在 torch.reshape() 函数是对数据类型张量tensor 进行 形状shape 的改变,因此我们首先得了解机器学习里最基本的数据结构 tensor(即张量)。
1. tensor是什么?
学习参考博客:
张量的维度(秩):Rank/Order:
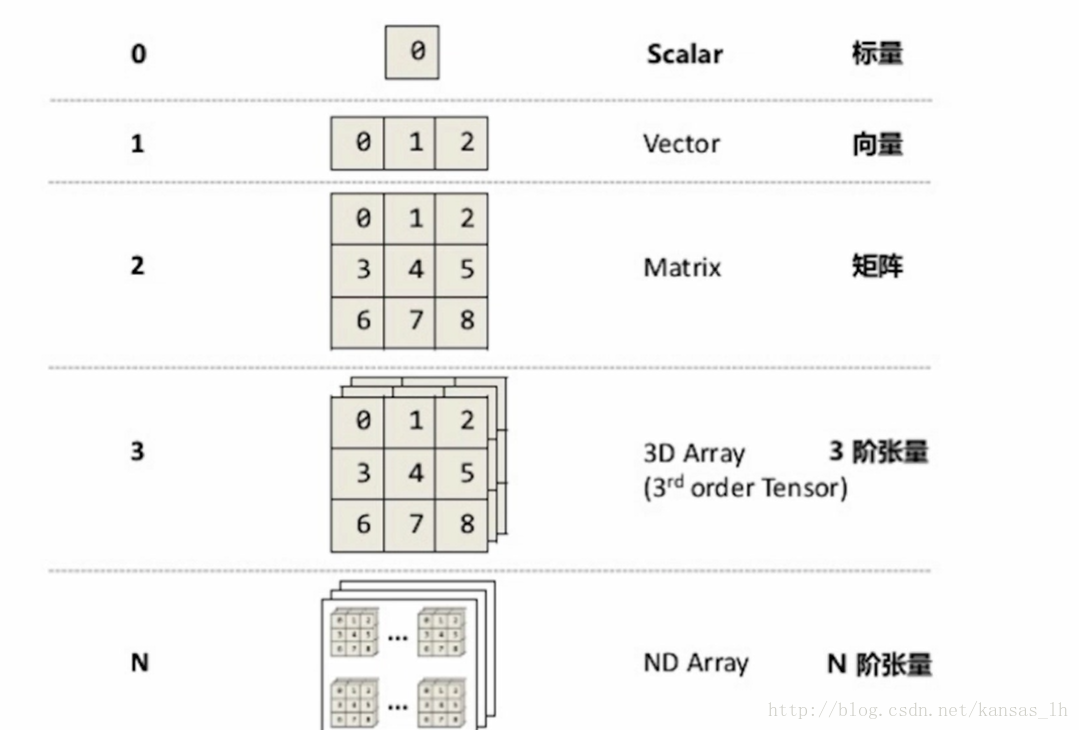
Rank为0、1、2时分别称为标量、向量和矩阵,Rank为3时是3阶张量,Rank大于3时是N阶张量。这些标量、向量、矩阵和张量里每一个元素被称为tensor element(张量的元素),且同一个张量里元素的类型是保持一样的。
0. scalar 标量 0D张量
仅包含一个数字的张量叫作标量(scalar,也叫标量张量、零维张量、0D 张量)。在 Numpy中,一个 float32 或 float64 的数字就是一个标量张量(或标量数组)。你可以用 ndim 属性来查看一个 Numpy 张量的轴的个数。标量张量有 0 个轴(ndim == 0)。张量轴的个数也叫作阶(rank)。下面是一个 Numpy 标量。
1. vector 向量 1D张量
数字组成的数组叫作向量(vector)或一维张量(1D 张量)。一维张量只有一个轴。下面是一个 Numpy 向量。
2. matrix 矩阵 2D张量
\>>> x = np.array([[5, 78, 2, 34, 0],
[6, 79, 3, 35, 1],
[7, 80, 4, 36, 2]])
\>>> x.ndim
2
第一个轴上的元素叫作行(row),第二个轴上的元素叫作列(column)。在上面的例子中,[5, 78, 2, 34, 0] 是 x 的第一行,[5, 6, 7] 是第一列。
1.1 tensor的关键属性
· 轴的个数(阶)。例如,3D 张量有 3 个轴,矩阵有 2 个轴。这在 Numpy 等 Python 库中也叫张量的 ndim。
· 形状。这是一个整数元组,表示张量沿每个轴的维度大小(元素个数)。例如,前面矩阵示例的形状为 (3, 5),3D 张量示例的形状为 (3, 3, 5)。向量的形状只包含一个元素,比如 (5,),而标量的形状为空,即 ()。
· 数据类型(在 Python 库中通常叫作 dtype)。这是张量中所包含数据的类型。
而在深度学习里面,张量的第一个轴(0 轴,因为索引从 0 开始)都是样本轴(samples axis,有时也叫样本维度)。
对于这种批量张量,第一个轴(0 轴)叫作批量轴(batch axis)或批量维度(batch dimension)。(看下面的现实世界的数据张量你就懂了,在一些函数里面比如conv2d,张量的第一个轴叫做batch_size)
1.2 现实世界的数据张量
- 向量数据:2D 张量,shape 为 (samples, features)。
向量数据
这是最常见的数据。对于这种数据集,每个数据点都被编码为一个向量,因此一个数据批量就被编码为 2D 张量(即向量组成的数组),其中第一个轴是样本轴,第二个轴是特征轴。
