爬取的网址:https://www.23hh.com/book/0/189/

需求:获取小说的章节目录及其对应的章节内容
需要的库:requests、BeautifulSoup和re。利用requests库发送浏览器请求,BeautifulSoup和re库对获取到的数据进行分析、提取。
分别使用pip install requests和pip install BeautifulSoup4安装
对网页源码进行分析:

1、创建testcraw包
2、创建craw_site.py文件用于获取章节目录及其链接
import requests
from bs4 import BeautifulSoup
import re
def getSoup(website):
try:
res = requests.get(url=website) # 发送请求
res.raise_for_status() # 检测返回状态码是否正常
res.encoding = res.apparent_encoding # 避免中文乱码
content = res.text
soup = BeautifulSoup(content, 'html.parser')
return soup # 返回BeautifulSoup对象
except requests.HTTPError as e:
return e
def result(website):
chapter, siteLst = [], []
try:
soup = getSoup(website)
except requests.HTTPError as e:
return e
else:
for i in soup.find_all('dd'): # 利用BeautifulSoup类的find_all方法对数据进行筛选
for j in i.find_all('a'):
k = j.string
isExisted = re.match('[\u4e00-\u9fa5]+章', k) # 利用正则表达式筛选
if isExisted is not None:
chapter.append(j.string)
siteLst.append(website + j.attrs['href'][12:]) # 提取小说各个章节得我连接
lst = list(zip(chapter, siteLst))
for i in range(12):
del lst[0]
return lst # 返回章节目录及其连接
3、创建mysql_helper.py文件用于保存数据
import pymysql
class MysqlTool(object):
def getConn(self):
conn = None
try:
conn = pymysql.connect(host='localhost',
user='root',
password='5180',
port=3306,
db='fictions')
except Exception as e:
print('\033[31m{}\033[0m'.format(e))
return conn
def closeConn(self, conn):
try:
if conn is not None:
conn.commit()
conn.close()
except Exception as e:
