所有示例基于python3.7.4版本
提示:以下是本篇文章正文内容,下面案例可供参考
1.下划线的含义
| 类型 | 含义 |
|---|---|
| _var | 一个约定,表明这个名称供内部使用,约定只有类对象和子类对象自己能访问 |
| var_ | 一个约定,用来避免与Python关键字产生命名冲突 |
| __var | 私有成员,意思是只有类对象自己能访问,连子类对象也不能访问到这个数据。 |
| _var_ | python语言定义的特殊方法,避免你自己的属性中使用这种命名方案 |
| _ | 可用作临时或无意义变量的名称 |
2.面向对象
python是面向对象语言,无疑会包括面向对象的三大特点封装、继承、多态
类、实例、属性、方法
(一)所有类的父类------->object类
class Student(object):
pass
(二)类的实例:
ojb1=Student()
print(ojb1) #类的实例
print(Student)
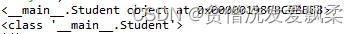
(三)类绑定属性
ojb1.name='刘恒' #给实例变量绑定属性
print(ojb1.name)
(四)类的有参构造
class Student(object):
#self表示实例本身,给对象绑定属性 __init__方法第一个参数永远是self
def __init__(self, name, score):
self.name = name
self.score = score
def print_score(self):
print('%s: %s' % (self.name, self.score))
有参构造会覆盖无参构造,不能传入空的参数,必须传入与__init__方法匹配的参数,但self不需要传,Python解释器自己会把实例变量传进去
测试:
obj1=Student('刘恒',10)
print(obj1.name)
print(obj1.score)
print(obj1.print_score())
#print函数中所放的函数没有返回值,那么print将会return None
obj2=Student('刘恒',10)
print(obj2==obj1)
obj2.name='张三'
print(obj2.name) #外部仍可以访问

通过测试可以发现,两个实例对象即使参数相同,但也是不一样的,所存储的地址是不同的,同时发现实例对象依然可以外部更改属性
封装:隐藏内部,对外提供公共接口
只需要在属性名前加上两个下划线,内部才可访问,外部不能访问
class Student(object):
def __init__(self, name, score):
self.__name = name
self.__score = score
def get_name(self):
return self.__name
def get_score(self):
return self.__score
def set_score(self, score):
self.__score = score
测试:
obj3=Student("张三",13)
#print(obj3.__name) #权限不足访问不到
print(obj3.get_name())
print(obj3.get_score())
obj3.set_score(20)
print(obj3.get_score())

其实实例变量也可以从外部访问,不能直接访问__name是因为Python解释器对外把__name变量改成了_Student__name,所以,仍然可以通过_Student__name来访问__name变量
print(obj3._Student__name)
#错误写法
obj4=Student("王麻子",35)
print(obj4.get_name())
obj4.__name='李四'
print(obj4.__name)
print(obj4.get_name()) #结果仍是王麻子

外部代码“成功”地设置了__name变量,但实际上这个__name变量和class内部的__name变量不是一个变量!内部的__name变量已经被Python解释器自动改成了_Student__name,而外部代码给bart新增了一个__name变量
继承
只需要更改类中括号的内容
Animal-----父类-->object
Dog--父类--Animal--父类->object
class Animal(object):
def run(self):
print('动物园开业了')
class Dog(Animal):
pass
Dog().run() #子类调用父类方法

- 方法重写
class Animal(object):
def run(self):
print('动物园开业了')
class Dog(Animal):
def run(self):
print('我是dog')
Dog().run() #方法重写,子类的方法覆盖了父类的方法

多态
python中支持多态,但是是有限的的支持多态性,
主要是因为python中变量的使用不用声明,所以不存在父类引用指向子类对象的多态
Python中多态的特点:
只关心对象的实例方法是否同名,不关心对象所属的类型;
对象所属的类之间,继承关系可有可无;
class Animal(object):
def run(self):
print('动物园开业了')
class Dog(Animal):
def run(self):
print('Dog is running...')
class Cat(Animal):
def run(self):
print('Cat is running...')
def run_twice(animal):
animal.run()
run_twice(Animal())
run_twice(Dog())
run_twice(Cat())
class Timer(object):
def run(self):
print('Start...')
run_twice(Timer())

