在船舶航行状态评估、船舶碰撞概率检测等场景种有着对海面船舶航行轨迹较高的预测需求,准确实时地对航行轨迹进行预测分析有助于评估船舶航行的状态,及时对可能存在的潜在威胁进行发现预警处理,航行轨迹预测本质上来讲就是时间序列建模,在我之前的博文中已经有大量的博文和对应的教程,对于时间序列预测建模有比较详细的介绍。
很多场景下多变量序列预测建模大都是基于深度学习完成的,这个也是因为深度学习模型天然的优势,能够处理高维度的数据,基于机器学习模型本质上来讲也是可以完成这项工作的,只不过会比深度学习更加麻烦,这里主要的目的就是以船舶航行轨迹数据集为基准来开发XGBoost时间序列预测模型。
首先看下数据集:
mmsi,lat,lon,Sog,Cog,timestamp
33,30.430935,121.840168,13.3,218,1530665006
33,30.431335,121.840587,13.2,33,1530665016
33,30.432252,121.84158,13.2,145,1530665036
33,30.432675,121.841973,13.2,30,1530665046
33,30.433992,121.84337,13.2,20,1530665076
33,30.434867,121.844305,13.1,39,1530665096
33,30.435257,121.844728,13.1,43,1530665106
33,30.434867,121.844305,13.1,23,1530665119
33,30.43619,121.845688,13.1,50,1530665126
33,30.437892,121.847477,13.1,53,1530665166
33,30.43838,121.84798,13.1,50,1530665176
33,30.43887,121.848482,13.2,28,1530665187
33,30.44061,121.850253,13.1,50,1530665226
33,30.441017,121.850657,13.1,42,1530665236
33,30.43749,121.84707,13.012,54,1530665238
33,30.44155,121.85121,13.1,117,1530665247
33,30.442865,121.852583,13.1,182,1530665276
33,30.443728,121.853523,13.2,0,1530665296
33,30.44415,121.854003,13.2,200,1530665307
33,30.444593,121.854473,13.2,140,1530665317
33,30.445012,121.854958,13.2,107,1530665327
33,30.44195,121.85162,13.212,275,1530665339
33,30.447153,121.857333,13.2,277,1530665377
33,30.447575,121.857832,13.2,267,1530665387
33,30.447575,121.857832,13.2,276,1530665410
33,30.448822,121.859192,13.2,272,1530665416
33,30.45052,121.861037,13.2,260,1530665456
33,30.451377,121.861993,13.2,274,1530665476
33,30.4519,121.86256,13.2,265,1530665486
33,30.452343,121.863042,13.2,250,1530665497
33,30.452773,121.863522,13.2,291,1530665507
33,30.454465,121.86536,13.1,104,1530665547
33,30.455717,121.866725,13.1,99,1530665576
33,30.456632,121.867703,13.1,92,1530665596可以看到:数据集中给出来了航行过程中记录得到的详细数据,包括:经度和维度还有sog与cog。
首先需要对原始数据集进行解析处理,如下:
with open(data) as f:
data_list = json.load(f)
data_dict = {}
for one_list in data_list:
mmsi, ts, lat, lon, Sog, Cog = one_list
if mmsi in data_dict:
data_dict[mmsi].append([ts, lat, lon, Sog, Cog])
else:
data_dict[mmsi]=[[ts, lat, lon, Sog, Cog]]
X, y = [], []
for one_mmsi in data_dict:
one_data = data_dict[one_mmsi]
one_data = sorted(one_data, key = lambda e:e[0])
one_X, one_y = sliceWindow(one_data, step)
X += one_X
y += one_y
X_train, X_test, y_train, y_test = splitData(X, y, ratio=ratio)
dataset = {}
dataset["X_train"], dataset["y_train"] = X_train, y_train
dataset["X_test"], dataset["y_test"] = X_test, y_test
with open(save_path, "w") as f:
f.write(json.dumps(dataset))处理完成后 ,就得到了随机划分后形成的训练集和测试集。
得到数据集后就可以搭建模型了,核心实现如下:
if not os.path.exists(saveDir):
os.makedirs(saveDir)
X_train,y_train,X_test,y_test = loadDataSet(data=data, label=label)
#模型构建
model = xgb.XGBRegressor(
max_depth=5,
n_estimators=200,
objective="reg:linear",
)
#训练拟合
model.fit(X_train, y_train)
# 预测
res_dict = {}
train_pred = model.predict(X_train)
evs, mae, mse, r2 = calPerformance(y_train, train_pred)
mapev = mape(train_pred, y_train)
rmse = math.sqrt(mse)
train_info = (
"训练集评估指标分析\nRMSE: "
+ str(round(rmse, 4))
+ ", MAPE: "
+ str(round(mapev, 4))
+ ", R2: "
+ str(round(r2, 4))
)
res_dict["train_true"] = y_train
res_dict["train_predict"] = train_pred.tolist()
plt.clf()
plt.figure(figsize=(12,8))
plt.plot(y_train, label="训练集真实值曲线")
plt.plot(train_pred, label="训练集预测值曲线")
plt.legend()
plt.title(train_info)
plt.savefig(saveDir + "train_compare.png")这里以lat为例看下训练集对比拟合曲线如下所示:
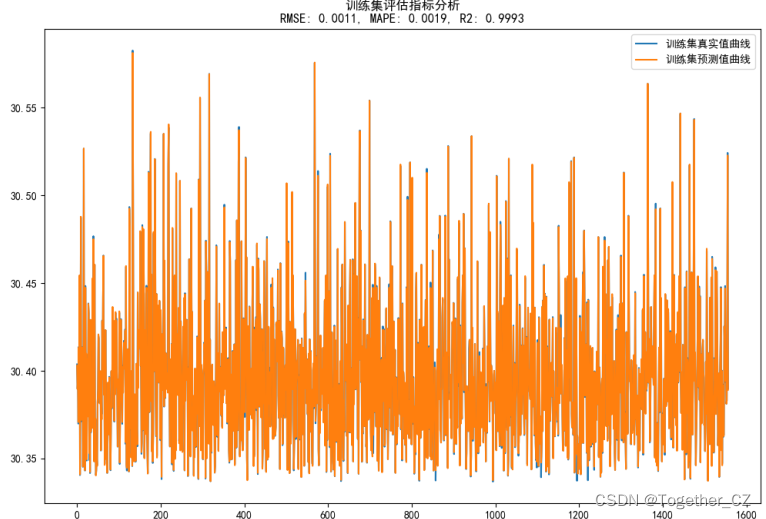
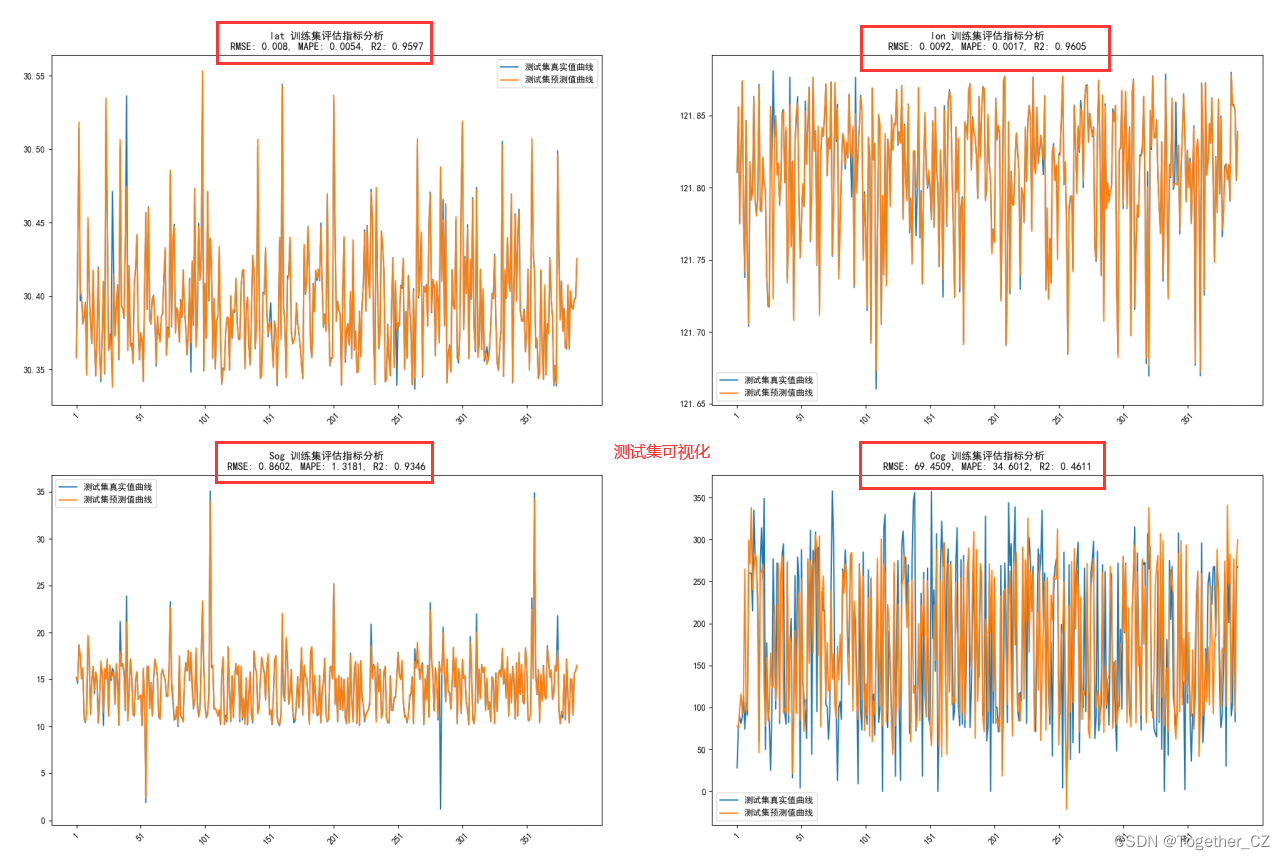
测试集对比拟合曲线如下:
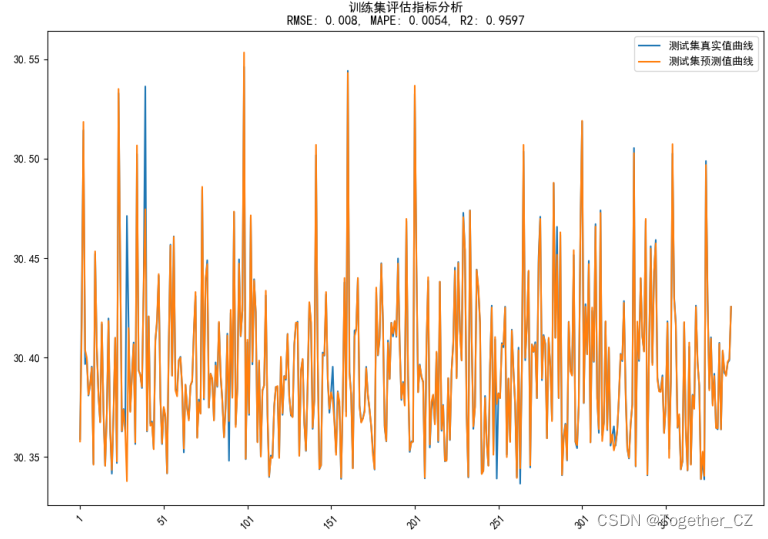
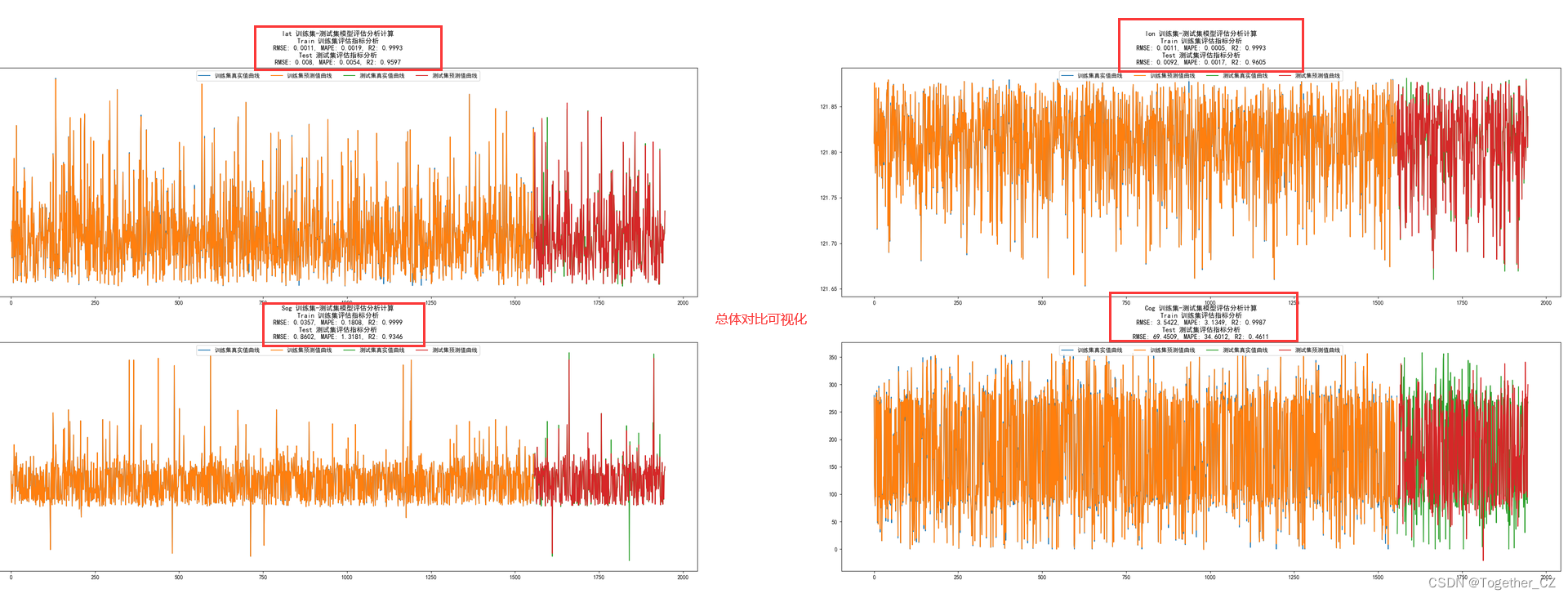
