爬虫基础入门
1 概念
所谓爬虫其实就是我们通过代码向服务器发起请求,然后解析服务器响应给我们的数据。例如:将服务器响应给我们的html数据,解析出来,获取豆瓣评分前250的电影名字。
2 实战
此处通过python演示。
首先:安装python。
官网地址:https://www.python.org/
- 在终端执行以下命令,安装请求包
# pip 是 Python 中的标准库管理器
pip install requests
- 安装bs4(Beatiful Soup)
使用Beatiful Soup解析html内容
pip install bs4
- 代码编写
- 引入requests包
- 在请求服务器时带上headers,否则有些服务器会做反爬虫限制,如果我们的headers中没有伪装的浏览器信息,有些服务器是拒绝访问会报415
- headers中是键值对K-V形式, 我们可以抓包直接从浏览器真正的请求中获取一个headers
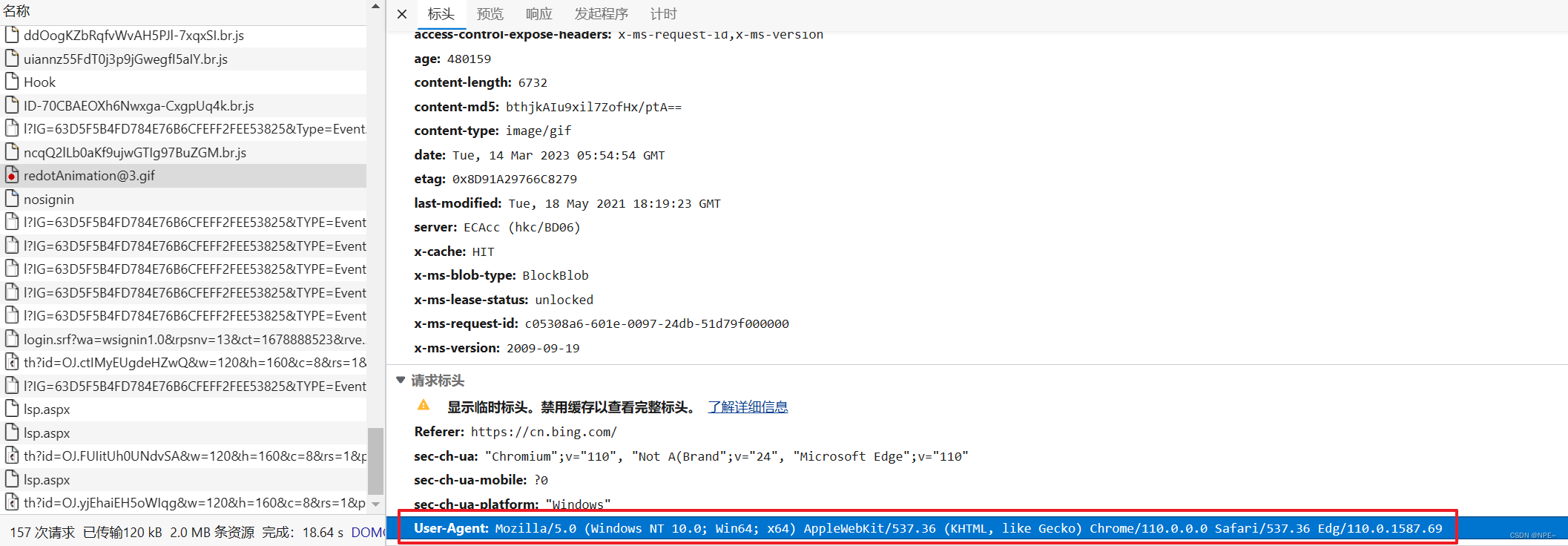
- 尝试请求豆瓣服务器,查看返回的html
import requests
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.69"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
print(response.text)
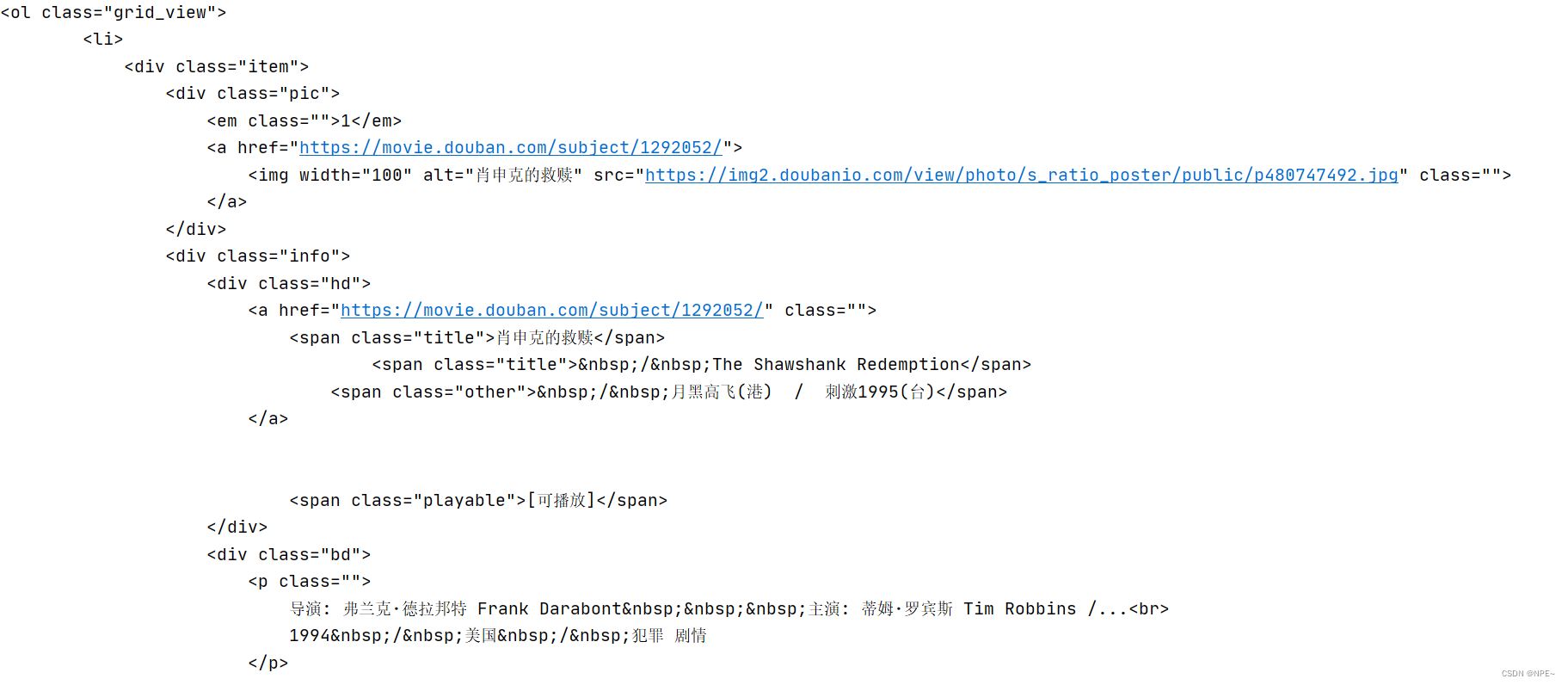
- 对获取的html进行解析
我们可以发现电影名字是在span标签下,且class为title

- 通过bs4获取标签元素
