址访问不到,提示错误,多重复几次就好。前提是确认在线能观看可下载到m3u8文件。')
print(' 下载中途不动了或者关机,可关闭取消下载,再次打开继续下载。')
print(' 有些文件一次下载不到,需要多次执行下载。')
print(' 等所有文件下载完后自动合成一个视频,注意看提示。')
print('\n')
if len(sys.argv)>1:
url=(sys.argv[1])
else:
print('亲,没有添加m3u8地址,请在下方输入:')
url=input()
#禁止安全谁提示信息
requests.packages.urllib3.disable_warnings()
print('开始分析m3u8文件资源...')
#使用m3u8库获取文件信息
try:
video = m3u8.load(url, timeout=20, headers=headers)
except Exception as e:
print('m3u8文件资源连接失败!请检查m3u8文件地址并重试.错误代码:',e)
return
#设置下载路径
down_path="tmp"
#设置是否加密标志
decrypt = False
#ts列表
ts_list=[]
#判断是否加密
key=''
if video.keys[0] is not None:
method,key =getKey(video.keys[0],url)
decrypt = True
#判断是否需要创建文件夹
if not os.path.exists(down_path):
os.mkdir(down_path)
#把ts文件名添加到列表中
for filename in video.segments:
if len(filename.uri.rsplit("/", 1))>1:
ts_list.append(filename.uri.rsplit("/", 1)[1])
else:
ts_list.append(filename.uri)
#开启线程池
with concurrent.futures.ThreadPoolExecutor() as executor:
obj_list = []
begin = time.time()#记录线程开始时间
for i in range(len(video.segments)):
obj = executor.submit(download,video.segments[i].uri,url,decrypt,down_path,key,i)
obj_list.append(obj)
#查看线程池是否结束
for future in as_completed(obj_list):
data = future.result()
# print('completed result:',data)
merge_to_mp4('finalvideo.mp4', down_path,ts_list)#合并ts文件
times = time.time() - begin #记录线程完成时间
print('总消耗时间:'+str(times)+'')
if __name__ == "__main__":
main()
以上脚本引用了多个库,默认Python是没有的。如果运行看到有提示“... Module ..XXX" 错误,那就安装上对应的库。 安装指令很简单 , 在命令窗口输入: pip install 模块名, 比如提示 缺少 Module m3u8 , 输入以下命令回车:
pip install m3u8其它-批处理
如果担心下载不完,分时间下载,存链接不方便,可以做一个批处理文件。省去每次输入下载链接,直接双击运行就好。
批处理文件方法:
打开记事本,输入以下指令,然后保存,保存类型选择 所有文件*.* ,写个你好记的名字,保存在m3u8dl.py 电影下载的同一目录里。如:下载xxx视频.bat (注意是“.bat” 结尾的文件类型)
m3u8dl.py http://xxxx.xxx/xxx.m3u8
pausePS: 就是脚本名字 +空格+ m3u8文件的链接地址
好了,就写到这吧。有问题再补充?