总体对比曲线如下:
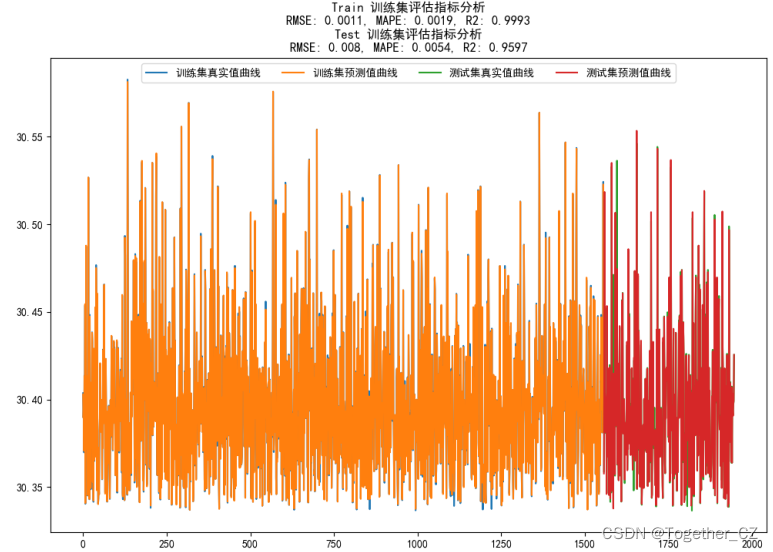
可以看到:模型的拟合效果是很好的了,这里绘制了特征重要性图像:
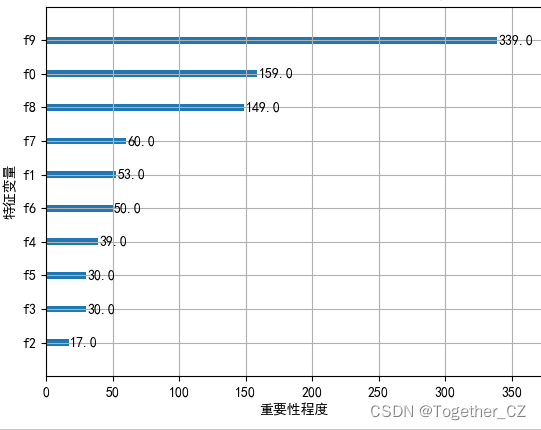
接下来整合多维度的数据集来依次构建模型,核心方法同上,这里就不再重复介绍了,绘图有别于上述实现,这里着重介绍一下,以训练集数据集为例如下:
plt.clf()
plt.figure(figsize=(40,16))
i=1
for one_label in res_dict:
y_true=res_dict[one_label]["train_true"]
y_pred=res_dict[one_label]["train_predict"]
evs, mae, mse, r2 = calPerformance(y_true, y_pred)
mapev = mape(y_pred, y_true)
rmse = math.sqrt(mse)
train_info = one_label+ " 训练集评估指标分析\nRMSE: " + str(round(rmse, 4)) + ", MAPE: " + str(round(mapev, 4)) + ", R2: " + str(round(r2, 4))
plt.subplot(2,2,i)
plt.plot(y_true, label="训练集真实值曲线")
plt.plot(y_pred, label="训练集预测值曲线")
plt.legend()
plt.title(train_info)
i+=1
plt.savefig(saveDir + "train_compare.png")效果如下:
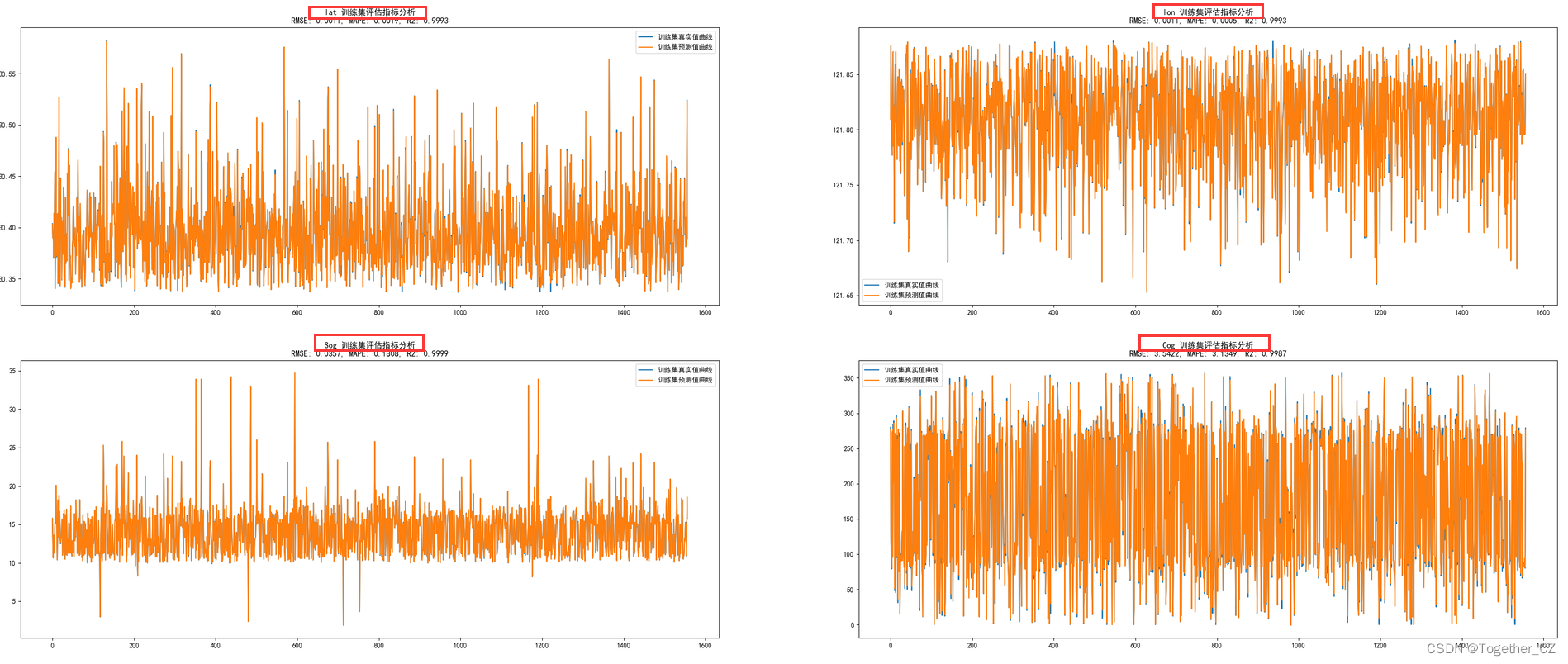
测试集可视化同上,效果如下:
总体对比可视化如下所示:
同样这里也绘制了特征重要性可视化:
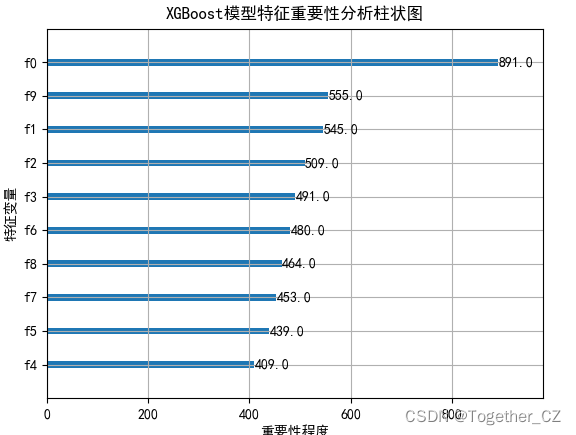
这个跟我们常识还是比较接近的哈。