文章目录
前言
效果如下
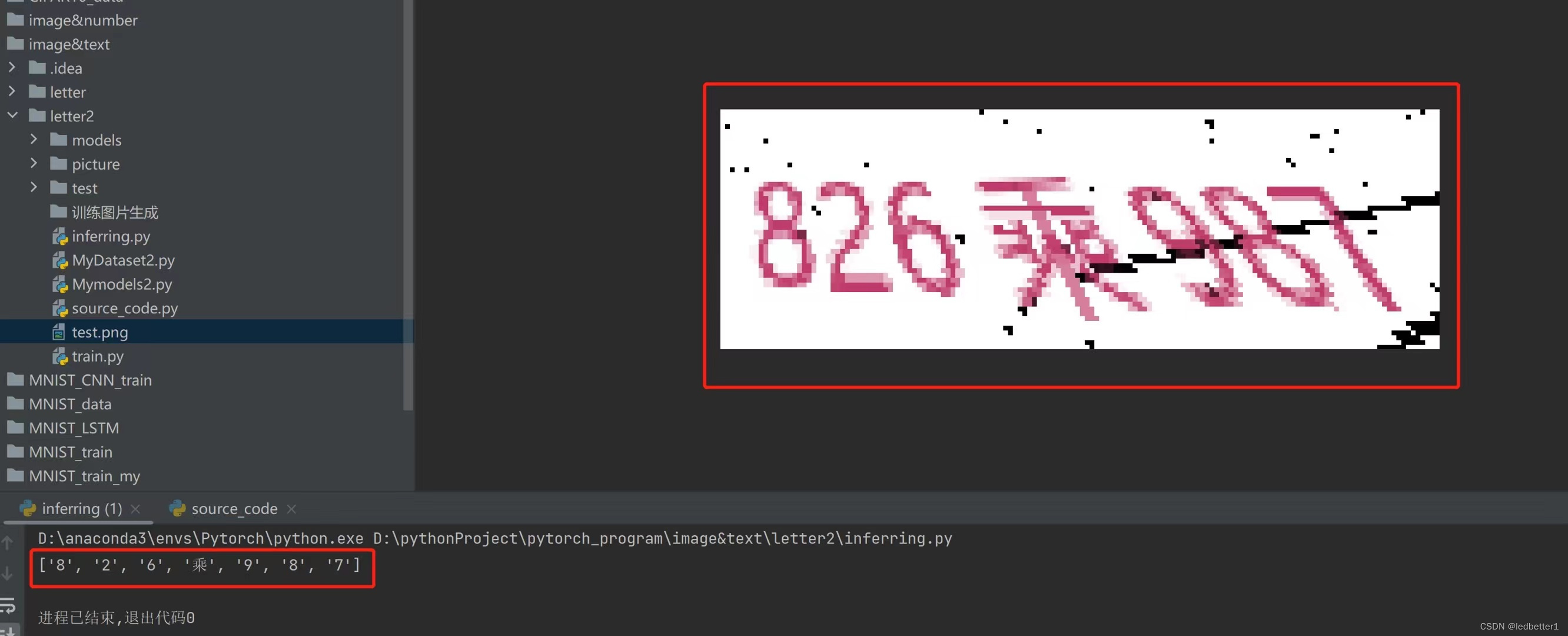
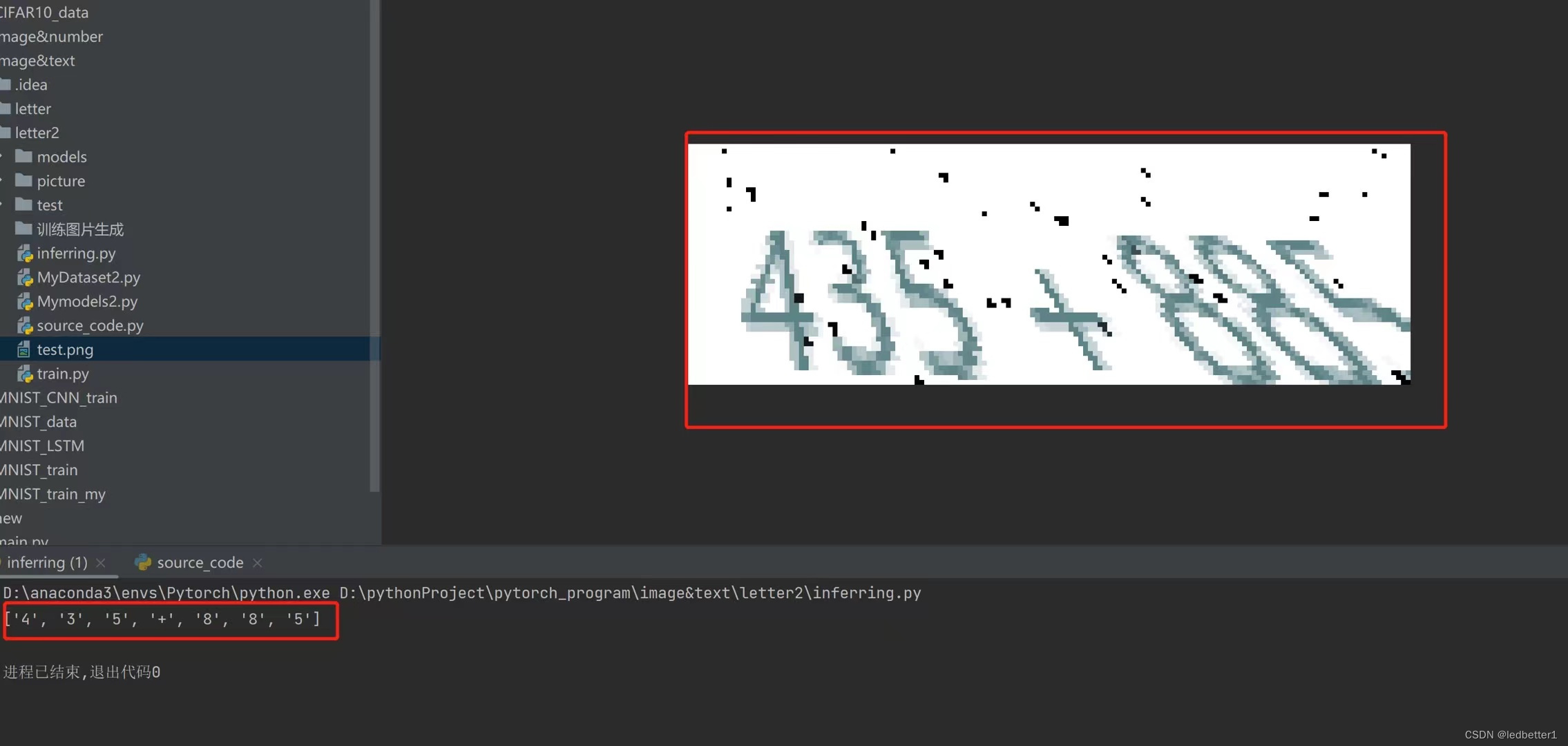
一、代码
1.1 MyDataset.py(用于加载数据集的)
import os
import torch
import numpy as np
from torch.utils.data import Dataset
from torchvision import transforms
from PIL import Image
from tqdm import tqdm
class BetterDataset(Dataset):
def __init__(self, path, my_transforms):
super(BetterDataset).__init__()
self.path = path
self.list_picture_data = list(os.walk(self.path))[0][-1]
# 加_的目的是因为是分割拿特征的,不能保证每次分割的时序都有特征,如果没有特征的用_来表示
self.mapping = [i for i in "_0123456789加减乘+-*"]
self.transform = my_transforms
def __len__(self):
return len(self.list_picture_data)
def __getitem__(self, item):
# 打开图片
images = Image.open(os.path.join(self.path, self.list_picture_data[item]))
if self.transform:
images = self.transform(images)
labels = [self.mapping.index(i) for i in self.list_picture_data[item].split("_")[0]]
# 神经网络训练的隐性要求保持标签长度一致,我们标签最长假设为9位,所以在前面插入0
for i in range(9 - len(labels)):
labels.insert(0, 0)
labels = torch.as_tensor(labels, dtype=torch.int64)
return images, labels, len(labels)
if __name__ == "__main__":
my_transform = transforms.Compose([
# 将图片转换成PyTorch处理的tensor格式
transforms.ToTensor(),
])
my_train = BetterDataset("./picture", my_transform)
"""
images = np.stack([img for img, _ in tqdm(my_train)], axis=0):对于LetterDataset数据集中的每个样本,这行代码会获取该样
本的图像数据,然后将所有样本的图像数据堆叠成一个大的四维张量,其中第0个维度对应样本数,第1个维度对应通道数,第2个维度对应高度,第3个
维度对应宽度。这里使用np.stack函数将图像数据堆叠起来。
res_total = np.mean(images, axis=(0, 2, 3)):这行代码会计算整个数据集的均值。由于图像数据被堆叠成了一个四维张量,因此需要在第0个
维度(样本维度)、第2个维度(高度维度)和第3个维度(宽度维度)上计算均值。因此,axis=(0, 2, 3)参数表示在这些维度上计算均值。