print('\033[31m{}\033[0m'.format(e))
def getCursor(self, conn):
cur = None
try:
if conn is not None:
cur = conn.cursor()
except Exception as e:
print('\033[31m{}\033[0m'.format(e))
return cur
def closeCursor(self, cur):
try:
if cur is not None:
cur.close()
except Exception as e:
print('\033[31m{}\033[0m'.format(e))
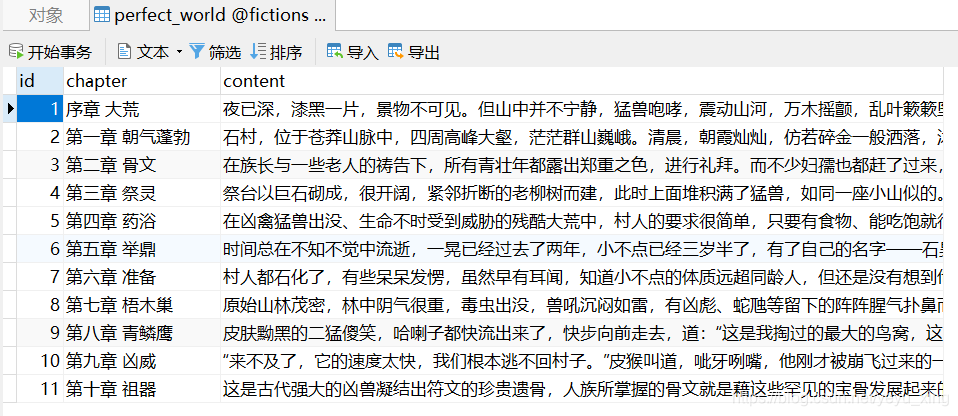
def insert(self, cur, chapter='', content=''):
sql = 'insert into perfect_world(chapter, content) values(%s, %s);'
count = cur.execute(sql, (chapter, content))
if count > 0:
print('{} 抓取成功'.format(chapter))
创建fictions数据库和如下所示的表:
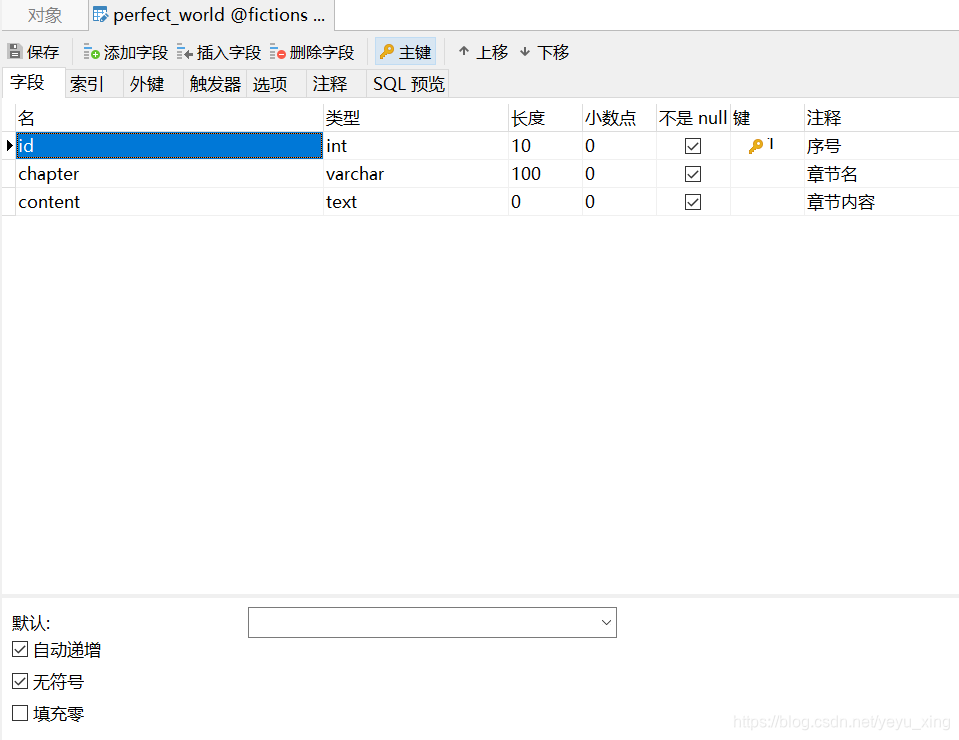
4、创建subpage.py文件用于获取子页的正文内容
import requests
from bs4 import BeautifulSoup
from testcraw.craw_site import result
from testcraw.mysql_helper import MysqlTool
import re
def test(website):
for i in result(website):
chapter, content = i[0], ''
site = i[1]
res = requests.get(url=site, timeout=60)
res.raise_for_status()
res.encoding = res.apparent_encoding
demo = res.text
soup = BeautifulSoup(demo, 'html.parser')
for i in soup.find_all(attrs={
'id': 'content'}):
for j in i.stripped_strings:
content += (j + '\n')
content = re.sub(pattern='纯文字在线阅读本站域名手机同步阅读请访问', repl='', string=content, count=1)
mt = MysqlTool()
conn = mt.getConn()
cur = mt.getCursor(conn)
mt.insert(cur, chapter, content)
mt.closeCursor(cur)
mt.closeConn(conn)
test('https://www.23hh.com/book/0/189/')
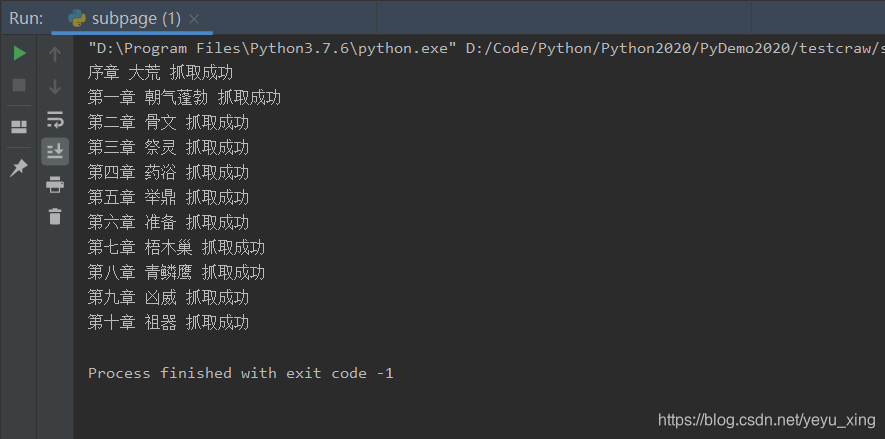
爬取部分内容如下: