渲染流程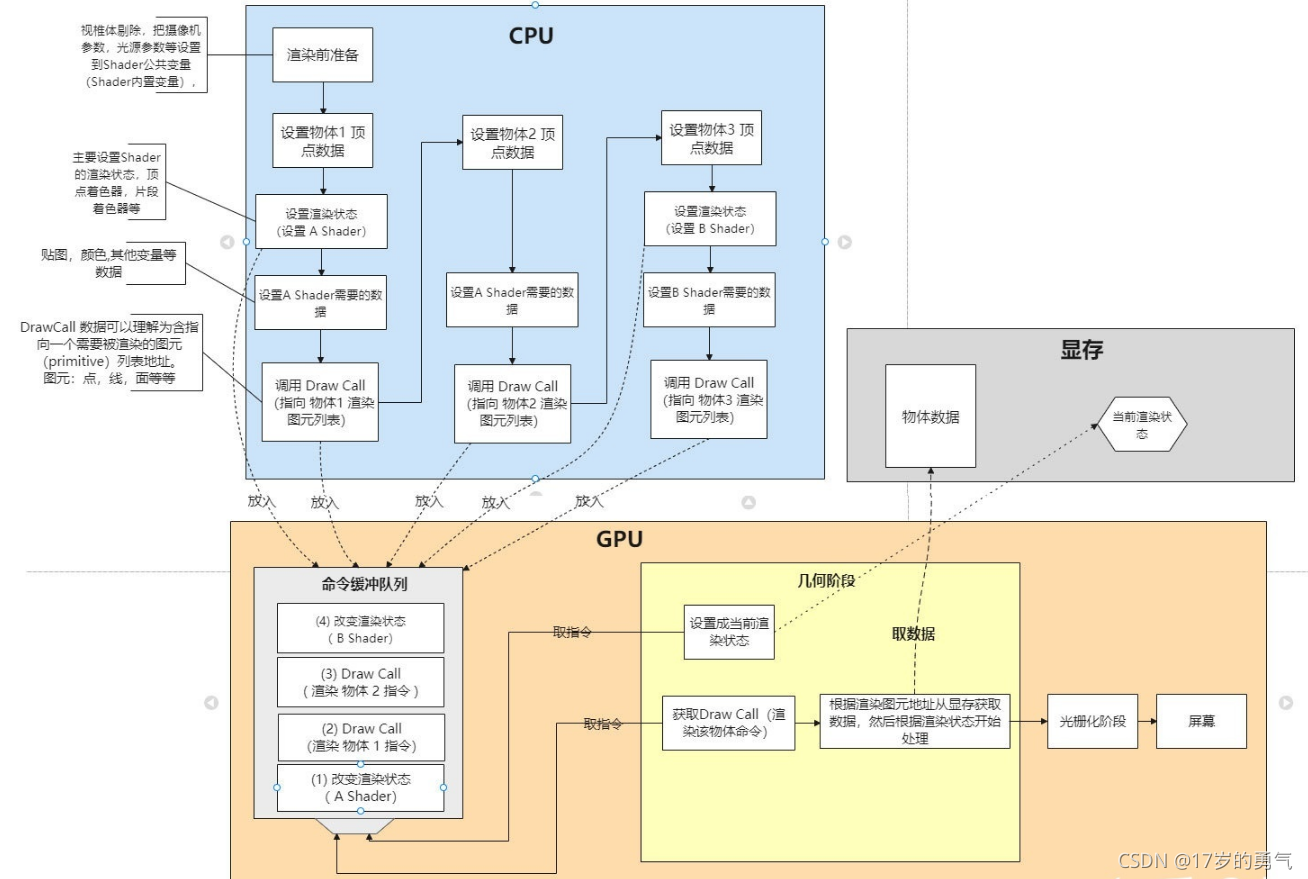
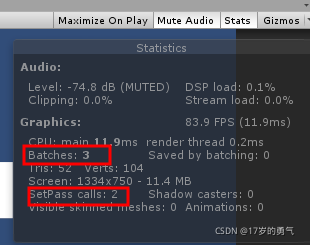
看一下unity几个比较重要的点 drawcall,Batches,SetPass
1.Drawcall:CPU向GPU发送数据绘制图元
DrawCall 只是 Unity 需要推送到 GPU 命令缓冲区的少量字节
大多数情况可能性能消耗不是drawcall的原因 而是设置渲染状态
2.,Batches合批 优化Drawcall
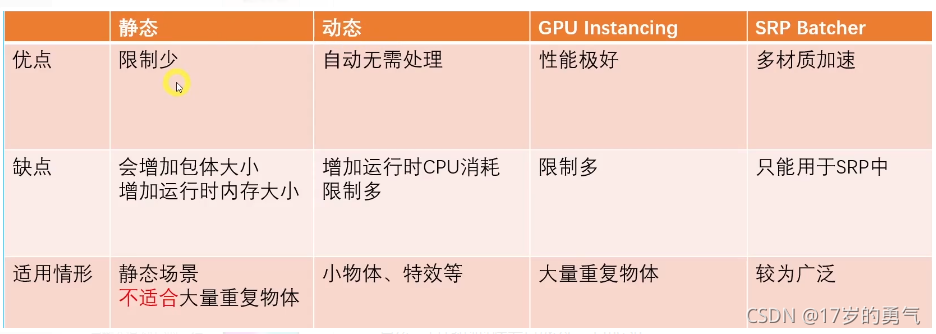
1.静态批处理(优化GPU 增加内存 包体)
用法:标记为 Batching Static 使用相同材质球
算法:打包的时候会合成为一个mesh
优化:setpasscall的数量
缺点:打包后体积增加 运行时内存占用增大
当场景中有相同的mesh的时候 本来在内存中只需要一个mesh
但如果开启 静态批处理这些相同的mesh也会在内存中生成多份 也就不能复用了 并且会生成一个很大的网格数据
2.动态批处理 (优化GPU 消耗CPU)
用法:shader总共 不能超过900个属性(shader使用 顶点位置,法线 可以包含450个顶点shader使用 顶点位置,法线,切线则只能包含 300个顶点)
不包含缩放,材质一样,lightmap指向的位置一样
优化:一次drawcall绘制多个模型 setpasscall的数量
缺点:CPU计算的消耗
合批中断的情况:
使用多Pass
前向渲染路径中 一个对象如果接受多个光照 会附加PASS
3.GPU Instancing (优化CPU)
用法:相同的材质,相同mesh(和静态批处理不一样的) 一次性发送给GPU,即便使用了MaterialPropertyBlock
算法:仅绘制一个 其他物体复制出来
缺点:不支持SkinnedMeshRenderer
合批中断的情况:
缩放为负,常量缓冲区不同设备 上限的大小不一样,只支持一盏实时光 想多光源支持 可以切换到延迟渲染路径
4.SRP Batcher (优化GPU 消耗CPU)
用法:SRP管线才能使用 不同的材质 只要shader变体相同 就可以 可以优化setpasscall的数量
原理:简单点说就是在一个名为 UnityPerMaterial 的 CBUFFER 中声明所有材质属性 这些材质属性是缓存下来了的 就可以使用不同的材质来进行 合批
通用无法优化的情况:
不相邻 中间夹杂着不同的shader(或者shader变体)
通用优先级:
SRP Batcher-》静态合批-》GPU Instancing-》动态合批