res_std = np.std(images, axis=(0, 2, 3)):这行代码会计算整个数据集的标准差,与计算均值的过程类似,只需在不同维度上计算标准差即可。
"""
list_images = []
for image, label, _ in tqdm(my_train):
list_images.append(image)
total_images = np.stack(list_images, axis=0)
mean_images = np.mean(total_images, axis=(0, 2, 3))
std_images = np.std(total_images, axis=(0, 2, 3))
print(mean_images, std_images)
1.2 Mymodels.py(CRNN模型)
用了ResNet18前四层和LSTM模型
为什么只取前四层是因为假设输入的是112x112的图片,经过第三层卷积的时候图片大小就变成14x14,而LSTM(长短时记忆网络)是一种用于处理序列数据的深度学习模型。它通常用于处理时间序列数据,其中每个时间步都表示序列中的一个数据点。并且是处理图片,所以宽度就成了总时间,时间步就变成了像素为单位的计算方式,如果5层卷积,图片大小就变为了7x7,最后时间步假设为1,那么就算每个空间都有数据,那也只能推导出7个数据,我们这批训练数据,最大可以推导出9个数据,所以选择了ResNet18前四层。
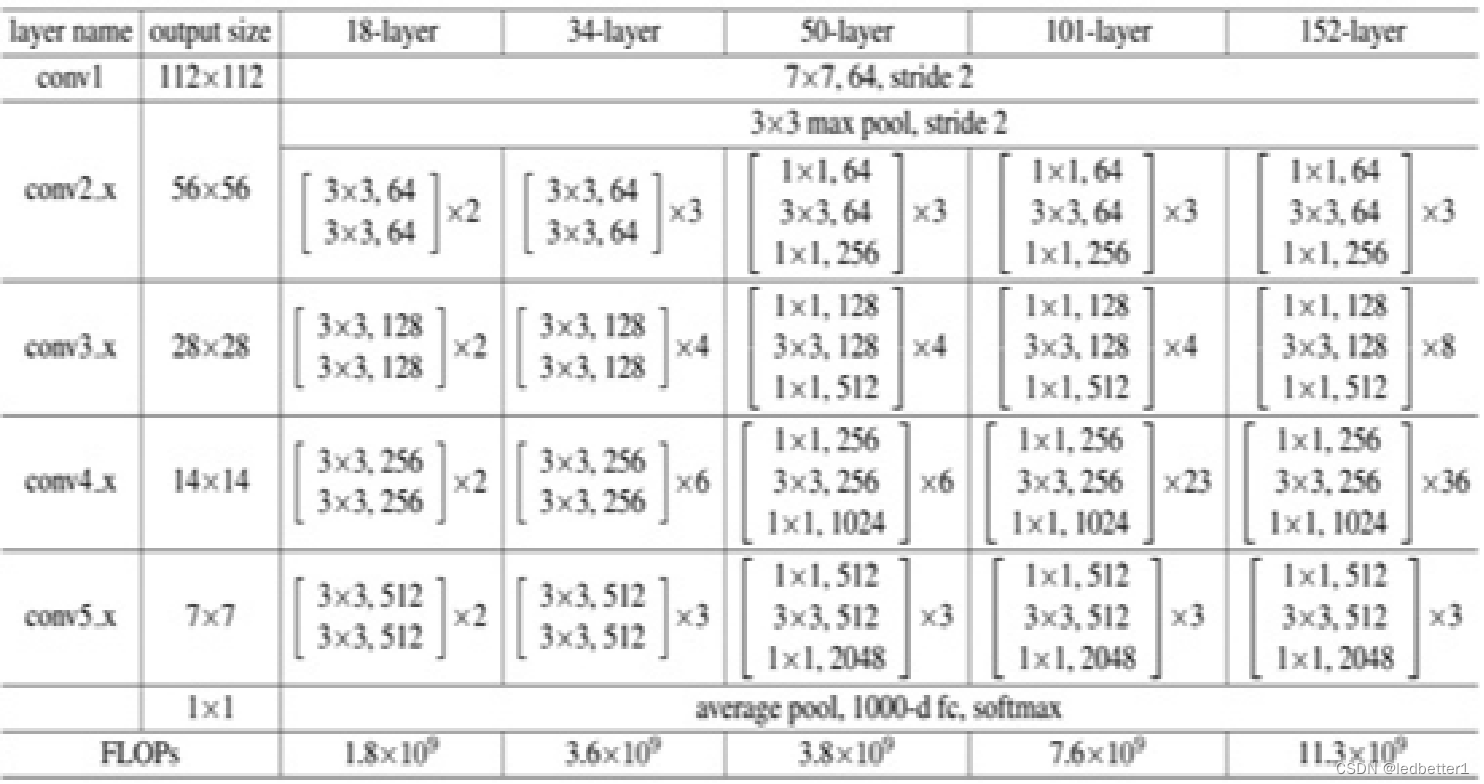
import torch
from torch import nn
from torch.nn import functional as F
class RestNetBasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(RestNetBasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
def forward(self, x):
output = self.conv1(x)
output = F.relu(self.bn1(output))
output = self.conv2(output)
output = self.bn2(output)
return F.relu(x + output)
class RestNetDownBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride):
super(RestNetDownBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride[0], padding=1)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride[1], padding=1)
self.bn2 = nn.BatchNorm2d(out_channels)
self.extra = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride[0], padding=0),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
extra_x = self.extra(x)
output = self.conv1(x)
out = F.relu(self.bn1(output))
out = self.conv2(out)
out = self.bn2(out)
return F.relu(extra_x + out)
class ResNetLstm(nn.Module):
def __init__(self, image_shape):