人口统计数据集,其中包括每个人的年龄、邮编和收入。每个人可以表示为包含 3 个值的向量,而整个数据集包含 100 000 个人,因此可以存储在形状为 (100000, 3) 的 2D张量中。

文本文档数据集,我们将每个文档表示为每个单词在其中出现的次数(字典中包含20 000 个常见单词)。每个文档可以被编码为包含 20 000 个值的向量(每个值对应于字典中每个单词的出现次数),整个数据集包含 500 个文档,因此可以存储在形状为(500, 20000) 的张量中。
- 时间序列数据或序列数据:3D 张量,形状 shape 为 (samples, timesteps, features)。
时间序列数据或序列数据
当时间(或序列顺序)对于数据很重要时,应该将数据存储在带有时间轴的 3D 张量中。
每个样本可以被编码为一个向量序列(即 2D 张量),因此一个数据批量就被编码为一个 3D 张量。
股票价格数据集。每一分钟,我们将股票的当前价格、前一分钟的最高价格和前一分钟的最低价格保存下来。因此每分钟被编码为一个 3D 向量,整个交易日被编码为一个形状为 (390, 3) 的 2D 张量(一个交易日有 390 分钟),而 250 天的数据则可以保存在一个形状为 (250, 390, 3) 的 3D 张量中。这里每个样本是一天的股票数据。

推文数据集。我们将每条推文编码为 280 个字符组成的序列,而每个字符又来自于 128个字符组成的字母表。在这种情况下,每个字符可以被编码为大小为 128 的二进制向量(只有在该字符对应的索引位置取值为 1,其他元素都为 0)。那么每条推文可以被编码为一个形状为 (280, 128) 的 2D 张量,而包含 100 万条推文的数据集则可以存储在一个形状为 (1000000, 280, 128) 的张量中。
后面的以此类推,只不过容器的元素越来越复杂而已。
- 图像:4D 张量,形状为 (samples, height, width, channels) 或 (samples, channels,height, width)。
图像数据
图像通常具有三个维度:高度、宽度和颜色深度
虽然灰度图像(比如 MNIST 数字图像)只有一个颜色通道,因此可以保存在 2D 张量中,但按照惯例,图像张量始终都是 3D 张量,灰度图像的彩色通道只有一维。因此,如果图像大小为 256×256,那么 128 张灰度图像组成的批量可以保存在一个形状为 (128, 256, 256, 1) 的张量中,而 128 张彩色图像组成的批量则可以保存在一个形状为 (128, 256, 256, 3) 的张量中。
图像张量的形状有两种约定:通道在后(channels-last)的约定(在 TensorFlow 中使用)和通道在前(channels-first)的约定(在 Theano 中使用)。Google 的 TensorFlow 机器学习框架将颜色深度轴放在最后:(samples, height, width, color_depth)。与此相反,Theano将图像深度轴放在批量轴之后:(samples, color_depth, height, width)。如果采用 Theano 约定,前面的两个例子将变成 (128, 1, 256, 256) 和 (128, 3, 256, 256)。Keras 框架同时支持这两种格式。
