一、MMAction2——视频理解与行为识别
-
行为识别,时序检测,时空检测三种任务的联系

-
对于视频的理解
视频 = 空间 + 时间:图像为二维空间,视频是三维,视频相对于图像多出来的维度就是时间维度。

-
视频理解的重点
-
重点1:如何描述视频中的动作?
动作 = 外观 + 运动。外观是静态的,是图像帧。运动是动态的,也叫帧间运动,就是时序上的变化。

-
思路1:独立提取图像特征,再进行时序建模
把静态的外观特征与动态的时序上的变化分成两个层次建模。
第一层次:提取每一个图像的外观特征。
第二层次:在外观特征所形成的序列基础之上进行一次时序建模。
提取动态信息,根据动态信息获取动作特征。

-
思路2:外观特征与运动特征并行计算,最后融合
首先根据单帧图像提取外观特征
通过相邻帧的变化,提取瞬时变化的信号,进而提取运动特征
以上两步并行计算,最后融合

-
思路3:利用更加强大的模型,从多帧图像直接计算运动特征

-
-
重点2:如何高效的处理视频数据?
视频的数据量远大于图像,一秒钟的视频就包含20~30张图像,对计算量,内存的占用都会带来巨大挑战
-
重点3:如何利用无标注的视频数据训练模型?
标注视频的工作量比起图像标注要打百倍千倍,传统的对每一张图片进行精细标注,不太现实。
-
1. 光流和2D卷积(解决重点1,2)
- 光流——捕捉视频中的运动。光流是图像平面上的向量场,光流通常基于相邻图像帧进行估计得到。光流就是把图像中每一个点的位移表示出来。光流整体能表达出全图各个点的位移的方向和幅度。

-
光流的估计

这里有些Latex符号在这里会报错,所以直接贴图了。(Typora中打的)

-
光流的可视化

-
光流的两种类型
颜色表示方向,亮度表示大小
- 稀疏光流:跟踪少量感兴趣的点
- 稠密光流:估算所有像素的光流
-
深度学习时代的视频理解
-
DeepVideo(2014)
用图像分类网络AlexNet在每一帧图片上提取特征并融合在一起,但是没有性能上的提升。因为它只关注每一帧图像的外观特征,没有捕捉运动特征。

-
Two Stream Networks(2014)
双流神经网络
- Spatial stream是空间流,以单张图像为输入,主要提取每一帧图像的外观特征
- Temporal stream是时间流,以多帧光流作为输入,用卷积网络作用在光流场(即二维信号)上面取提取运动特征。
- 最终,两个分支提取出外观特征和运动特征,结合在一起。
- 解决重点2
- 在训练时:随机选择视频的某一时刻,计算图像的光流
- 在测试时:在全部时刻进行预测,再平均所有时刻的分类概率
- 双流神经网络存在的问题:双流网络聚焦在短时建模,动作由单一时刻的图像和光流所确定,会存在一些信息上的误解。因此需要长时建模,动作应该由整个时间段内的图像和运动信息所确定

-
Temporal Segment Networks(2016)
时序分段网络TSN
- 当一段视频进来的时候,不会逐帧取采样,会按照一个固定的间隔去采。例如,把整段视频分割为3个段落,每个段落取1个瞬间,再送进双流网络进行外观与运动的特征提取 。3个段落中分别进行前,中,后段的动作预测。最后,融合得到全视频的动作预测。
- TSN关键点:用新的分段采样的方式,而不是按照一定固定的频率去进行密集采样。让视野得到有效的扩大,信息更加综合多元。

