上一节我们介绍了LeNet-5和AlexNet网络,本节我们将介绍VGG-Nets、Network-In-Network和深度残差网络(residual network)。
VGG-Nets网络模型
VGG-Nets 由英国牛津大学著名研究组 VGG(Visual Geometry Group)提出,是2014 年 ImageNet 竞赛定位任务 (localization task)第一名和分类任务第二名做法中的基础网络。由于 VGG-Nets 具备良好的泛化性能,其在ImageNet 数据集上的预训练模型 (pre-trained model) 被广泛应用于除最常用的特征抽取 (feature extractor) 外的诸多问题:如物体候选框 (objectproposal) 生成、细粒度图像定位与检索 (fn-grained object localizationand image retrieval)、图像协同定位(co-localization) 等。以 VGG-Nets 中的代表 VGG-16 为例,下表中列出了其每层具体参数信息可以发现,相比 Alex-Net,VGG-Nets 中普遍使用了小卷积核以及“保持输入大小”等技巧,为的是在增加网络深度 (即网络复杂度)时确保各层输入大小随深度增加而不极具减小。同时,网络卷积层的通道数 (channel)也是从 3 → 64 → 128 → 256 → 512 3\rightarrow64\rightarrow128\rightarrow256\rightarrow512 3→64→128→256→512逐渐增加。
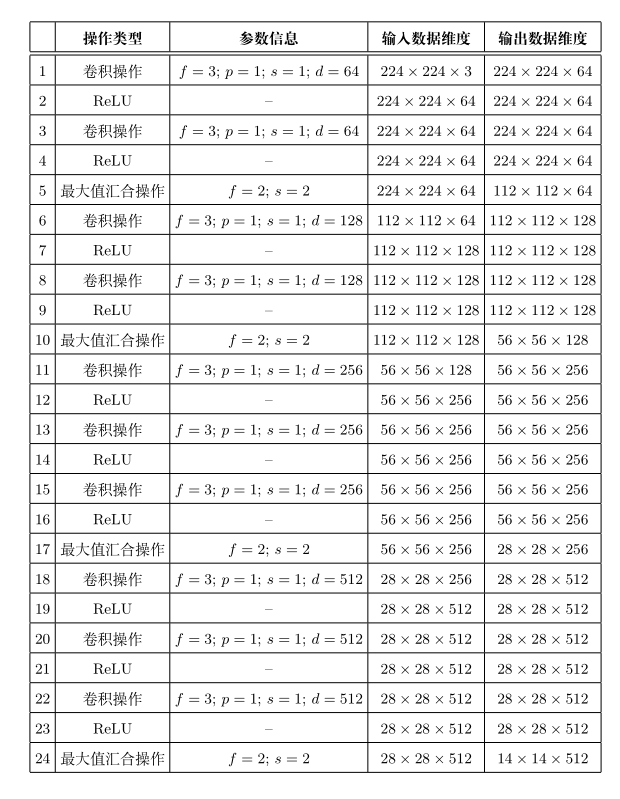
其中,“f”为卷积核/汇合核大小,“s”为
步长,“d”为该层卷积核个数(通道数),“p”为填充参数,“C”为分类任务类
别数(在 ImageNet数据集上为 1000)。(注:各层输出数据维度可能因所使用深度学习开发工具的不同而略有差异。)
论文地址:
https://arxiv.org/abs/1409.1556
Network-In-Network
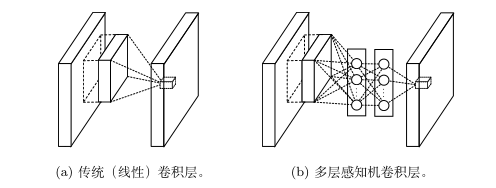
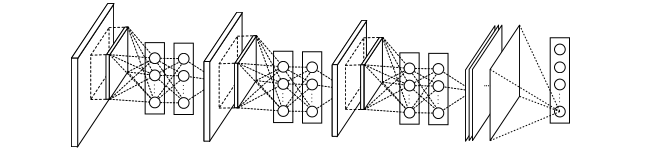
Network-In-Network(NIN) 是由新加坡国立大学 LV 实验室提出的异于传统卷积神经网络的一类经典网络模型,它与其他卷积神经网络的最大差异是用多层感知机**(多层全连接层和非线性函数的组合)** 替代了先前卷积网络中简单的线性卷积层。我们知道线性卷积层的复杂度有限,利用线性卷积进行层间映射也只能将上层特征或输入“简单”的线性组合形成下层特征。而 NIN 采用了复杂度更高的多层感知机作为层间映射形式,一方面提供了网络层间映射的一种新可能;另一方面增加了网络卷积层的非线性能力,使得上层特征可有更多复杂性与可能性的映射到下层,这样的想法也被后期出现的残差网络和Inception等网络模型所借鉴。
同时,NIN 网络模型的另一个重大突破是摒弃了全连接层作为分类层的传统,转而改用全局汇合操作 (global average pooling),如图所示。NIN 最后一层共 C 张特征图 (feature map) 对应分类任务的C个类别。全局汇合操作分别作用于每张特征图,最后以汇合结果映射到样本真实标记。可以发现,在这样的标记映射关系下,C 张特征图上的响应将很自然的分别对应到 C 个不同的样本类别,这也是相对先前卷积网络来讲,NIN 在模型可解释性上的一个优势。
论文地址:
https://arxiv.org/pdf/1312.4400.pdf
残差网络模型
