转自知乎 :https://zhuanlan.zhihu.com/p/32960452 通俗易懂
https://zhuanlan.zhihu.com/p/30676249 数学解释
https://zhuanlan.zhihu.com/p/23987221 一些参数理解
通过前面的学习和讲解,我们知道了AdaBoost是一种ensemble learning,它是Boosting算法族中的著名代表。当时在讲ensemble learning的时候,仅仅是介绍了一下具体的内容和框架。在讲解随机森林和决策树的时候,重点讲解了Bagging。那么,这一节开始,就来讲讲boosting的重要应用,AdaBoost。
Boosting:
先简单的回忆一下boosting是怎么样的一类算法?
- boosting是将弱学习算法提升为强学习算法的一类算法。
- 先从初始训练集训练一个基学习器。
- 再根据基学习器的表现对训练样本分布进行重调,使得先前基学习器做错的样本在后续受到更多的关注
- 然后,基于调整后的样本分布来训练下一个基学习器
- 一直重复上述步骤,直到基学习器的个数达到train前的指定数T,然后将这T个基学习器进行加权
直到了boosting的过程,那么adaboost其实就是Adaptive Boosting
算法流程如下:
- 输入:训练集
,训练轮数T,和一个基学习算法L
- 首先,让所有数据的权重都为
- 然后,对于每一轮的train过程,得到一个基学习器
- 计算这个基学习器
在训练数据集D上的误差
- 如果这个误差大于0.5,那么直接停止本轮的train,进行下一轮
- 计算此轮基学习器在最终的模型中所占的权重
- 对于在这一轮基学习器中做错的样本和做对的样本进行调整:
- 上述中的
是一个规范化因子