-
2. 3D卷积网络(解决重点1,2)
-
(1)与2D卷积网络的区别
- 在双流网络和TSN上,会基于光流去提取运动特征。即通过图像帧去提取运动特征。

-
3D卷积:2D卷积用于图像特征提取。而3D卷积用于视频特征提取,就是多增加了一个时间维度。

-
(2)3D卷积网络——I3D的提出
-
I3D(2017)
关键点:3D网络由图像分类的2D网络“膨胀”得来,因此可以充分利用已有的图像分类模型。
从此,基于膨胀的三维卷积核的三维卷积网络I3D逐渐称为动作识别这个领域的主流方法。
-
关于膨胀2D卷积
3D卷积相比于2D卷积多了一个在时间维度的堆叠

-
对图像分类的2D网络Inception进行膨胀
卷积膨胀:从二维的一个卷积核复制几份叠到一起,形成一个三维卷积核

-
-
相关视频理解方法的对比
(a)DeepVideo模型(2D卷积+LSTM):2D卷积只能处理单帧数据,而对于视频数据来说,则需要将2D卷积处理的多张单帧数据做融合,LSTM就是融合的方法。(即直接作用在图像上,通过二维卷积方法提取每一帧图像的外观特征,然后将特征送入LSTM来捕捉时间特征。)
(b)C3D模型(3D卷积):将2维卷积核变为3维卷积核。(单纯基于空间流,但没有使用膨胀卷积核,参数多,训练难度加大)
(c) 双流神经网络(2D卷积):还是基于图像帧去提取外观特征与运动特征。
(d)I3D模型——基于3D卷积的双流模型(3D卷积):3D卷积模型没有像2D卷积一样有成熟的预训练参数,所以借鉴了成熟的图像分类网络(2D卷积网络)Inception,将网络中的2D卷积核变为3D卷积核。H,W对应的参数直接从Inception获取,D参数自己训练。(I3D的训练方式是先通过Kinetics数据集进行预训练,再训练HMD51和UCF101并验证效果)
总而言之,I3D就是将C3D与双流网络进行融合。


-
-
(3)更高效的3D卷积网络(解决重点2)
-
解决办法1:分解3D卷积核
原因:全部使用3D卷积参数量最大
目的:降低参数量
思路:先过一遍空间卷积,进行空间信息的融合,再过一遍时间卷积,进行时间维度的融合。
t d 2 > d 2 + t td^2>d^2+t td2>d2+t相关网络:S3D(2018) & R2 + 1D(2018)

-
解决办法2:减少通道关联
输入通道是c,输出通道是c的时候,则需要c²个卷积核。可以选择分组卷积&逐层卷积的方法。


-
SlowFast(2019)
-
关键点:外观和运动速度的变化不同,外观变化慢,运动变化快。
-
思路:用低帧率对外观进行采样,用高帧率对运动进行采样。并用相对轻量级的网络结构来平衡计算量。

-
-
3. 弱监督学习方法(解决重点2,3)
- 弱监督学习:使用标注不完整的数据进行学习,但也要有一定的标注去引导。
- 基本思路:
- 大规模无标注或精确标注的数据进来,进行过滤筛选,得到值得标注的数据,进行标注
- 针对部分标注的数据进行监督学习,获得预训练模型

-
IG-65M(2019)
-
背景:Facebook2019年提出。使用Kinetics数据集。Kinetics是一个标准的学术数据集,里面提供大量视频。
-
主要内容:利用Kinetics数据里的关键标签,再从Instagram(大型的图像和视频分享网站)收集6500万个视频,对Kinetics上经过良好标注的视频进行补充。从而形成一个整体的弱监督的数据集,去预训练一个大模型。预训练完成后,再在Kinetics数据集上进行微调训练。
-
实验结果
(1)经过预训练的模型的性能优于直接在目标数据集上训练的模型
(2)预训练使用的数据越多,性能越好,不准确的标注由数据量弥补