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.69"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
all_titles = soup.findAll("span", attrs={
"class":"title"})
print(all_titles)

此时我们发现解析出的数据带有html的标签,显然不符合我们的预期,我们只想要请求到电影名字,此时可以通过title.string方法实现,同时返回的数据是一个列表,因此我们需要遍历列表
import requests
from bs4 import BeautifulSoup
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.69"
}
response = requests.get("https://movie.douban.com/top250", headers=headers)
html = response.text
soup = BeautifulSoup(html, "html.parser")
all_titles = soup.findAll("span", attrs={
"class":"title"})
for title in all_titles:
title_string = title.string
print(title_string)
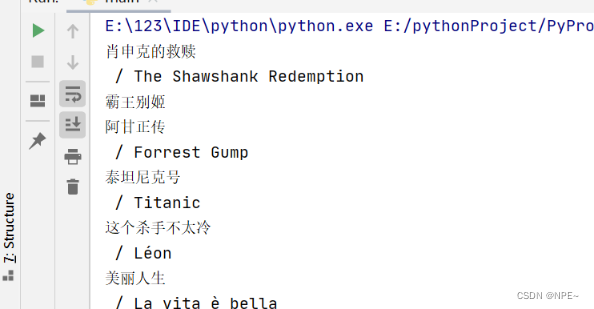
此时可以看到,返回的数据中不仅有中文名还有英文名字,那么我们只想要获取中文名字该怎么做呢?