- 最终,得到ensemble后的model为
model构建过程的图示如下:
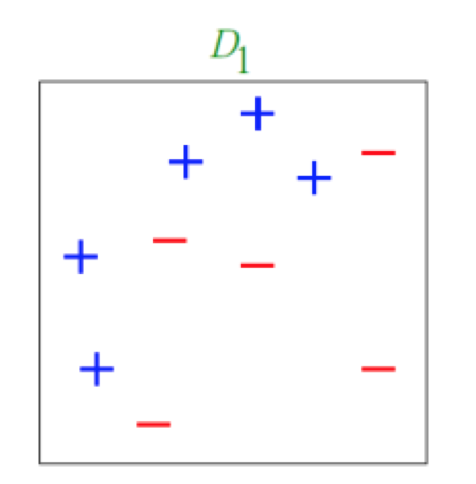
最初的训练集,并且每个样本都有一个权重
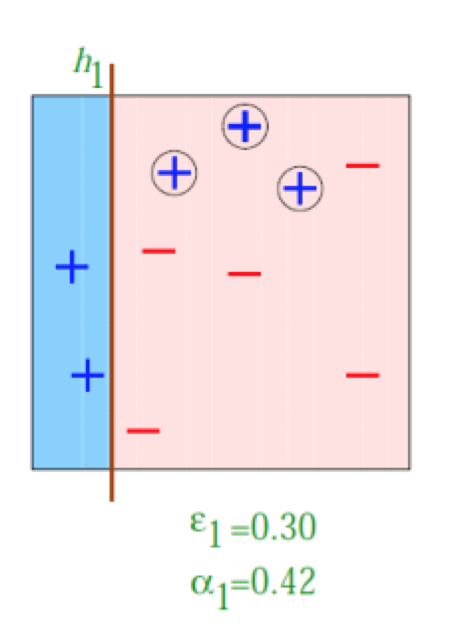
经过t=1的train后,得到的结果,发现右边的三个样本被分类错误了,那么就加重对于他们的的权重,而对于分类正确的样本进行减弱。
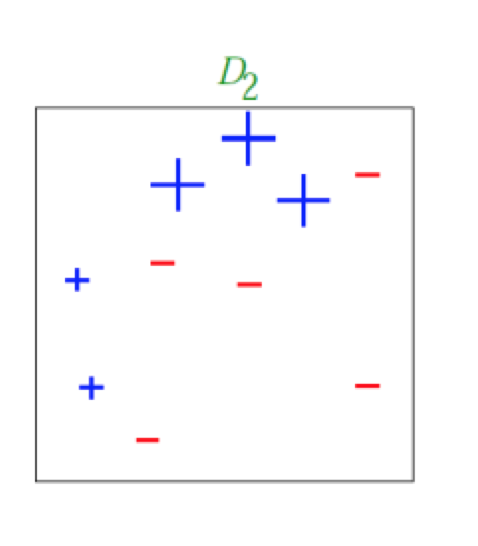
得到如上图所示的样本。
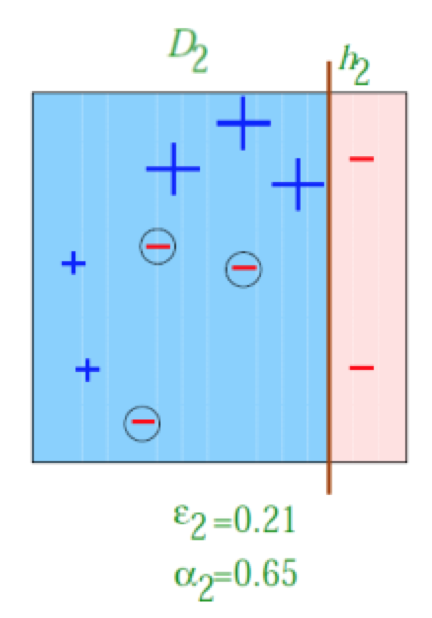
学习到的第二个基学习器 ,此时,左边的三个样本被分类错误,所以,我们增大他们的相关权重,减小分类正确点的权重。
得到如上图所示的样本
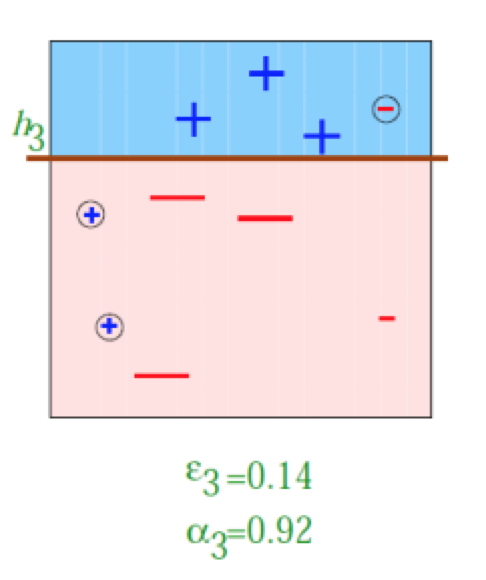
然后在训练出第三个基学习器
最终,将上述三个学习器全部通过线性加权,得到最终的model
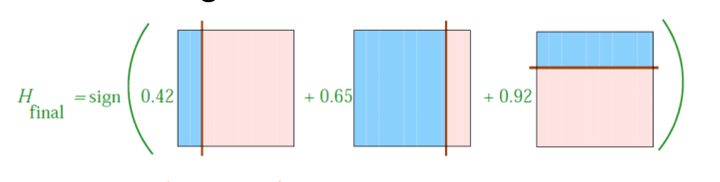
用这个model对于最初的样本数据进行划分,得到如下的结果
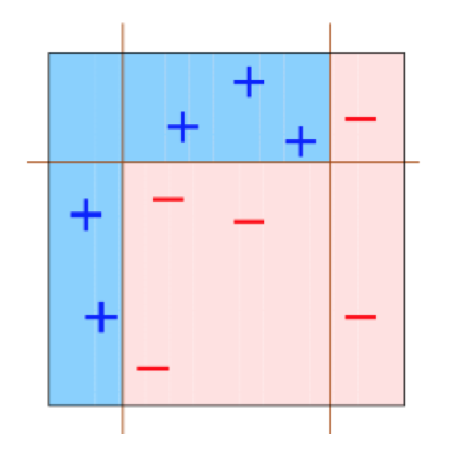
是不是通过上面的学习,我们发现了adaboost具有很棒的性能呢?他其实就相当于把不同的learner按照一定的权重进行组合,使得这些learner之间尽可能做到相互补充,来共同完成一项任务,关于组合的权重,肯定是哪个learner的error小,那么,他的权重就相对大一些。
讲完了AdaBoost算法,我们再来讲解一个有关AdaBoost算法经常涉及的一个问题。
为什么在使用AdaBoost算法的过程中,不容易出现overfitting呢?
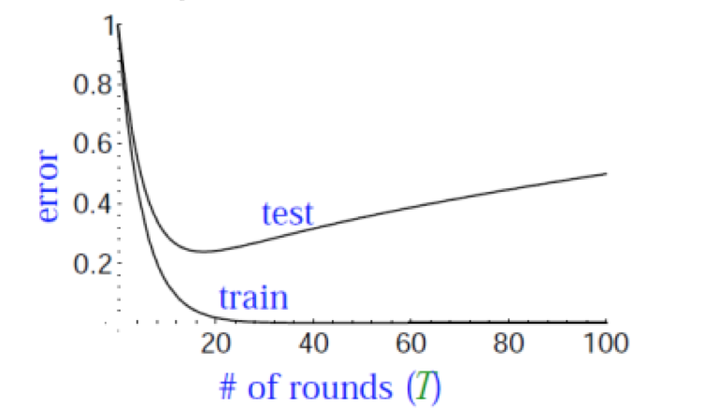
观察上图,overfitting问题是机器学习中经常碰到的一个问题,我们发现,在train error下降到几乎为0的过程中,test error往往会经过一个先下降,然后在上升的过程。
我们对于上述现象最一般的解释就是:最终的model太复杂了。
对于一般的机器学习问题,训练误差和泛化误差的关系,前面的几讲也都讲过了,我们再来回顾下。
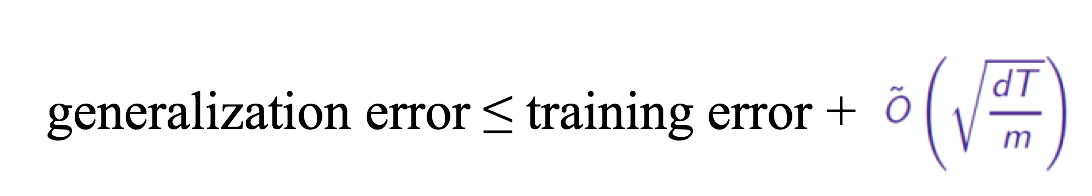
- 就拿adaboost算法来说,T相当于训练的轮数
- m是训练样本的个数
- d表示模型的复杂度
通过这个公式,我们知道,如果训练的轮数T越多,那么不等式的右边就会不断变大,使得左边的上界不断被放大,最终得到的结果是test error会不断的提高。
理论上这么分析,看起来没有什么问题,但是实际上却是下图的结果
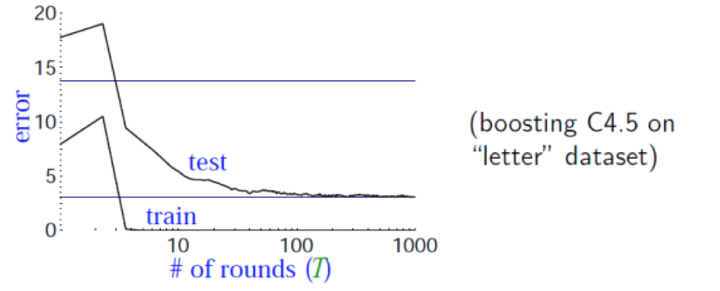
test error并没有增加,而且在这个实验中,我们的T已经达到了1000,test error反而下降了

甚至在train error都已经达到了0的时候,test error还在一直下降。
这似乎和我们上面分析一般机器学习方法出现overfitting的例子有些不温和,现在,我们来分析分析,为什么会出现这样的问题。
解释这个现象,就得介绍一个非常重要的理论了:Margin Theory

其实,这个边界就说明了,如果训练数据集上的margin越大,那么最终在测试集上的error就会越小。那么,有了这个理论的支撑,我们是不是就明白了为什么在用adaboost的过程中,不容易出现overfitting。
答:即使train error已经接近0了,但是在做ensemble的过程中,得到的ensemble margin变得越来越大了。
要解释margin theory,我们需要下面的几个概念:
- 在一般我们做分类的任务中,我们往往关注的是分类的结果,对还是错
- 其实,在讲SVM的过程中,我就提到了margin这个词,他表明了一种分类的confidence。也就是说是衡量这个classifier能不能把这个样本分类正确或者错误的程度是多少。
- 如果一个classifier能够把一个样本以很大的程度分类到正确的类别或者错误的类别,那么该classifier的泛化能力肯定是要比confidence低的classifier强的