理论和实验已经表明,神经网络的深度 (depth) 和宽度 (width) 是表征网络复杂度的两个核心因素,不过深度相比宽度在增加网络的复杂性方面更加有效这也正是为何 VGG 网络想方设法增加网络深度的一个原因。然而,随着深度的增加,训练会变得愈加困难。这主要因为在基于随机梯度下降的网络训练过程中,误差信号的多层反向传播非常容易引发梯度“弥散”(梯度过小会使回传的训练误差极其微弱)或者“爆炸”(梯度过大会导致模型训练出现“NaN”现象。目前,一些特殊的权重初始化策略 ,以及批规范化 (batchnormalization)策略等方法使这个问题得到极大的改善–网络可以正常训练了!但是,实际情形仍不容乐观。当深度网络收敛时,另外的问题又随之而来:随着继续增加网络的深度,训练数据的训练误差没有降低反而升高,这种现象如图所示。这一观察与直觉极其不符,因为如果一个浅层神经网络可以被训练优化求解到某一个很好的解,那么它对应的深层网络至少也可以而不是更差。这一现象在一段时间内困扰着更深层卷积神经网络的设计、训练和应用。

残差网络(Residual Network,ResNet)是通过给非线性的卷积层增加直
连边的方式来提高信息的传播效率。
假设在一个深度网络中,我们期望一个非线性单元(可以为一层或多层的卷积层) f ( x , θ ) f(x,\theta) f(x,θ)去逼近一个目标函数为 h ( x ) h(x) h(x)。如果将目标函数拆分成两部分:恒等函数(Identity Function) x x x和残差函数(Residue Function) h ( x ) − x h(x) − x h(x)−x。
h ( x ) = x + ( h ( x ) − x ) . h(\mathbf{x})=x+\left(h(\mathbf{x})-x\right). h(x)=x+(h(x)−x).
根据通用近似定理,一个由神经网络构成的非线性单元有足够的能力来近似逼近原始目标函数或残差函数,但实际中后者更容易学习。因此,原来的优化问题可以转换为:让非线性单元 f ( x , θ ) f(x,\theta) f(x,θ)去近似残差函数 h ( x ) − x h(x)−x h(x)−x,并用 f ( x , θ ) + x f(x,\theta) + x f(x,θ)+x去逼近 h ( x ) h(x) h(x)。
如图给出了一个典型的残差单元示例。

残差单元由多个级联的(等长)卷积层和一个跨层的直连边组成,再经过 ReLU激活后得到输出。
残差网络就是将很多个残差单元串联起来构成的一个非常深的网络.
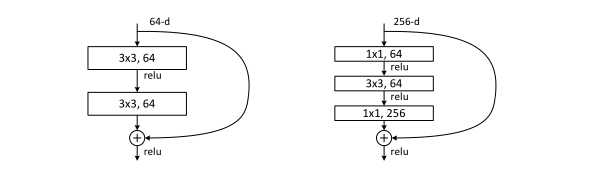
“瓶颈残差模块”可大量减少计算代价。
发表残差网络的论文也获得了计算机视觉与模式识别领域国际顶级会议 CVPR 2016的最佳论文奖。残差网络模型的出现不仅备受学界业界瞩目,同时也拓宽了卷积神经网络研究的道路。
此外,将残差网络与传统的 VGG 网络模型对比可以发现,若无近路连接,残差网络实际上就是更深的 VGG 网络,只不过残差网络以全局平均汇合层(globalaverage pooling layer) 替代了 VGG 网络结构中的全连接层,一方面使得参数大大减少,另一方面减少了过拟合风险。同时需指出这样“利用全局平均汇合操作替代全连接层”的设计理念早在 2015 年提出的GoogLeNet中就已经被使用。
论文地址:
https://arxiv.org/pdf/1512.03385.pdf
下载1:人工资料大礼包
在「阿远学长」公众号后台回复:【1】
即可领取一份人工资料大礼包
包含机器学习、深度学习书籍pdf
各大人工智能项目实战、大厂面试宝典等
下载2:人工智能实战项目
在「阿远」公众号菜单栏点击:【实战项目】
即可手把手复现人工智能实战项目