-
-
OmniSource(2020)
-
背景:2020年,港中文提出的,使用多种来源的数据(长视频,短视频,图像)联合训练模型,对数据的利用更高效
-
主要内容
(1)数据爬取:获取原始网络的不同形态的图像视频
(2)数据过滤:使用与训练好的模型进行数据筛选,形成筛选后的数据集
(3)标准化处理:格式化视频与图像,形成标准化数据集
(4)混合数据训练模型
-
实验结果:分类精度进一步提升
-
总结(基于重点1,2,3)
(1)视频理解的3个基本任务:行为识别,时序动作检测,时空动作检测
(2)重点1:如何获得更好的动作特征?
- 深度学习时代以前:DT
- 深度学习时代早期:双流网络,TSN提出分段采样的方式
- 如今:基于3D卷积网络,尤其是I3D,通过对卷积核进行膨胀,获得有效的训练3D卷积网络的方法
(3)重点2:如何高效地处理视频数据,提高3D卷积模型地计算效率?
- 时空分解:S3D,R(2+1)D
- 优化参数分配:SlowFast
(4)重点3:如何控制标注成本?
- 弱监督学习:IG-65M,OmniSource
二、视频理解工具包——MMAction2
1. 行为识别模型的结构
-
action recognition实际上是个分类问题。主要由两类模型,一个是基于2D卷积神经网络的,另一种是基于3D卷积神经网络的。
-
2D,3D两类模型在构成上没有太大区别,区别在于处理输入方面。
- 2D:接受一些独立的图像帧,送进主干网络进行分类
- 3D:接受连续的图像帧,送进主干网络进行分类

2. TSN模型配置
- TSN是一个2D模型,主干网络使用ResNet-50层的结构
- TSN需要输入一个视频在不同时刻若干个图像帧(clip),处理不同的clip的神经网络是共享参数的,所以只初始话1个backbone。即用一个backbone处理所有的clip的图像,再把结果平均放到TSNHead里去产生最终的分类结果。
model = dict(
type = 'Recognizer2D',
# 2D ResNet-50作为主干网络
backbone = dict(
type = 'ResNet',
pretrained = 'torchvision://resnet50', # 从torchvision中拿取ResNet-50的预训练参数
depth = 50,
norm_eval = False),
# TSN的分类头
cls_head = dict(
type = 'TSNHead', # TSN的头会接收ResNet产生的特征
num_classes = 400,
in_channels = 2048,
spatial_type = 'avg',
consensus = dict(type = 'AvgConsensus', dim = 1), # 通过平均共识函数,把多个特征平均到一起,再产生400类的分类(Kinetics400)
dropout_ratio = 0.4,
init_std = 0.01),
)
3. I3D模型配置
-
I3D是一个3D模型,主干网络使用ResNet-50层的结构
-
原始论文中I3D是基于Inception,这里基于ResNet-50
-
关于I3D的分类头:3D卷积网络要接受的是一个5维的输入,这里通常会使用average pooling把THW3个维度压缩成1个维度。然后只剩下batch维和通道维,通道维的维度是2048,经过average pooling后,针对每个数据可以得到2048个特征,然后再用一个全连接层产生一个400维的分类概率。模型最终输出400维的分类概率。
- 5个维度:batch维,通道维,THW维(时间,宽度,高度)
model = dict(
type = 'Recognizer3D',
# 膨胀的3D ResNet-50作为主干网络
backbone = dict(
type = 'ResNet3d',
pretrained2d = True, # 使用 2D ResNet-50的预训练参数
pretrained = 'torchvision://resnet50', # 从torchvision中拿取ResNet-50的预训练参数
depth = 50,
conv_cfg = dict(type = 'Conv3d'),
norm_eval = False,
'''
infalte = 1,表示在对应的层使用膨胀策略,将2D卷积变为3D卷积,指定为0就不使用膨胀
ResNet-50有4组残差模块每组残差模块中分别有3,4,6,3个残差模块,1和0就表示指定的残差模块是否膨胀。
'''
inflate = ((1, 1, 1), (1, 0, 1, 0), (1, 0, 1, 0, 1, 0), (0, 1, 0)),
zero_init_residual = False), # 分类时设置为True
# I3D的分类头
cls_head = dict(
type = 'I3DHead',
num_classes = 400,
in_channels = 2048, # 通道维
spatial_type = 'avg',
dropout_ratio = 0.5,
init_std = 0.01),
)
4. 数据集配置
-
数据集类型:
-
RawframeDataset(读图像帧)——将MP4或者其他编码格式的视频先在线下解码成一帧一帧的图像,然后将所有的图像帧存到对应的目录里,这个目录就代表一个视频。目的是为了减少在训练时的解码时间。所以预先把所有视频解码好,放到一个文件夹里训练的时候按照帧的序号去读对应的图像文件。如下图所示。