- 回想我们在做adaboost的过程,最终model的分类性能其实是由这T个基(弱)学习器来共同加权决定的
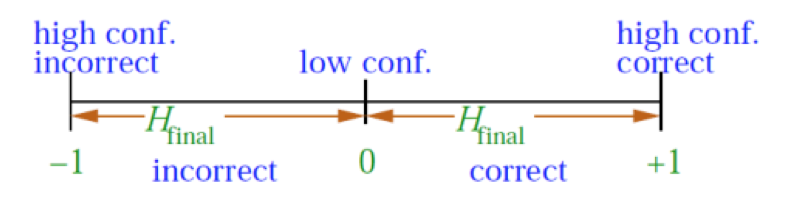
上图就表明了这种confidence的高低程度。
在实验的过程中,得到最终的margin 累加分布,从实验结果可以看出,比较了T=1000和T=100时候margin的变化,发现了test error 主要是通过min margin是在不断变大而起作用的
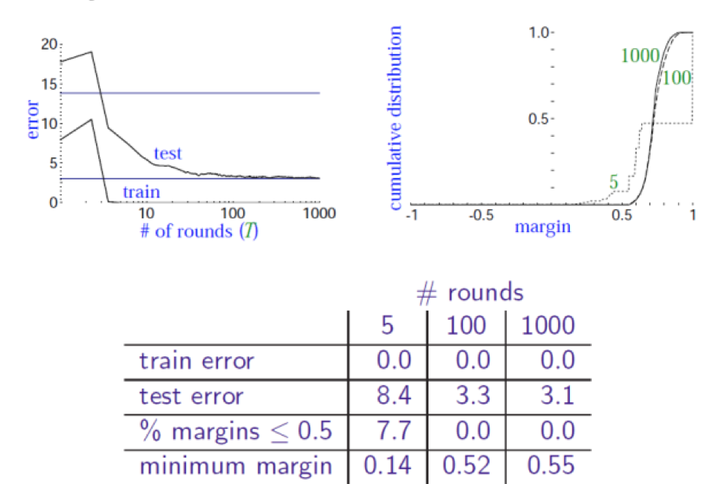
所以说,通过上面的实验,我们得到了下面的结论:
- 在训练集上的margin越大(也可以说min margin越大),那么test error就越低,test error是独立于T而存在的
- boosting算法在做ensemble的过程中,是在不断的增大training set的margin的,这个条件成立的前提是这些基(弱)学习器有如下的特征:
- 基学习器相对于整个训练集的规模来说, 不能太复杂
- 每个基学习器自身必须有较大的edge,也即有较大的margin
- 举个例子:我们经常提到的 boosting+decision tree的算法
- 在这个例子中,tree往往由很大的edge,并且他的复杂度也是受限的,不可能太过复杂
- 那么,如果上面的条件不满足,比如说:
- 每个基学习器都太过复杂
- 而且每个基学习器的edge都太小,那么boosting就很容易出现overfitting的问题
好了,这一讲就为大家讲述了adaboost算法,该算法有一个非常有名的应用,就是通过haar特征+adaboost做人脸检测,等考完试后,我会把相关paper和应用更新到我的另外一个专栏:图像处理与计算机视觉 中,供大家一起学习与参考。
一些参数介绍
Adaboost是一种迭代算法,其核心思想是针对同一个训练集训练不同的分类器(弱分类器),然后把这些弱分类器集合起来,构成一个更强的最终分类器(强分类器)。
训练过程如下:
简单的来说:图中的y1(x),y2(x)....ym(x)都是弱分类器(顾名思义,弱分类器就是分类能力很弱,仅比随机分类好一点点的分类器)
首先我们初始化了弱分类器y1(x)
然后对y1(x)进行迭代处理产生了分类器y2(x)
然后对y2(x)迭代处理产生了y3(x)...