- 视频:5D 张量,形状为 (samples, frames, height, width, channels) 或 (samples, frames, channels, height, width)。
视频数据
视频数据是现实生活中需要用到 5D 张量的少数数据类型之一。视频可以看作一系列帧,每一帧都是一张彩色图像。由于每一帧都可以保存在一个形状为 (height, width, color_depth) 的 3D 张量中,因此一系列帧可以保存在一个形状为 (frames, height, width, color_depth) 的 4D 张量中,而不同视频组成的批量则可以保存在一个 5D 张量中,其形状为**(samples, frames, height, width, color_depth)**。
举个例子,一个以每秒 4 帧采样的 60 秒 YouTube 视频片段,视频尺寸为 144×256,这个视频共有 240 帧。4 个这样的视频片段组成的批量将保存在形状为 (4, 240, 144, 256, 3)的张量中。总共有 106 168 320 个值!如果张量的数据类型(dtype)是 float32,每个值都是32 位,那么这个张量共有 405MB。好大!你在现实生活中遇到的视频要小得多,因为它们不以float32 格式存储,而且通常被大大压缩,比如 MPEG 格式。
2、那么 reshape 如何使用?
首先看一下官方给的解释

Returns a tensor with the same data and number of elements as input(返回与输入具有相同数据和元素数量的张量) but with the specified shape(但是具有指定形状). When possible, the returned tensor will be a view of input(如果可能,返回的张量将是输入的视图,也就是说原本的tensor并没有被改变,如果想要改变那么就将改变的tensor赋值给原本的就行,即:tensor_temp = torch.reshape(tensor_temp,xxxx)). Otherwise, it will be a copy. Contiguous inputs and inputs with compatible strides can be reshaped without copying, but you should not depend on the copying vs. viewing behavior.
返回一个张量,内容和原来的张量相同,但是具有不同形状.
并且尽可能返回视图,否则才会返回拷贝,
因此,需要注意内存共享问题.
传入的参数可以有一个-1,
表示其具体值由其他维度信息和元素总个数推断出来.