依次为:图像帧目录,图像帧数量,动作分类的序号。其中,每一个目录代表一个视频。
-
VideoDataset(读视频)
-
data = dict(
# batchsize(每个视频加载的进程数)
videos_per_gpu = 8,
# 视频读取进程数
workers_per_gpu = 4,
# 指定数据子集
train/val/test = dict(
# 数据集类型
type = 'RawframeDataset'/'VideoDataset'/...,
# 类别标注文件(RawframeDataset读图像帧的文件夹)
ann_file = 'annotation.txt',
# 数据集根目录
data_prefix = 'data/kinetics400/rawframes_train',
# 数据是图像还是光流
modality = 'RGB'/'Flow',
# 指定数据处理的工作流,通常做数据读取或者数据增强之类的任务
pipeline = train_pipeline
)
)
- 数据处理的pipeline
- SampleFrames:从视频抽取一些帧,用clip_len定义帧长度,frame_interval为抽取的步长,num_clips为抽取几个片段
- RawFrameDecode:把对应的图像帧读取进来,并且进行解码
- Resize:裁剪
- Flip:翻转
- Normalize:像素值归一化
- FormatShape:对维度进行排序。例如NCTHW就是batch维,通道维,时间维,空间维
- ToTensor:从处理好的数据中把对应的图像,类别标签转化成对应格式的tensor,最终传给分类模型进行前传计算。
- 总体步骤:读取连续帧图像→解码对应帧图像→数据增强→将数据转化为torch.Tensor→分类模型
train_pipeline = [
dict(type = 'SampleFrames', clip_len = 32, frame_interval = 2, num_clips = 1), # 32帧,每隔两帧抽取一帧,覆盖64帧,抽取1个片段
dict(type = 'RawFrameDecode'), # 解码,成为32个h×W数组
dict(type = 'Resize', scale = (-1, 256)), # 裁剪
dict(type = 'RandomResizedCrop'),
dict(type = 'Resize', scale = (224, 224), keep_ratio = False),
dict(type = 'Flip', flip_ratio = 0.5), # 翻转
dict(type = 'Normalize', **img_norm_cfg), # 像素归一化
dict(type = 'FormatShape', input_format = 'NCTHW'), # 维度排序
dict(type = 'Collect', keys = ['imgs', 'label'], meta_keys = []),
dict(type = 'ToTensor', keys = ['imgs', 'label']) # 转化为totensor格式
]
5. 常用的训练策略(MMAction2中)
- sgd_50e.py配置文件
- SGD优化器
- lr_config:步长下降策略,在20轮和40轮的时候将学习率降为原来的1/10,训练50轮结束
- optimizer_config:梯度策略,每一次算出梯度之后,把所有的梯度通过norm2(求平方和再开平方)算出梯度整体的norm。当梯度的总体norm超过max_norm使进行归一化,把norm进行整体缩小。以增加训练稳定性,防止梯度过大。
# optimizer
optimizer = dict(
type = 'SGD',
lr = 0.01, # 8 gpus
momentum = 0.9,
weight_dacay = 0.0001)
optimizer_config = dict(grad_clip = dict(max_norm = 40, norm_type = 2))
# learning policy
lr_config = dict(policy = 'step', step = [20, 40])
total_epochs = 50
三、代码实操
主要任务:
- 用MMAction2的识别模型做一次推理
- 用新数据集训练一个新的识别模型
- 用MMAction2的时空检测模型做一次推理
1. 安装依赖库
这里是我安装的版本,要注意相关版本的对应。具体的安装文档见最后的地址链接。
- cuda 11.1
- GCC 6.3.0
- torch 1.8.0
- torchvision 0.9.0
- MMAction2 0.24.0
# 检查 nvcc,gcc 版本
!nvcc -V
!gcc --version
# 检查torch的版本>1.5,GPU是否可用
import torch, torchvision
print(torch.__version__, torch.cuda.is_available(), torchvision.__version__)