super(ResNetLstm, self).__init__()
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3)
self.layer1 = nn.Sequential(RestNetBasicBlock(64, 64, 1),
RestNetBasicBlock(64, 64, 1))
self.layer2 = nn.Sequential(RestNetDownBlock(64, 128, [2, 1]),
RestNetBasicBlock(128, 128, 1))
self.layer3 = nn.Sequential(RestNetDownBlock(128, 256, [2, 1]),
RestNetBasicBlock(256, 256, 1))
# nn.LSTM中必须指定输入和隐藏状态的大小。这些参数需要在初始化LSTM时提供,如果没有提供,则会引发错误, 所以这里用image_shape构建一个空的图像数据
with torch.no_grad():
x = torch.zeros((1, 3) + image_shape)
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
size = out.shape
# 只需要特征量乘高度就是输入尺寸
input_size = size[1] * size[2]
self.lstm = nn.LSTM(input_size=input_size, hidden_size=input_size, num_layers=1, bidirectional=True)
# 因为bidirectional=True所以输出的结果input_size*2, 数据加载是17个分类
self.fc = nn.Linear(input_size * 2, 17)
def forward(self, x):
"""
out = self.conv1(x) 将输入x经过卷积层self.conv1得到卷积特征图out。
out = self.layer1(out)、out = self.layer2(out)、out = self.layer3(out) 将卷积特征图out经过三个残差块,得到更加抽象的特征表示。
out = out.permute(3, 0, 1, 2) 对out的维度进行调整,将其从(batch_size, layer, height, width)的形状变为(width, batch_size,
layer, height)的形状。这是因为在LSTM模型中,需要按时间步对数据进行处理,因此将时间步放在第一维。
out_shape = out.shape 记录调整后的out形状。
out = out.view(out_shape[0], out_shape[1], out_shape[2] * out_shape[3]) 将out的维度进行调整,将每个像素点的特征向量拉伸为一维,
得到(width, batch_size, layer*height)的形状。LSMT输入图像数据的规则:[time sequence, batch size, input size]
out, _ = self.lstm(out) 将处理后的特征序列out输入LSTM模型,得到输出序列out。_表示LSTM的隐藏状态,这里我们不需要,因此用下划线代替。
"""
out = self.conv1(x)
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