``
实例属性和类属性
class Student1(object):
name='王麻子'
ojb6=Student1()
print(ojb6.name) ## 打印name属性,因为实例并没有name属性,所以会继续查找class的name属性
print(Student1.name) ## 打印类的name属性
ojb6.name='张三'
print(ojb6.name) ## 由于实例属性优先级比类属性高,因此,它会屏蔽掉类的name属性
del ojb6.name
print(ojb6.name)

3.面向对象编程
使用__slots__
__slots__变量,用来限制该class实例能添加的属性
class Student(object):
__slots__ = ('name', 'age') # 用tuple定义允许绑定的属性名称
stu3=Student()
stu3.name='liuheng'
stu3.city='xian'
当给实例变量添加city属性时报错: AttributeError: 'Student' object has no attribute 'city'
我们试着给其子类增加未绑定的属性:
class SmartStudent(Student):
pass
stu4=SmartStudent()
stu4.name='zhangsan'
stu4.city='西安'
print(stu4.name)
print(stu4.city)
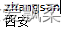
通过结果我们可以发现:__slots__定义的属性仅对当前类实例起作用,对继承的子类是不起作用的
使用__str__
定制返回对象的描述信息
一般对象的信息:<__main__.Student object at 0x000002E429741AC8> 不好看
class Student1():
def __str__(self):
return 'Student object'
print(Student1())
输出为:Student object
使用__repr__
在__str__使用的前提下,当我们将对象的实例赋值给变量时,输出变量,
结果依然是:<__main__.Student object at 0x000002E25B19F9C8>
这是因为:变量调用的不是__str__(),而是__repr__()。 __str__()返回用户看到的字符串,而__repr__()返回程序开发者看到的字符串
通常用: _repr_ = _str_
使用@property
Python内置的@property装饰器就是负责把一个方法变成属性调用的
class Student2(object):
@property
def score(self):
return self._score
@score.setter
def score(self, value):
if not isinstance(value, int):
raise ValueError('score must be an integer!')
if value < 0 or value > 100:
raise ValueError('score must between 0 ~ 100!')
self._score = value
s1=Student2()
s1.score=10
print(s1.score)
输出:10
注意:属性的方法名不要和实例变量重名
class Student3(object):
# 方法名称和实例变量均为birth:
@property
def birth(self):
return self.birth
s2=Student3()
print(s2.birth) #陷入循环
这是因为调用s.birth时,首先转换为方法调用,在执行return self.birth时,又视为访问self的属性,于是又转换为方法调用,造成无限递归,最终导致栈溢出报错RecursionError。
给实例绑定方法与类绑定方法的区别
给实例绑定方法:
class Student(object):
pass
stu1=Student()
def set_age(self, age): # 定义一个函数作为实例方法
self.age = age
from types import MethodType
stu1.set_age=MethodType(set_age,stu1)
stu1.set_age(20)
print(stu1.age)
stu2=Student()
stu2.set_age(20) #报错
AttributeError: 'Student' object has no attribute 给一个实例绑定的方法,对另一个实例是不起作用的
给类绑定方法:
Student.set_age=set_age
stu2.set_age(10)
print(stu2.age) #10
class绑定方法 所有的实例均可调用
多继承:子类可以同时获得多个父类的所有功能
python支持多继承
java只支持单继承,但接口支持多继承
MixIn混入的意思:为了更好地看出继承关系,把Flyable改为FlyableMixIn。
class Animal(object):
pass
# 大类:
class Mammal(Animal):
pass
class Bird(Animal):
pass
#行为类
class Runnable(object):
def run(self):
print('Running...')
class FlyableMixIn(object):
def fly(self):
print('Flying...')
#动物
class Dog(Mammal,Runnable):
pass
class Ostrich(Bird,FlyableMixIn): #为了更好地看出继承关系,后面加MixIn
pass
dog1=Dog()
dog1.run()
Ostrich1= Ostrich()
Ostrich1.fly()
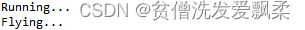
自定义枚举类
from enum import Enum, unique
#@unique装饰器可以帮助我们检查保证没有重复值。
@unique
class Weekday(Enum):
Sun = 0 # Sun的value被设定为0
Mon = 1
Tue = 2
Wed = 3
Thu = 4
Fri = 5
Sat = 6
print(Weekday.Sun,':',Weekday.Sun.value)
Weekday.Sun : 0
4. 错误处理机制
try…except…finally
try:
print('try...')
r = 10 / 0
print('后续代码不会执行')
print('result:', r)
except ZeroDivisionError as e:
print('except:', e)
finally:
print('finally...')
print('END')

没有错误发生,except语句块不会被执行,但是finally如果有,则一定会被执行
错误捕捉不到的问题
except ValueError as e:
print('ValueError')
except UnicodeError as e:
print('UnicodeError')
第二个except永远也捕获不到UnicodeError,因为UnicodeError是ValueError的子类,如果有,也被第一个except给捕获了。
记录错误信息
import logging
def foo(s):
return 10 / int(s)
def bar(s):
return foo(s) * 2
def main():
try:
bar('0')
except Exception as e:
logging.exception(e)
main()

出错,但程序打印完错误信息后会继续执行,并正常退出:
raise抛出错误
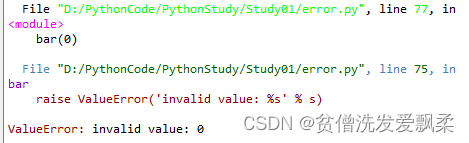
def bar(s):
n = int(s)
if n==0:
raise ValueError('invalid value: %s' % s)
return 10 / n
bar()
自定义错误
常见的错误类型和继承关系:https://docs.python.org/3/library/exceptions.html#exception-hierarchy
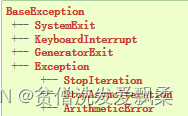
Python所有的错误都是从BaseException类派生的
自定义错误类我们只需要继承Exception类
class FooError(Exception):
pass
def foo(s):
n = int(s)
if n==0:
raise FooError('invalid value: %s' % s)
return 10 / n
foo('0')
5.IO编程
文件的读写
获取file对象主要用open()方法去打开文件,返回一个file对象
open(file, mode='r', buffering=-1, encoding=None, errors=None, newline=None, closefd=True, opener=None)
| mode符号 | 意义 |
|---|---|
| r | 以只读方式打开文件 |
| w | 打开一个文件只用于写入,会把原有的内容覆盖 |
| x | 写模式,新建一个文件,如果该文件已存在则会报错。 |
| a | 打开一个文件用于追加 |
| b | 二进制模式 |
| t | 文本模式 (默认) |
| + | 打开文件进行更新(可读可写) |
测试:
try:
file1= open('C:/Users/文帝/Desktop/test01.txt', 'r',encoding='utf-8') #没有文件则会显示FileNotFoundError
print(file1.read())
finally:
file1.close()

由于文件读写时都有可能产生IOError,所以要对错误进行抓取
文件使用完毕后必须关闭,因为文件对象会占用操作系统的资源,并且操作系统同一时间能打开的文件数量也是有限的
Python引入了with语句来自动帮我们调用close()方法:
with open('C:/Users/文帝/Desktop/test02.txt', 'r',encoding='utf-8') as f:
print(f.read()) #读取文件的全部内容
常用方法:
with open('C:/Users/文帝/Desktop/test02.txt', 'r',encoding='utf-8') as f:
print(f.readline()) #读取一行
with open('C:/Users/文帝/Desktop/test02.txt', 'r',encoding='utf-8') as f:
print(f.readlines()) #一次性把内容按照行返回list类型
file1= open('C:/Users/文帝/Desktop/test02.txt', 'r',encoding='utf-8')
for line in file1.readlines():
print(line.strip()) # 把末尾的'\n'删掉
file1.close()
with open('C:/Users/文帝/Desktop/电科1801-刘恒-西安邮电大学.jpg', 'rb') as f:
print(f.readline()) #读二进制文件
StringIO 在内存中读写 str
from io import StringIO
file3=StringIO()
file3.write('hello')
file3.write(' ')
file3.write('world')
print(file3.getvalue()) #读取写入的str
print('----------通过循环读取-------------')
file4=StringIO('Hello!\nHi!\nGoodbye!')
while True:
s = file4.readline()
if s == '':
break
print(s.strip())

BytesIO内存中读写bytes
from io import BytesIO
f = BytesIO()
f.write('刘恒'.encode('utf-8'))
print(f.getvalue())
print('----------按文件读取-------------')
file5=BytesIO(b'\xe4\xb8\xad\xe6\x96\x87')
s = file5.read()
print(s)

操作文件和目录
import os
print(os.name) #操作系统类型
#如果是posix,说明系统是Linux、Unix或Mac OS X,如果是nt,就是Windows系统。
# print(os.uname()) #获取详细的系统信息
os.uname()是linux的方法 ,windows不可用
print(os.environ) #查看操作系统中定义的环境变量
print('-----------------------------------------------------')
print(os.environ.get('PATH')) #查取某个环境变量的值
print(os.environ.get('x', 'default')) #给x环境变量设值
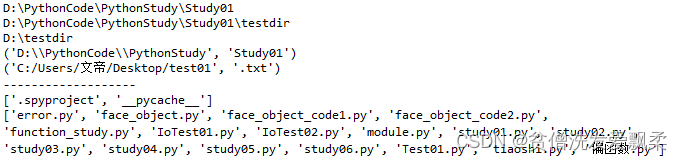
print(os.path.abspath('.')) ## 查看当前目录的绝对路径
s=os.path.join('D:\PythonCode\PythonStudy\Study01', 'testdir') #路径合并
print(s) #在Linux/Unix/Mac下是 part-1/part-2
#os.mkdir('/testdir') #创建一个目录
print(os.path.abspath('/testdir'))
#os.rmdir('/testdir') #删除一个目录
#路径拆分为两部分,后一部分总是最后级别的目录或文件名
r=os.path.split('D:\PythonCode\PythonStudy\Study01')
#这些合并、拆分路径的函数并不要求目录和文件要真实存在,它们只对字符串进行操作。
print(r)
print(os.path.splitext('C:/Users/文帝/Desktop/test01.txt')) #获取文件的扩展名
#os.rename('C:/Users/文帝/Desktop/test01.txt', 'C:/Users/文帝/Desktop/test02.txt') #文件重命名
#注意:文件必须是同一个路径
#OSError: [WinError 17] 系统无法将文件移到不同的磁盘驱动器。:
#'C:/Users/文帝/Desktop/test01.txt' -> 'test02.txt'
#os.remove('test.txt') #删除文件
print('-------------------')
#列出当前目录下的所有目录
a=[x for x in os.listdir('.') if os.path.isdir(x)]
print(a)
#列出所有的.py
b= [x for x in os.listdir('.') if os.path.isfile(x) and os.path.splitext(x)[1]=='.py']
print(b)
序列化与反序列化
在程序运行的过程中,所有的变量都是在内存中,可以随时修改变量,但一旦程序结束,变量所占用的内存就会被操作系统回收
把变量从内存中变成可存储或传输的过程称之为序列化
把变量内容从序列化的对象重新读到内存里称之为反序列化
import pickle
d = dict(name='Bob', age=20, score=88) #定义一个dict
print(d)
a=pickle.dumps(d) #将对象系列化成bytes