# 检查mmcv版本
from mmcv.ops import get_compiling_cuda_version, get_compiler_version
print(get_compiler_version())
print(get_compiling_cuda_version())
# 检查MMAction2的版本
import mmaction
print(mmaction.__version__)
2. MMAction2识别模型推理(用提供的预训练模型)
- 预训练模型TSN下载地址:TSN下载
- 配置文件命名:
- r50:主干网络ResNet50
- kinetics400:数据集
- rgb:只基于RGB去训练,没有使用光流
- 1×1×3:用了3个clip,把视频分割为前中后3段,每一段去采集对应的图像帧
- 100e:总共训练了100个epoch
- 下载完预训练模型放到checkpoints文件夹中
# 创建checkpoints文件夹,并下载TSN模型
!mkdir checkpoints
from mmaction.apis import inference_recognizer, init_recognizer
# 选择tsn对应的配置文件
config = 'configs/recognition/tsn/tsn_r50_video_inference_1x1x3_100e_kinetics400_rgb.py'
# 加载上面下载的checkpoint文件
checkpoint = 'checkpoints/tsn_r50_1x1x3_100e_kinetics400_rgb_20200614-e508be42.pth'
# 在GPU上初始化该模型
model = init_recognizer(config, checkpoint, device='cuda:0')
# 选择视频进行推理
video = 'demo/demo.mp4'
label = 'tools/data/kinetics/label_map_k400.txt' # 400行的文件,每行就是数据集的一个类别
results = inference_recognizer(model, video)
labels = open(label).readlines()
labels = [x.strip() for x in labels]
results = [(labels[k[0]], k[1]) for k in results]
# 查看视频,传入已定义的video
from IPython.display import HTML
from base64 import b64encode
mp4 = open(video,'rb').read() # rb以二进制格式打开一个文件用于只读。
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
HTML("""
<video width=400 controls>
<source src="%s" type="video/mp4">
</video>
""" % data_url)
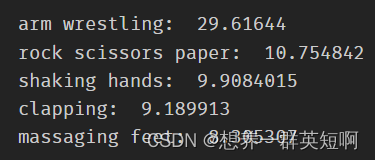
demo视频为arm wrestling,地址:demo.mp4
# 查看推理Top-5结果
for result in results:
print(f'{
result[0]}: ', result[1])
最终用这个预训练的TSN模型得到以下分类结果
3. 在自定义数据集上训练模型(kinetics400_tiny)
训练新模型的三个步骤:
- 整理数据:通常要把数据整理成固定的格式,并且对应生成一些标注文件
- 修改配置文件:把里面原有的数据替换成我们自定义的数据
- 训练模型
3.1 整理数据
- 将数据转换为已有数据集格式的示例。
- 用到的是一个从Kinetics-400中获取的tiny数据集。包含30个训练视频,10个测试视频。
- 有两个标注文件分别对应训练集和验证集(二分类)
下载并且解压数据集kinetics400_tiny,下载地址:kinetics400_tiny
# 查看标注文件格式(linux命令-cat,正斜杠/)
!type kinetics400_tiny\kinetics_tiny_train_video.txt
3.2 修改配置文件
- 我们需要修改配置文件,同时会用到之前下载的checkpoint作为pre-trained模型。
- 在之前用于kinetics400-full数据集训练的tsn模型配置上进行修改,让模型可以在Kinetics400-tiny数据集上进行训练。在小数据集上进行训练。
- 30个epoch的训练进程pth文件,会保存到生成的tutorial_exps文件夹中。
# 获得tsn对应的配置文件cfg(分了8个clip)
from mmcv import Config
cfg = Config.fromfile('./configs/recognition/tsn/tsn_r50_video_1x1x8_100e_kinetics400_rgb.py')