# LSTM的输入格式是[time sequence, batch size, input size] , 把宽度变为时序,高度和特征量相乘,所以进行轴交换数据把时序数据放第一个
out = out.permute(3, 0, 1, 2)
out_shape = out.shape
out = out.view(out_shape[0], out_shape[1], out_shape[2] * out_shape[3])
out, _ = self.lstm(out)
# 因为全连接层只能有2个参数,所以把三个参数变成两个, 因为bidirectional就变成*2了
"""
首先,out_shape = out.shape 将 LSTM 输出的张量形状保存下来。这个张量的形状是 (seq_len, batch_size, num_directions * hidden_size),
其中 seq_len 表示序列长度,batch_size 表示批次大小,num_directions 表示双向 LSTM 的方向数,hidden_size 表示 LSTM 隐藏层的尺寸。
这里我们需要将 seq_len 和 batch_size 合并成一个维度,所以需要对 out 进行 view 操作,将其变为
(seq_len * batch_size, num_directions * hidden_size) 的形状,
即 out.view(out_shape[0] * out_shape[1], out_shape[2])。
接着,将 out 通过全连接层 self.fc 进行处理,这里的 self.fc 是一个 nn.Linear 类的实例。其输入的形状是 (seq_len * batch_size,
num_directions * hidden_size),输出的形状是 (seq_len * batch_size, 17),其中 17 表示我们需要分类的数目。因此,我们需要调用
out = self.fc(out) 将 out 的形状从 (seq_len * batch_size, num_directions * hidden_size)
变为 (seq_len * batch_size, 17)。
最后,需要将 out 的形状从 (seq_len * batch_size, 17) 变回 (seq_len, batch_size, 17),
即调用 out.view(out_shape[0], out_shape[1], -1)。这个新的张量形状就可以作为整个模型的输出了。
"""
out_shape = out.shape
out = out.view(out_shape[0] * out_shape[1], out_shape[2])
out = self.fc(out)
# 变回原来三个参数
out = out.view(out_shape[0], out_shape[1], -1)
return out
1.3 main.py(主要文件)
import torch
import os
import numpy as np
import itertools
import torch.optim as optim
from tqdm import tqdm
from MyDataset import BetterDataset
from Mymodels import ResNetLstm
from torchvision import transforms
from torch.utils.data import DataLoader
# batch_size(每批处理的数据, 根据性能选择)
BATCH_SIZE = 16
# 选择gpu运行
DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 训练次数
EPOCHS = 10