依次迭代最后产生弱分类器ym(x)。
最后,将m个分类器加权处理,得到一个强处理器。通俗的讲,可以理解为每个若处理器的分类能力都很弱,但是三个臭皮匠赛过诸葛亮,大家一起表决的话,群众的判断还是准确的。
下面开始详细介绍。
首先介绍几个关键的参数。
1.样本权重D
假设我们再训练样本集的时候一共有N个样本,我们赋予每个样本一个权重系数Di。这个系数主要是用来衡量该样本能被正确分类的难易程度。
在每次迭代的过程中:
如果第i个样本被正确分类了,那么在下一次迭代过程中,该样本的权重DiI就会降低。
如果第i个样本没有被正确分类,那么在下次迭代过程中,该样本的权重Di就会升高。
公式如下:
样本的权重值的作用在于单次循环中筛选最优的弱分类器,这个待会儿我会讲到的。
2.错误率 ε
这个就不解释了,主要是用来判断弱分类器的性能的。
3.弱分类器的权重系数α。
注意这个与前面的样本权重D的区别,这个是衡量每个弱分类器的能力的指标,看刚才这张图
我们一共要用到M个若分类器,但是每个分类器的重要性是不一样的。就像人代会,常委说话的分量要比普通委员大一样。所以在累加的过程中,我们给每个弱分类器乘了一个权重系数α。
看完通俗的部分我们从数学角度了解下
Adaboost算法:先从初始训练集合中训练出一个基学习器,再根据基学习器的表现对训练样本的权重进行调整,使得先前基学习器做错的样本在后续得到更多的关注,然后基于调整后的样本权重来训练下一个基学习器,直到基学习器的数目达到事先指定的数目M,最终将这M个学习器进行加权组合。
首先我们假设给定一个二分类的训练数据集:
其中 ,
。
初始化样本的权重为:
第m个基分类器的样本权重为:
我们构建M个基学习器,最终的学习器即为基学习器的线性组合:
其中 为第i个基学习器的系数,
为第i个基学习器。
接下来我们定义 在训练集合中的分类误差率为:
也就是说 在加权训练数据集中的分类误差率为被误分类的样本权值之和。注意一下,我们定义的基学习器,其
。.
接着我们定义损失函数为指数损失函数:
其中y是样本的实际类别,f(x)是预测的类别,样本x的权重服从D分布。E代表求期望。
损失函数为什么这样定义?下面一起证明一下:
若f(x)能使损失函数最小化,那我们考虑上式对f(x)的偏导为零:
令上式为零,得:
因此,有
当P(y=1|x)>P(y=-1|x)时,sign(f(x))=1
当P(y=1|x)>P(y=-1|x)时,sign(f(x))=-1
这样的分类规则正是我们所需要的,若指数函数最小化,则分类错误率也最小,它们俩是一致的。所以我们的损失函数可以这样定义。
定义完了损失函数,我们看怎么来进行基分类器 和系数
的求取。
第一个分类器G1(x)是直接将基学习算法用于初始数据分布求得,之后不断迭代,生成 和
。当第m个基分类器产生后,我们应该使得其在数据集第m轮样本权重基础上的指数损失最小,即
首先,我们求解 ,对任意的
,最优的
应为:
其中 是第m轮训练样本的权重。
就是在第m轮中使得加权训练样本误差率最小的分类器。
在得到 后,我们来求
。
应该使得损失函数最小,所以令下式对
求导等于零:
得到 的表达式:
由于 ,所以
,且
随着
的减小而增大。
这时候我们就可以得到Adaboost的迭代公式:
这时候就只剩下最后一个问题,之前说,我们会根据基学习器的表现对训练样本的权重进行调整,使得先前基学习器做错的样本在后续得到更多的关注。那训练样本的权重分布 应该怎么变化呢?
这一部分在周志华老师《机器学习》P175有详细的推导,感兴趣的读者可以自行查阅。我这里直接给出 的迭代公式,并证明其可行性。
其中 ,是一个常数。
上面就是样本权重 的迭代公式。我们发现:
当 时:
当 时:
由于 ,从上面的式子可以看到,当样本i上一次被误分类时,其下一次的权重
会变大;而当样本i上一次被分类正确时,其下一次的权重
会变小。因此,误分类样本在下一轮学习中起到的作用更大,这也是Adaboost的一个特点。
以上就是Adaboost算法原理部分的全部内容,从基学习器到其系数,再到数据集合的权重迭代,我们都给出了较为详细的公式推导。希望给大家一些帮助。
Adaboost算法的误差
先给大家结论:随着集成学习中个体分类器数目的增加,其集成的错误率将成指数级下降,最终趋向于零。
当然,如果分类器数目过多也会发生过拟合现象,导致分类器的泛化能力不强,所以我们应该在其中寻求一种平衡。
关于算法误差这个点,李航老师《统计学习方法》P142和周志华老师《机器学习》P172页都有解释。李航老师的证明更为详细。周志华老师的证明用到了Hoeffding不等式。
最终得到的不等式:
我们发现,随着个体分类器数目的增加,其集成的错误率将成指数级下降。当然前提条件是每个基分类器的分类正确率要高于50%,即 .
代码实现与注释
在下面的程序中,基分类器选用的是决策树,但是基分类器可以选取我们所知道的任意一个分类器都可以,比如神经网络等。
1.单层决策树生成函数
程序清单:
from numpy import *
# 加载数据
def loadsimpData():
dataMat=matrix([[1,2.1],
[2,1.1],
[1.3,1],
[1,1],
[2,1]])
classLabels=[1,1,-1,-1,1]
return dataMat,classLabels
# 单层决策树生成函数
# dimen是哪一个特征;threshVal是特征阈值;threshIneq是大于还是小于
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):
# 初始化一个全1列表
retArray=ones((shape(dataMatrix)[0],1))
if(threshIneq=='lt'):
# 以阈值划分后,小于等于阈值的,类别定为-1
retArray[dataMatrix[:,dimen]<=threshVal]=-1.0
else:
retArray[dataMatrix[:,dimen]>threshVal]=-1.0
return retArray
# D是权重向量
def buildStump(dataArr,classLabels,D):
dataMatrix=mat(dataArr);labelMat=mat(classLabels).T
m,n=shape(dataMatrix)
numSteps=10.0;bestStump={};bestClassEst=mat(zeros((m,1)))
# 最小值初始化为无穷大
minError=inf
# 对每一个特征
for i in range(n):
# 找到最大值和最小值
rangeMin=dataMatrix[:,i].min()
rangeMax=dataMatrix[:,i].max()
# 确定步长
stepSize=(rangeMax-rangeMin)/numSteps
for j in range(-1,int(numSteps)+1):
for inequal in ['lt','gt']:
# 得到阈值
threshVal=(rangeMin+float(j)*stepSize)
# 调用函数,并得到分类列表
predictedVals=stumpClassify(dataMatrix,i,threshVal,inequal)
# 初始化errArr
errArr=mat(ones((m,1)))
# 将errArr中分类正确的置为0
errArr[predictedVals==labelMat]=0
# 计算加权错误率
weightedError=D.T*errArr
# print("split:dim %d,thresh %.2f,thresh inequal:"
# "%s,the weighted error is %.3f"%(i,threshVal,
inequal,weightedError))
# 如果错误率比之前的小
if(weightedError<minError):
minError=weightedError
# bestClassEst中是错误最小的分类类别
bestClassEst=predictedVals.copy()
bestStump['dim']=i
bestStump['thresh']=threshVal
bestStump['ineq']=inequal
return bestStump,minError,bestClassEst
2.基于单层决策树的Adaboost训练过程
程序清单:
# 基于单层决策树的Adaboost训练过程
# numIt表示最多迭代的次数
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr=[]
m=shape(dataArr)[0]
# 初始化权重矩阵D,1/m
D=mat(ones((m,1))/m)
# 初始化,aggClassEst里面存放的是类别估计的累计值
aggClassEst=mat(zeros((m,1)))
for i in range(numIt):
bestStump,error,classEst=buildStump(dataArr,classLabels,D)
print("D:",D.T)
# 计算分类器的系数;max()的作用是防止error=0
alpha=float(0.5*log((1.0-error)/max(error,1e-16)))
bestStump['alpha']=alpha
weakClassArr.append(bestStump)
print("classEst:",classEst.T)
# 下面三行是对权重向量进行更新,具体公式推导见正文
expon=multiply(-1*alpha*mat(classLabels).T,classEst)
D=multiply(D,exp(expon))
D=D/D.sum()
# 计算类别估计的累加值
aggClassEst+=alpha*classEst
print('aggClassEst:',aggClassEst.T)
# 计算分类错误的个数
aggErrors=multiply(sign(aggClassEst)!=mat(classLabels).T,
ones((m,1)))
# 计算分类错误率
errorRate=aggErrors.sum()/m
print("total error:",errorRate,"\n")
# 如果分类错误率为0,则结束
if(errorRate==0):break
# 返回建立的分类器列表
return weakClassArr
3.Adaboost分类函数
程序清单:
# adaBoost分类函数
# datToClass是待分类数据;classifierArr是建立好的分类器列表
def adaClassify(datToClass,classifierArr):
dataMatrix=mat(datToClass)
m=shape(dataMatrix)[0]
aggClassEst=mat(zeros((m,1)))
# 对每一个弱分类器
for i in range(len(classifierArr)):
# 得到分类类别
classEst=stumpClassify(dataMatrix,classifierArr[i]['dim'],
classifierArr[i]['thresh'],
classifierArr[i]['ineq'])
# 计算类别估计累加值
aggClassEst+=classifierArr[i]['alpha']*classEst
print(aggClassEst)
# 返回类别;sign(x)函数:x>0返回1;x<0返回-1;x=0返回0
return sign(aggClassEst)
# 自适应数据加载函数
def loadDataSet(fileName):
# 得到特征数目
numFeat=len(open(fileName).readline().split('\t'))
dataMat=[];labelMat=[]
fr=open(fileName)
for line in fr.readlines():
lineArr=[]
curLine=line.strip().split('\t')
# 对每一个特征
for i in range(numFeat-1):
lineArr.append(float(curLine[i]))
dataMat.append(lineArr)
labelMat.append(float(curLine[-1]))
# 返回特征矩阵和类别矩阵
return dataMat,labelMat
以上就是Adaboost算法的全部内容,下一节我们一起学习线性回归、局部加权线性回归和收缩方法。
声明
最后,所有资料均本人自学整理所得,如有错误,欢迎指正,有什么建议也欢迎交流,让我们共同进步!转载请注明作者与出处。
以上原理部分主要来自于《机器学习》—周志华,《统计学习方法》—李航,《机器学习实战》—Peter Harrington。代码部分主要来自于《机器学习实战》,代码用Python3实现,这是机器学习主流语言,本人也会尽力对代码做出较为详尽的注释