from mmcv.runner import set_random_seed
# 修改数据集类型和各个文件路径
cfg.dataset_type = 'VideoDataset'
cfg.data_root = 'kinetics400_tiny/train/'
cfg.data_root_val = 'kinetics400_tiny/val/'
cfg.ann_file_train = 'kinetics400_tiny/kinetics_tiny_train_video.txt'
cfg.ann_file_val = 'kinetics400_tiny/kinetics_tiny_val_video.txt'
cfg.ann_file_test = 'kinetics400_tiny/kinetics_tiny_val_video.txt'
cfg.data.test.type = 'VideoDataset'
cfg.data.test.ann_file = 'kinetics400_tiny/kinetics_tiny_val_video.txt'
cfg.data.test.data_prefix = 'kinetics400_tiny/val/'
cfg.data.train.type = 'VideoDataset'
cfg.data.train.ann_file = 'kinetics400_tiny/kinetics_tiny_train_video.txt'
cfg.data.train.data_prefix = 'kinetics400_tiny/train/'
cfg.data.val.type = 'VideoDataset'
cfg.data.val.ann_file = 'kinetics400_tiny/kinetics_tiny_val_video.txt'
cfg.data.val.data_prefix = 'kinetics400_tiny/val/'
# 这里用于确认是否使用到omnisource训练
cfg.setdefault('omnisource', False)
# 修改cls_head中类别数为2
cfg.model.cls_head.num_classes = 2
# 使用预训练好的tsn模型
cfg.load_from = './checkpoints/tsn_r50_1x1x3_100e_kinetics400_rgb_20200614-e508be42.pth'
# 设置工作目录
cfg.work_dir = './tutorial_exps'
# 由于是单卡训练,修改对应的lr
cfg.data.videos_per_gpu = cfg.data.videos_per_gpu // 16 # 为了加速运行,把batchsize改为原来的1/16
cfg.optimizer.lr = cfg.optimizer.lr / 8 / 16 # 原始配置文件中使用8卡训练,根据线性扩展策略,把lr降到原来的1/128
cfg.total_epochs = 30
# 设置存档点间隔减少存储空间的消耗
cfg.checkpoint_config.interval = 10
# 设置日志打印间隔减少打印时间
cfg.log_config.interval = 5
# 固定随机种子使得结果可复现
cfg.seed = 0
set_random_seed(0, deterministic=False)
cfg.gpu_ids = range(1)
# 打印所有的配置参数
print(f'Config:\n{
cfg.pretty_text}')
3.3 在(自定义的)kinetics400_tiny数据集上训练模型
import os.path as osp
from mmaction.datasets import build_dataset # 调用build_dataset构建数据集
from mmaction.models import build_model # 调用build_model构建模型
from mmaction.apis import train_model # 调用train_model训练模型,传入配置文件,数据,模型
import mmcv
# 构建数据集
datasets = [build_dataset(cfg.data.train)]
# 构建动作识别模型(基于预训练模型,把分类数改为2)
model = build_model(cfg.model, train_cfg=cfg.get('train_cfg'), test_cfg=cfg.get('test_cfg'))
# 创建工作目录并训练模型
mmcv.mkdir_or_exist(osp.abspath(cfg.work_dir))
train_model(model, datasets, cfg, distributed=False, validate=True)
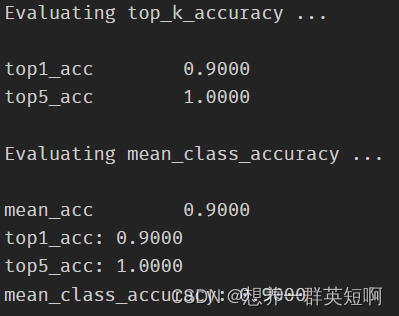
30个epoch后,最终精度如下图。