# 构建transform,对图像做处理
my_transform = transforms.Compose([
# 将图片转换成PyTorch处理的tensor格式
transforms.ToTensor(),
# 进行正则化(对抗过拟合) 这里的数值是由MyDataset.py打印出来的
transforms.Normalize(mean=(0.9253185, 0.92429954, 0.92373), std=(0.20763715, 0.2095286, 0.21057065))
])
# 定义损失函数
loss_fun = torch.nn.CTCLoss()
# 映射表
mapping = [i for i in '_0123456789加减乘+-*']
def deal_data():
"""
划分数据集
:return:
"""
my_train = BetterDataset('./picture', my_transform)
my_test = BetterDataset('./test', my_transform)
# 加载数据集(其中shuffle决定的是是否打乱数据,为了提高模型精度选择True打乱。)
# 训练集
my_train_data = DataLoader(my_train, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
# 测试集
my_test_data = DataLoader(my_test, batch_size=BATCH_SIZE, shuffle=True, drop_last=True)
return my_train_data, my_test_data
def train_model():
"""
训练
:return:
"""
total_loss = []
# 这一步借用了tqdm实现了进度条打印的功能
dataloader = tqdm(train_data, total=len(train_data))
# PyTorch提供的训练方法
model.train()
for image, label, labels_lengths in dataloader:
# 部署到DEVICE
image, label = image.to(DEVICE), label.to(DEVICE)
# 梯度初始化为0
optimizer.zero_grad()
# 向前传播
out_put = model(image)
# 计算损失
"""
input_lengths这行代码创建了一个一维整数张量,它的长度为output.shape[1],即mini-batch的大小。这个张量的每个元素都设置为output张量的第一个
维度的大小,即所有输入序列的长度都相同,等于output.shape[0]。因此,input_lengths是一个包含mini-batch中每个输入序列长度的整数
张量。这个长度信息将被传递给CTC损失函数,用于计算CTC路径得分。
简而言之,这行代码的作用是为每个mini-batch中的输入序列创建一个对应的长度信息,以便计算CTC损失。
"""
input_lengths = torch.IntTensor([out_put.shape[0]] * out_put.shape[1])
loss = loss_fun(out_put, label, input_lengths, labels_lengths)
total_loss.append(loss.item())
# 反向传播
loss.backward()
# 优化器更新
optimizer.step()
# 保存模型
torch.save(model.state_dict(), 'models/model.pkl')