torch.reshape() 需要两个参数,一个是待被改变的张量tensor,一个是想要改变的形状。
而这个想改变的形状可能与我们认知的有一定的区别(不过在有了现实世界的数据张量解释,应该知道张量可以简单表示为样本容量和样本数据类型,3D张量存储三维数据,2D张量存储二维数据等等等),这里传入的是一个tuple数剧类型。
举一个使用场景吧:
如果接触过卷积神经网络,应该对下面这个函数并不陌生。
大部分参数咱们可以使用默认的,我们想下面这个动图:两个矩阵的卷积(或许不准确)
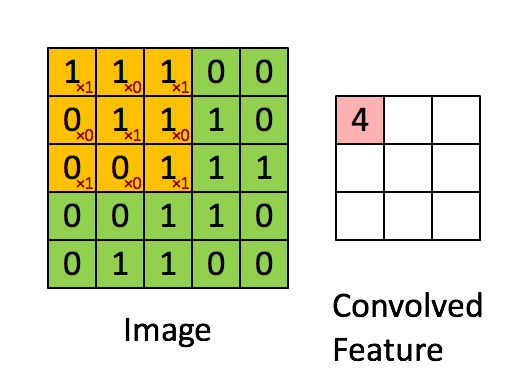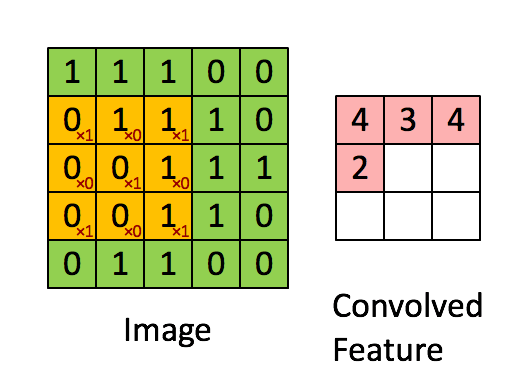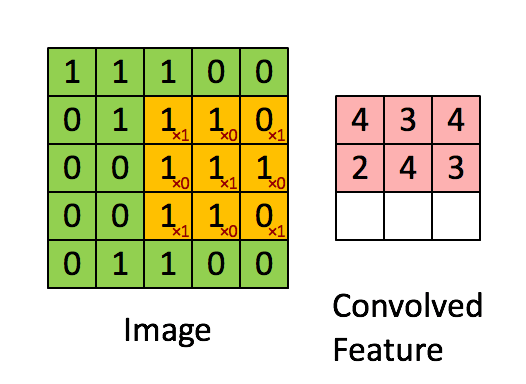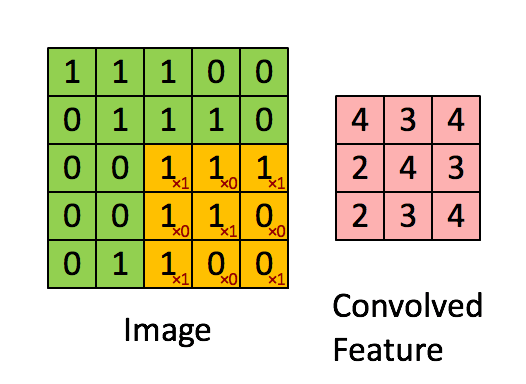

但是参数是一个4D张量,
![]()
这里minibatch和in_channels(具体内容可以看这篇博客:CNN卷积核与通道讲解_奥卡姆的剃刀的博客-CSDN博客_卷积核和通道)
咱暂时就不去深究了,我们可以把一个这样的矩阵,变成一个4D张量。
[[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]]
那么就可以使用reshape函数
input = torch.reshape(input,[1,1,5,5])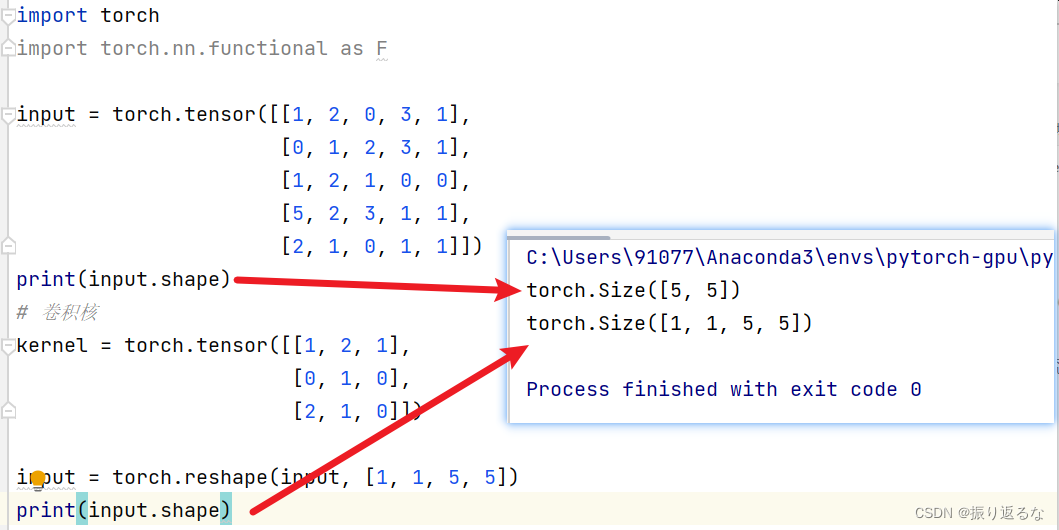
如果print的话你也会看出其中的差距,毕竟一个是2D张量(所以会以一行向量为容器元素),一个是4D张量(以3维为容器元素)。
最后的代码:
# TORCH.NN.FUNCTIONAL.CONV2D
# torch.nn.functional.conv2d(input, weight, bias=None, stride=1, padding=0, dilation=1, groups=1) → Tensor
# 名词解释:
# input: input tensor of shape (minibatch,in_channels,iH,iW) minibatch也就是最小的批量大小,
# in_channels为卷积的图片来源个数
# out_channels 为卷积核的个数
# iH 和 iW 是图片高度和宽度
# weight filters of shape (out_channels,in_channels/groups,kH,kW) 卷积大小,第二个参数的groups一般为1
# stride 步幅默认为1
# padding 在每一边都填充 默认为0
import torch
import torch.nn.functional as F
input = torch.tensor([[1,2,0,3,1],
[0,1,2,3,1],
[1,2,1,0,0],
[5,2,3,1,1],
[2,1,0,1,1]])
# 卷积核
kernel = torch.tensor([[1,2,1],