- 只需要通过if判断
/即可,因为可以看到每个英文标题前都有一个/
for title in all_titles:
title_string = title.string
if "/" not in title_string:
print(title_string)
- 现在已经可以返回正常的数据了,但是只有25条数据,因为我们服务器通常会做分页,所以我们需要循环访问,同时,在url上动态拼接起始页码
# 由于豆瓣进行了分页,因此我们需要循环请求
for start_num in range(0, 250, 25):
# 向豆瓣的服务器发起请求(请求获取评分前250的)
# f 是format字符串,用{start_num}格式化占位
response = requests.get(f"https://movie.douban.com/top250?start={
start_num}", headers=headers)
html = response.text
# 构造html解析器
soup = BeautifulSoup(html, "html.parser")
all_titles = soup.findAll("span", attrs={
"class":"title"})
for title in all_titles:
title_string = title.string
if "/" not in title_string:
print(title_string)
全部代码:
import requests
from bs4 import BeautifulSoup
# 伪造请求头
headers = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.69"
}
# 由于豆瓣进行了分页,因此我们需要循环请求
for start_num in range(0, 250, 25):
# 向豆瓣的服务器发起请求(请求获取评分前250的)
response = requests.get(f"https://movie.douban.com/top250?start={
start_num}", headers=headers)
html = response.text
# 构造html解析器
soup = BeautifulSoup(html, "html.parser")
all_titles = soup.findAll("span", attrs={
"class":"title"})
for title in all_titles:
title_string = title.string
if "/" not in title_string:
print(title_string)
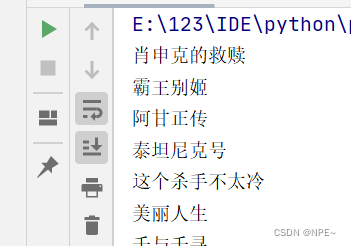
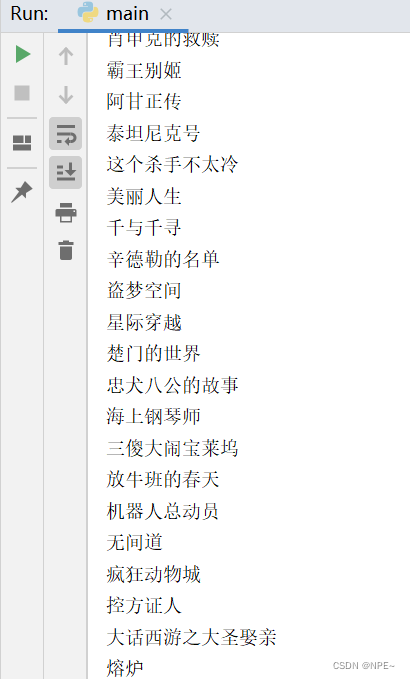
运行脚本,查看结果:
总结:
网络爬虫不仅要对html结构了解,而且要对浏览器请求等很熟悉。同时注意:切勿爬取违法或机密数据,本教程仅用于教学,如有违法行为,后果自负。