4. 评价模型
- 只有两类,所以top5_acc: 1.0000。在测试集上分错了1个,最终分类精度为0.9
from mmaction.apis import single_gpu_test
from mmaction.datasets import build_dataloader
from mmcv.parallel import MMDataParallel
# 构建测试数据集
dataset = build_dataset(cfg.data.test, dict(test_mode=True))
data_loader = build_dataloader(
dataset,
videos_per_gpu=1, # batchsize设置为1
workers_per_gpu=cfg.data.workers_per_gpu,
dist=False,
shuffle=False)
model = MMDataParallel(model, device_ids=[0]) # 初始化模型
outputs = single_gpu_test(model, data_loader) # 得到所有模型的分类输出
# 在测试集上评价训练完成的识别模型
eval_config = cfg.evaluation
eval_config.pop('interval')
eval_res = dataset.evaluate(outputs, **eval_config) # 比较输出值与真实值,计算准确率
for name, val in eval_res.items():
print(f'{
name}: {
val:.04f}')
结果如下图
5. 时空动作识别
- 涉及到人的检测,所以还依赖MMDetection框架。时空动作模型需要先用MMDetection产生一些空间还有时间上的proposal,再用action模型进行分类。
- 在时空检测过程中,会自动下载一些软件依赖,模型。这里用下载的Fast-RCNN模型做一个人的检测(每帧都检测)。下载行为识别模型slowfast(仅有slow),用OmniSource的方法预训练,从而进行时空检测。
- 检测完之后,下载ffmpeg把对应的图像编码成一个视频,做成可视化的demo
5.1 安装MMDetection
# 克隆mmdetection项目
%cd ..
!git clone https://github.com/open-mmlab/mmdetection.git
%cd mmdetection
# 以可编辑的模式安装mmdet
!pip install -e .
%cd ../mmaction2
5.2 时空检测
# 上传视频至目录mmaction2下
!wget https://download.openmmlab.com/mmaction/dataset/sample/1j20qq1JyX4.mp4 -O demo/1j20qq1JyX4.mp4
# 完成时空检测
!python demo/demo_spatiotemporal_det.py --video demo/1j20qq1JyX4.mp4
(1)在时空检测的过程中,首先用下载的Fast-RCNN模型做一个人的检测(每帧都检测)
Fast-RCNN配置文件地址:Fast-RCNN
(2)然后下载行为识别模型slowfast(仅有slow),用OmniSource的方法预训练,完成时空检测。
SlowOnly(SlowFast)配置文件地址:SlowOnly
(3)最后检测完之后,下载ffmpeg把对应的图像编码成一个视频,做成可视化的demo。
5.3 查看经过时空动作识别的视频
# 查看视频
from IPython.display import HTML
from base64 import b64encode
mp4 = open('demo/stdet_demo.mp4','rb').read()
data_url = "data:video/mp4;base64," + b64encode(mp4).decode()
HTML("""
<video width=400 controls>
<source src="%s" type="video/mp4">
</video>
""" % data_url)
时空动作识别原视频地址:时空动作识别原视频
时空动作识别后:
时空动作识别——stdet_demo
四、相关参考地址
1.相关课程 视频理解
2. MMAction安装步骤官方文档 MMAction2安装
3. 预训练模型TSN下载地址:TSN下载
4.kinetics400_tiny 下载地址:kinetics400_tiny数据集下载
5. MMAction2的demo.mp4地址 demo.mp4
6. Fast-RCNN配置文件地址:Fast-RCNN
7. SlowOnly(SlowFast)配置文件地址:SlowOnly
8. MMAction2的demo地址:demo