# 保存优化器
torch.save(optimizer.state_dict(), 'models/optimizer.pkl')
return np.mean(total_loss)
def test_model():
# 这一步借用了tqdm实现了进度条打印的功能
dataloader = tqdm(test_data, total=len(test_data))
# PyTorch提供的测试方法
model.eval()
# 统计正确率
success = 0
total = 0
# 不计算梯度,不反向传播
with torch.no_grad():
# 遍历数据集
for (data, label, labels_lengths) in dataloader:
# 将数据和标签移动到指定的设备上
data, label = data.to(DEVICE), label.to(DEVICE)
# 前向传播,得到模型输出
output = model(data)
# 将输出张量的维度从[seq_len, batch_size, num_classes]转换为[batch_size, seq_len, num_classes]
output = output.permute(1, 0, 2)
# 遍历 batch 中的每张图片
for i in range(output.shape[0]):
# 取出张量 output 在第一维上的第 i 个元素,然后在第二维和第三维上取出所有的元素。获取当前图片的输出结果
output_result = output[i, :, :]
# 对输出结果做 argmax,得到最可能的字符序列
output_result = output_result.max(-1)[-1]
# 将标签序列中的数值映射为对应的字符
labels_s = [mapping[i] for i in label[i].cpu().numpy() if mapping[i] != '_']
# 将输出序列中的数值映射为对应的字符,并去除连续重复的字符
output_s = [mapping[i[0]] for i in itertools.groupby(output_result.cpu().numpy()) if i[0] != 0]
# 如果预测结果和真实标签完全一致,则计数器加一
if labels_s == output_s:
success += 1
# 总样本数加一
total += 1
return success / total
if __name__ == "__main__":
# 传入一个尺寸给到模型初始化
size = (50, 150)
model = ResNetLstm(size).to(DEVICE)
optimizer = optim.Adam(model.parameters())
# 加载优化好的模型和优化器继续进行训练
if os.path.exists('models/model.pkl'):
model.load_state_dict(torch.load('./models/model.pkl'))
optimizer.load_state_dict(torch.load('./models/optimizer.pkl'))
train_data, test_data = deal_data()
for epoch in range(EPOCHS):
mean_loss = train_model()
mean_succeed = test_model()
print(f"第{
epoch + 1}次epoch---损失: {
mean_loss}---成功率: {
mean_succeed}")
1.4 inferring.py(验证)