print(a)
f = open('D:\\PythonCode\\PythonStudy\\Study01\\test01.txt', 'wb')
pickle.dump(d, f) #将对象序列化写入文件
f.close()
f = open('D:\\PythonCode\\PythonStudy\\Study01\\test01.txt', 'rb')
d = pickle.load(f)
f.close()
print(d)
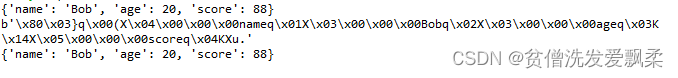
如果我们要在不同的编程语言之间传递对象,就必须把对象序列化为标准格式,比如XML,但更好的方法是序列化为JSON,因为JSON表示出来就是一个字符串,可以被所有语言读取,也可以方便地存储到磁盘或者通过网络传输。JSON不仅是标准格式,并且比XML更快,而且可以直接在Web页面中读取,非常方便。
JSON和Python内置的数据类型对应如下:
| JSON类型 | Python类型 |
|---|---|
| {} | dict |
| [] | list |
| “string” | str |
| 1234.56 | int或float |
| true/false | True/False |
| null | None |
Python内置的json模块提供了非常完善的Python对象到JSON格式的转换
python对象--------->Json对象
import json
d={
'name':'Bob', 'age':20, 'score':88}
f=json.dumps(d) #装换为json格式 ,返回一个str类型
print(f)
f1 = open('D:\\PythonCode\\PythonStudy\\Study01\\test01.txt', 'w')
f2=json.dump(d,f1) #直接把JSON写入一个file中
f1.close()
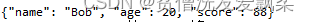
Json对象--------->python对象
f3=json.loads(f)
print(f3)
f4 = open('D:\\PythonCode\\PythonStudy\\Study01\\test01.txt', 'r')
f5=json.load(f4) #读取文件中的字符串并反序列化python对象
print(f5)
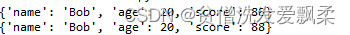
自定义对象--------->Json对象
默认情况下,dumps()方法不知道如何将Student实例变为一个JSON的{}对象。
json模块的dumps()和loads()函数,通过传入参数定制序列化或反序列化的规则
class Student(object):
def __init__(self, name, age, score):
self.name = name
self.age = age
self.score = score
stu1=Student('刘恒',20,100)
print('-------------我们需要告诉它如何进行转换成json----------------')
def studentdict(std):
return {
'name': std.name,
'age': std.age,
'score': std.score
}
d=json.dumps(stu1,default=studentdict)
print(d)
#class的实例都有一个__dict__属性,它就是一个dict,用来存储实例变量,但定义了__slots__的class不行。
print(json.dumps(stu1, default=lambda obj: obj.__dict__))

Json对象--------->自定义对象
print('-------------我们需要告诉它如何进行转换成python对象----------------')
def dictstudent(d):
return Student(d['name'], d['age'], d['score'])
print(json.loads(d, object_hook=dictstudent))

6.多进程
进程:是并发执行的程序在执行过程中分配和管理资源的基本单位,是一个动态概念,竞争计算机系统资源的基本单位。
Process类的使用
multiprocessing模块就是跨平台版本的多进程模块。
multiprocessing模块提供了一个Process类来代表一个进程对象
os.getpid可以获取当前进程的PID,
os.getppid 可以获取当前进程的主进程的PPID
start()方法用于子进程的启动
join()方法可以等待子进程结束后再继续往下运行,通常用于进程间的同步
from multiprocessing import Process
import os
# 子进程要执行的代码
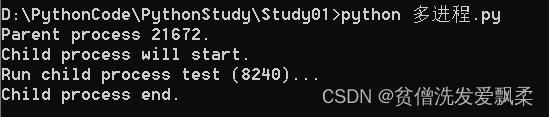
def run_proc(name):
print('Run child process %s (%s)...' % (name, os.getpid()))
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Process(target=run_proc, args=('test',))
print('Child process will start.')
p.start()
p.join()
print('Child process end.')
spyder输出:
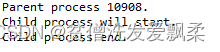
子进程方法并没有执行
但在cmd和pycharm里面运行,是可以有输出结果的
用进程池的方式批量创建子进程
from multiprocessing import Pool
import os, time, random
def long_time_task(name):
print('Run task %s (%s)...' % (name, os.getpid()))
start = time.time()
time.sleep(random.random() * 3)
end = time.time()
print('Task %s runs %0.2f seconds.' % (name, (end - start)))
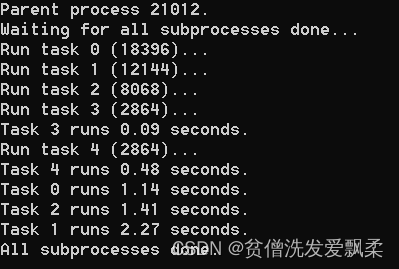
if __name__=='__main__':
print('Parent process %s.' % os.getpid())
p = Pool(4)
for i in range(5):
p.apply_async(long_time_task, args=(i,))
print('Waiting for all subprocesses done...')
p.close()
p.join()
print('All subprocesses done.')
调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process
注意输出的结果,task 0,1,2,3是立刻执行的,而task 4要等待前面某个task完成后才执行,这是因为Pool设置的参数是4,因此,最多同时执行4个进程。
Pool的默认大小是CPU的核数
进程间通信
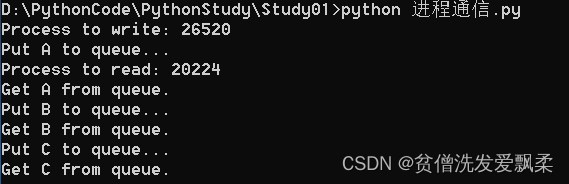
from multiprocessing import Process, Queue
import os, time, random
# 写数据进程执行的代码:
def write(q):
print('Process to write: %s' % os.getpid())
for value in ['A', 'B', 'C']:
print('Put %s to queue...' % value)
q.put(value)
time.sleep(random.random())
# 读数据进程执行的代码:
def read(q):
print('Process to read: %s' % os.getpid())
while True:
value = q.get(True)
print('Get %s from queue.' % value)
if __name__=='__main__':
# 父进程创建Queue,并传给各个子进程:
q = Queue()
pw = Process(target=write, args=(q,))
pr = Process(target=read, args=(q,))
# 启动子进程pw,写入:
pw.start()
# 启动子进程pr,读取:
pr.start()
# 等待pw结束:
pw.join()
# pr进程里是死循环,无法等待其结束,只能强行终止:
pr.terminate()
7.多线程
线程:线程是处理器调度的基本单位,是进程的一个执行单元,是进程内科调度实体。比进程更小的独立运行的基本单位。线程也被称为轻量级进程。
Python的标准库提供了两个模块:_thread和threading,
_thread是低级模块,threading是高级模块,对_thread进行了封装。
绝大多数情况下,我们只需要使用threading这个高级模块。
使用threading模块
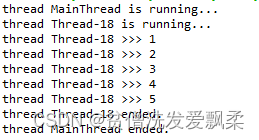
import time, threading
# 新线程执行的代码:
def loop():
print('thread %s is running...' % threading.current_thread().name)
n = 0
while n < 5:
n = n + 1
print('thread %s >>> %s' % (threading.current_thread().name, n))
time.sleep(1)
print('thread %s ended.' % threading.current_thread().name)
print('thread %s is running...' % threading.current_thread().name)
t = threading.Thread(target=loop)
t.start()
t.join()
print('thread %s ended.' % threading.current_thread().name)
多线程中,所有变量都由所有线程共享,多线程会引发并发问题(死锁等)
如下测试:
def change_it(n):
# 先存后取,结果应该为0:
global balance
balance = balance + n
balance = balance - n
def run_thread(n):
for i in range(2000000):
change_it(n)
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)

Lock线程锁
balance = 0
lock = threading.Lock()
def change_it(n):
# 先存后取,结果应该为0:
global balance
balance = balance + n
balance = balance - n
def run_thread(n):
for i in range(2000000):
lock.acquire() #获取锁
try:
change_it(n)
finally:
lock.release() #释放锁
t1 = threading.Thread(target=run_thread, args=(5,))
t2 = threading.Thread(target=run_thread, args=(8,))
t1.start()
t2.start()
t1.join()
t2.join()
print(balance)

Python的线程虽然是真正的线程,但解释器执行代码时,有一个GIL锁:Global Interpreter Lock,任何Python线程执行前,必须先获得GIL锁,然后,每执行100条字节码,解释器就自动释放GIL锁,让别的线程有机会执行。这个GIL全局锁实际上把所有线程的执行代码都给上了锁,所以,多线程在Python中只能交替执行,即使100个线程跑在100核CPU上,也只能用到1个核。
ThreadLocal
一个ThreadLocal变量虽然是全局变量,但每个线程都只能读写自己线程的独立副本,互不干扰。ThreadLocal解决了参数在一个线程中各个函数之间互相传递的问题。
ThreadLocal最常用的地方就是为每个线程绑定一个数据库连接,HTTP请求,用户身份信息等
import threading
# 创建全局ThreadLocal对象:
local_school = threading.local()
def process_student():
# 获取当前线程关联的student:
std = local_school.student
print('Hello, %s (in %s)' % (std, threading.current_thread().name))
def process_thread(stu):
# 绑定ThreadLocal的student:
local_school.student = stu
process_student()
t1 = threading.Thread(target= process_thread, args=('Alice',), name='Thread-A')
t2 = threading.Thread(target= process_thread, args=('Bob',), name='Thread-B')
t1.start()
t2.start()
t1.join()
t2.join()

进程与线程的区别
地址空间:
线程共享本进程的地址空间,而进程之间是独立的地址空间。
资源:
线程共享本进程的资源如内存、I/O、cpu等,不利于资源的管理和保护,而进程之间的资源是独立的,能很好的进行资源管理和保护。
健壮性:
多进程要比多线程健壮,一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。
执行过程:
每个独立的进程有一个程序运行的入口、顺序执行序列和程序入口,执行开销大。
但是线程不能独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制,执行开销小。
切换时:
进程切换时,消耗的资源大,效率高。所以涉及到频繁的切换时,使用线程要好于进程。
同样如果要求同时进行并且又要共享某些变量的并发操作,只能用线程不能用进程。
8.datetime模块
datetime处理日期和时间的标准库
datetime模块包含一个datetime类,通过from datetime import datetime导入的就是datetime这个类。
datetime转换为timestamp(时间戳)
在计算机中,时间实际上是用数字表示的。我们把1970年1月1日 00:00:00 UTC+00:00时区的时刻称为epoch time,记为0
当前时间就是相对于epoch time的秒数,称为timestamp
timestamp是一个浮点数,它没有时区的概念,而datetime是有时区的
from datetime import datetime
now = datetime.now() #获取当前的时间
print(now)
print(type(now))
d=datetime(2020,1,11,12,00)
print(d) #指定某个日期和时间
t=d.timestamp()
print(t) #将指定的datatime转换为时间戳
f=datetime.fromtimestamp(t) #将时间戳转换为datetime本地时间
print(f)
print(datetime.utcfromtimestamp(t)) #UTC时间 UTC+0:00
print('--------------str转换为datetime--------------')
cday = datetime.strptime('2015-6-1 18:19:59', '%Y-%m-%d %H:%M:%S')
print(cday)
print(type(cday))
print('--------------str转换为datetime--------------')
day=cday.strftime('%Y-%m-%d %H:%M:%S')
print(day)
print(type(day))
print('--------------datetime加减-----------------')
from datetime import datetime, timedelta
now = datetime.now()
print(now)
day1=now + timedelta(hours=10)
print(day1)
day2= now - timedelta(days=1)
print(day2)
day3= now - timedelta(days=2,hours=5,minutes=10)
print(day3)
print('--------------本地时间转换为UTC时间-----------------')
from datetime import datetime, timedelta, timezone
tz_utc_8 = timezone(timedelta(hours=8)) # 创建时区UTC+8:00
now = datetime.now()
dt = now.replace(tzinfo=tz_utc_8) # 强制设置为UTC+8:00
print(dt)
print('------------拿到UTC时间,并强制设置时区为UTC+0:0----------')
utc_dt = datetime.utcnow().replace(tzinfo=timezone.utc)
print(utc_dt)
print('-------------换时区为北京时间:-----------------------')
bj_dt = utc_dt.astimezone(timezone(timedelta(hours=8)))
print(bj_dt)
print('-------------转换时区为东京时间:-----------------------')
tokyo_dt2 = bj_dt.astimezone(timezone(timedelta(hours=9)))
print(tokyo_dt2)