[0,1,0],
[2,1,0]])
input = torch.reshape(input,[1,1,5,5])
kernel = torch.reshape(kernel,[1,1,3,3])
#为什么要转变shape,因为functional的tensor格式为(x,x,x,x)
print(input.shape)
print(kernel.shape)
# 结果:
# torch.Size([5, 5])
# torch.Size([3, 3])
# 经过torch.reshape之后结果为:
# torch.Size([1, 1, 5, 5])
# torch.Size([1, 1, 3, 3])
output = F.conv2d(input,kernel,stride=1)
print(output)
# tensor([[[[10, 12, 12],
# [18, 16, 16],
# [13, 9, 3]]]])
output2 = F.conv2d(input,kernel,stride=2)
print(output2)
# tensor([[[[10, 12],
# [13, 3]]]])
output3 = F.conv2d(input,kernel,stride=1,padding=1)
print(output3)
# tensor([[[[ 1, 3, 4, 10, 8],
# [ 5, 10, 12, 12, 6],
# [ 7, 18, 16, 16, 8],
# [11, 13, 9, 3, 4],
# [14, 13, 9, 7, 4]]]])---------------关于batchsize和channels的一些拙见----------------------------------------------------------
torch.reshape()是如何操作的
问题背景:假设当我们的dataloader的batch_size设置为64。并且经过卷积(out_channels=6)之后,我们需要使用tensorboard可视化,而彩色图片的writer.add.images(output)的彩色图片是in_channels=3的。
那么则需要对卷积后的图片进行reshape
Torch.size(64,6,30,30)---->torch.size(-1,3,30,30)
-1的意思为最后自动计算其batch_size
输出通道就是有多少个卷积核,同一个卷积核得到的数据叠成一个通道,但由于减少了三个通道,从而每一个通道的数量增加。
因而结果为torch.size(128,3,30,30)
output = torch.reshape(output,(-1,3,30,30))#torch.size(64,6,30,30)--->(xxx,3,30,30)
print(output.shape)#reshape结果:torch.Size([128, 3, 30, 30])
最后一组是原本dataloader设置为
drop_last=False