import itertools # 导入 itertools 库,提供迭代器工具
from torchvision import transforms # 导入 torchvision 库中的 transforms 模块,提供常用的图像变换函数
from torch import nn, load, no_grad # 导入 torch 库中的 nn、load 和 no_grad 模块
from PIL import Image # 导入 PIL 库,提供图像处理相关的工具
from Mymodels import ResNetLstm # 导入自定义模型 ResNetLstm
# 构建 transform,对图像做处理
my_transforms = transforms.Compose([
transforms.ToTensor(), # 将图像转换成 PyTorch 处理的 tensor 格式
# 进行正则化(对抗过拟合) 这里的数值是由MyDataset.py打印出来的
transforms.Normalize(mean=(0.9253185, 0.92429954, 0.92373), std=(0.20763715, 0.2095286, 0.21057065)) # 进行正则化
])
mapping = [i for i in '_0123456789加减乘+-*'] # 定义字符映射,将数字和符号转换成可读的文本
if __name__ == "__main__": # 判断是否在主函数中运行
size = (50, 150) # 定义图片大小为 (50, 150)
# 模型实例化,传给 GPU 使用
model = ResNetLstm(size) # 实例化 ResNetLstm 模型
model.load_state_dict(load('./models/model.pkl')) # 加载预训练好的权重
# 打开图片,转换成 PyTorch 处理的 tensor 格式,并移动到模型所在设备上
image = Image.open('./test.png') # 打开指定的图片文件
image = my_transforms(image) # 对图片进行 transform,转换成 PyTorch 处理的 tensor 格式
image = image.view(1, 3, 50, 150) # 将 tensor 格式的图像视图变成 1x3x50x150 的形状
# 预测
model.eval() # 设置为测试模式,不进行梯度计算
with no_grad(): # 不进行梯度计算
out_put = model(image) # 获取模型的输出
output = out_put.permute(1, 0, 2) # 将维度换位,变成 batch_size x seq_len x num_classes 的形状
for i in range(output.shape[0]): # 遍历 batch 中的每张图片
output_result = output[i, :, :] # 获取当前图片的输出结果
output_result = output_result.max(-1)[-1] # 对输出结果做 argmax,得到最可能的字符序列
output_s = [mapping[i[0]] for i in itertools.groupby(output_result.cpu().numpy()) if i[0] != 0] # 对字符序列做处理,得到最终的字符串结果
print(output_s) # 打印输出结果
二、资源
三、结果
我这个目前最好的成功率已经到达百分之98了,经过大概15轮的epoch。模型可以自己选择更换。

借鉴
猿人学-安然导师
PyTorch实现ResNet18
ChatGPT