python和jieba库进行简单文本处理之天龙八部小说
本文会涉及到一些内置函数,正则化表达式,文本写作风格挖掘(排版,篇章,用词),简单的文本相似度比较
本人大一新手一枚≧∇≦,偶然碰到某次作业为简单文本处理,就写了这文章来给需要的小伙伴提供点思路,代码中有许多不足,希望各位大佬可以指正下哈!多谢啦^ _ ^!
天龙八部小说和人物名字txt文本大家可以去网上找,很多热心小伙伴会发的.
导入jieba和gensim库
我一开始直接在Anaconda的cmd中pip install jieba会报错,所以要去下载jieba库到自己的电脑,jieba(官方下载地址): https://pypi.org/project/jieba/
打开后点download files ,在里面下载jieba就好了,下载好之后打开jieba文件所在位置,获得其路径(可以把它拉入cmd中就会显示绝对路径),然后打开cmd, 输入 cd +绝对路径 ,回车,然后输入python setup.py install就可以了,检验是否安装好可以在编译器中输入import jieba看看有没有报错.
看不懂我写的可以参考下面这个网址(这个讲的非常详细滴):https://blog.csdn.net/sanqima/article/details/50965439
导入gensim库可以直接在Anaconda的cmd中输入(用个快的镜像节点就好啦)
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple gensim
可参考下面这篇文章:
https://blog.csdn.net/zhujiyao/article/details/81112545
数据清洗,处理小说和人物名称文本
处理天龙八部txt小说文本
import jieba
import re
from gensim import corpora,models,similarities
#读入数据文件
with open(r'C:\Users\k\Desktop\新建文件夹\天龙八部.txt', "r") as f: # 打开文件
data = f.read() # 读取文件
#分割字符串
data = data.split('\n\n') #根据文本无用内容来进行分隔
data.remove('') #处理后的文章在一个列表里面
for i in range(len(data)):
data[i] = re.sub('萧峰','乔峰',data[i]) ##因为原文中萧峰和乔峰是同一个人,用正则化表达式将萧峰替换成乔峰
data[i] = re.sub('慕容先生','慕容博',data[i]) #将慕容先生称呼替换成慕容博
data[i] = re.sub('慕容公子','慕容复',data[i])
data_str = ''.join(data) #以字符串方式储存
处理天龙八部人物txt文本
with open(r'C:\Users\k\Desktop\新建文件夹\天龙八部人物名称.txt', "r", encoding = 'UTF-8') as f: # 打开文件
dataname = f.read() # 读取文件
dataname = dataname.split('\u2002') #根据无用内容分割字符串,处理后装在一个列表里面
文章排版分析之统计章标题
biaotilist = [] #装标题名字
for i in range(len(data)): #len(data)等于50
biaotilist.append(re.findall(r'(.*)\n', data[i][:50])[0]) #运用正则化表达式提取出标题
print('文章排版分析,共%s章,标题如下:'%len(biaotilist), biaotilist)
打印出结果为:

文章篇章分析之谁是天龙八部小说的主角
for i in range(len(dataname)):
dataname[i] = ''.join(re.findall('[\u4e00-\u9fa5]',dataname[i]))#运用正则化表达式来提取名字
data_name = dataname[:]#这是为了后面操作成字符串形式写的
#统计每个人出现的次数
for j in range(len(dataname)):
num = 0 #计数器
for i in range(len(data)):
num = num + len(re.findall(dataname[j],data[i]))#正则化判断data中是否存在dataname中名字,有就+1
dataname[j] = [str(dataname[j]), num] #变成二维列表形式
dataname=dict(dataname)#将二维列表变成字典
dataname=sorted(dataname.items(), key=lambda a: a[1], reverse=True) #按高到低顺序,按照列表中第二个元素排序,以字典形式储存
print('文章篇章分析:“%s”这个名字在小说中的出场频率是最高的.所以是天龙八部小说主角'%dataname[0][0],dataname[:5]) #打印出排名前五的名字及次数
打印出结果为:

这里是没替换慕容博的打印结果:

文章用词分析之出现最多的四字词
这里需要自定义词典,要在jieba文件目录下建一个txt文本(jieba相关操作可参考这里)

#用jieba进行分词处理
jieba.load_userdict('C:/jieba/jieba-0.42.1/jieba/name.txt') #自定义词典
counts = {
}
wordslist =jieba.lcut(data_str) #精准模式分词,data_str为小说文本字符串
#将小说文本列表中人物的名字剔除,方便处理用词分析的四字词
new_wordslist = [i for i in wordslist if i not in data_name]
for word in new_wordslist:
word = word.replace(",", "").replace("!", "").replace('i','').replace("“", "") \
.replace("”", "").replace("。", "").replace("?", "").replace(":", "") \
.replace("...", "").replace("、", "").strip(' ').strip('\r\n') #将文本中标点符号去除
if len(word)>3 : #筛选长度为4的
counts[word]=counts.get(word,0)+1 #词计数
items = list(counts.items()) #将字典转为list
items.sort(key=lambda x:x[1],reverse=True) #根据单词出现次数降序排序
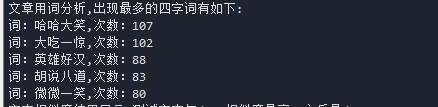
print('文章用词分析,出现最多的四字词有如下:')
#打印前5个
for i in range(5):
word,counter = items[i]
print("词:{},次数:{}".format(word,counter))
#绘制饼图
fig=plt.figure()
labels = word_new
data = counter_new
matplotlib.rcParams['font.sans-serif']=['SimHei'] #使用指定的汉字字体类型(此处为黑体,解决汉字乱码问题
plt.pie(data,labels=labels,autopct='%1.2f%%') #autopct='%1.2f%%'输出各块饼状图所占百分比并保存两位小数
plt.title('出现最多的四字词的占比')
plt.show()
打印出结果为:

文本相似度分析
doc_test = data_str #选取天龙八部小说作为测试文本,注意要为字符串格式
#编辑两个目标文本
doc0 = " ".join('%s' %id for id in data_name) #用名字文本作为一个目标文本
doc1 = "段誉为人豁达开朗,风流倜傥,潇洒不羁,又很痴情" #自己定义了个字符串来测试
all_doc = []
all_doc_list = []
#目标文本
all_doc.append(doc0)
all_doc.append(doc1)
#目标文本进行分词,并且保存在列表all_doc_list中
for doc in all_doc:
doc_list = [word for word in jieba.cut(doc)]
all_doc_list.append(doc_list)
doc_test_list = [word for word in jieba.cut(doc_test)]#测试文本也进行分词,并保存在列表doc_test_list中
#用dictionary方法获取词袋(bag-of-words)
dictionary = corpora.Dictionary(all_doc_list)
#用数字对所有词进行了编号
dictionary.keys()
#编号与词之间的对应关系
dictionary.token2id
#使用doc2bow制作语料库
corpus = [dictionary.doc2bow(doc) for doc in all_doc_list]
#测试文本也转换为二元组的向量
doc_test_vec = dictionary.doc2bow(doc_test_list)
#使用TF-IDF模型对语料库建模
tfidf = models.TfidfModel(corpus)
#获取测试文本中,每个词的TF-IDF值
tfidf[doc_test_vec]
#对每个目标文本,分析测试文本的相似度
index = similarities.SparseMatrixSimilarity(tfidf[corpus], num_features=len(dictionary.keys()))
sim = index[tfidf[doc_test_vec]]
#根据相似度排序
result=sorted(enumerate(sim), key=lambda item:-item[1])
print('文本相似度结果显示,测试文本与doc0相似度最高,之后是doc1')
print('相似度数据为:',result)
运行结果为:(元组中前面是序号,后面是相似度结果)

结束语
额简单文本处理就到此结束了,代码还有许多地方可以优化的,但是由于能力有限+没时间(lan),我就没优化了,希望有大佬可以优化出来分享 ^ _ ^ .
对python感兴趣的小伙伴可以与我互关一下,有机会交流交流.
感觉有帮助的话记得给可怜,无助,弱小的博主点个赞噢!