1.CBAM简介
论文:CBAM: Convolutional Block Attention
Module
提出了一个简单但有效的注意力模块 CBAM,给定一个中间特征图,沿着空间和通道两个维度依次推断出注意力权重,然后与原特征图相乘来对特征进行自适应调整。由于 CBAM 是一个轻量级的通用模块,它可以无缝地集成到任何 CNN 架构中,额外开销忽略不计,并且可以与基本 CNN 一起进行端到端的训练。在不同的分类和检测数据集上,将 CBAM 集成到不同的模型中后,模型的表现都有了一致的提升,展示了其广泛的可应用性。
CBAM可以分为两个部分:通道注意力模块和空间注意力模块,如下图所示。
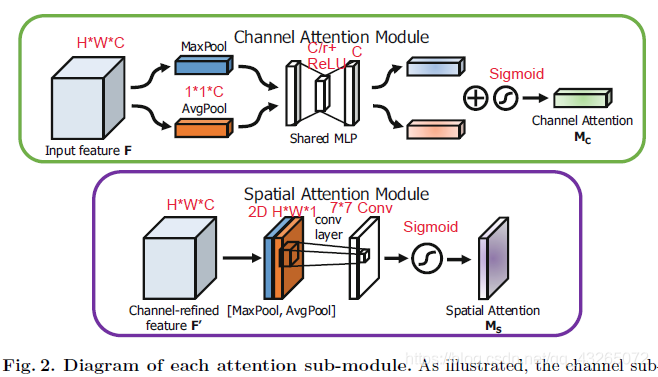
- 通道注意力模块:关注什么(what)的特征有意义
输入一个特征图F为HWC(实际中可能还有batch,即NHWC),首先进行一个全局空间最大池化和平均池化,得到两个11C的descriptor。再将他们分别送入MLP(含有一个隐藏层),第一层神经元个数为C/r,第二层神经元个数为C。这个神经网络是共享(不太明白,是两个descriptor共享还是两层神经网络共享,应该是后者)。再将两个输出向量运用element-wise加法,经过sigmoid函数得到权重系数Mc。最后拿Mc与原来的特征F相乘得到新特征F‘ - 空间注意力模块:关注哪里(where)的特征有意义
输入特征图F’为HWC(同样可能有batch),首先经过通道平均池化和最大池化得到两个HW1的描述子,并按通道拼接。然后经过一个7*7的卷积层和sigmoid激活函数,得到权重系数Ms。最后拿Ms与F‘相乘得到最终注意力特征。
2.代码实现
看完上面的过程就很容易理解代码的实现,这里放两份代码。一份是参考这个博主的代码,另外一份是Github:kobiso/CBAM-tensorflow。
代码一:
def combined_static_and_dynamic_shape(tensor):
"""Returns a list containing static and dynamic values for the dimensions. Returns a list of static
and dynamic values for shape dimensions. This is useful to preserve static shapes when available in reshape operation.
Args: tensor: A tensor of any type.
Returns: A list of size tensor.shape.ndims containing integers or a scalar tensor. """
static_tensor_shape = tensor.shape.as_list()
dynamic_tensor_shape = tf.shape(tensor)
combined_shape = []
for index, dim in enumerate(static_tensor_shape):
if dim is not None:
combined_shape.append(dim)
else:
combined_shape.append(dynamic_tensor_shape[index])
return combined_shape
def convolutional_block_attention_module(feature_map, index, reduction_ratio = 0.5):
"""CBAM:convolutional block attention module
Args:
feature_map:input feature map
index:the index of the module
reduction_ratio:output units number of first MLP layer:reduction_ratio * feature map
Return:
feature map with channel and spatial attention"""
with tf.variable_scope("cbam_%s" % (index)):
feature_map_shape = combined_static_and_dynamic_shape(feature_map)
# channel attention module
channel_avg_weights = tf.nn.avg_pool(value=feature_map,
ksize=[1, feature_map_shape[1], feature_map_shape[2], 1],
strides=[1, 1, 1, 1],
padding='VALID') # global average pool
channel_max_weights = tf.nn.max_pool(value=feature_map,
ksize=[1, feature_map_shape[1], feature_map_shape[2], 1],
strides=[1, 1, 1, 1],
padding='VALID')
channel_avg_reshape = tf.reshape(channel_avg_weights,
[feature_map_shape[0], 1, feature_map_shape[3]])
channel_max_reshape = tf.reshape(channel_max_weights,
[feature_map_shape[0], 1, feature_map_shape[3]])
channel_w_reshape = tf.concat([channel_avg_reshape, channel_max_reshape], axis=1)
fc_1 = tf.layers.dense(inputs=channel_w_reshape,
units=feature_map_shape[3] * reduction_ratio,
name="fc_1",
activation=tf.nn.relu)
fc_2 = tf.layers.dense(inputs=fc_1,
units=feature_map_shape[3],
name="fc_2",
activation=None)
channel_attention = tf.reduce_sum(fc_2, axis=1, name="channel_attention_sum")
channel_attention = tf.nn.sigmoid(channel_attention)
channel_attention = tf.reshape(channel_attention,
shape=[feature_map_shape[0], 1, 1, feature_map_shape[3]])
feature_map_with_channel_attention = tf.multiply(feature_map, channel_attention)
# saptial attention module
# 通道平均池化,格式NWHC
channel_wise_avg_pooling = tf.reduce_mean(feature_map_with_channel_attention, axis=3)
channel_wise_avg_pooling = tf.reshape(channel_wise_avg_pooling,
shape=[feature_map_shape[0], feature_map_shape[1],
feature_map_shape[2], 1]) # shape=[batch, H, W, 1]
# 通道最大池化
channel_wise_max_pooling = tf.reduce_max(feature_map_with_channel_attention, axis=3)
channel_wise_max_pooling = tf.reshape(channel_wise_max_pooling,
shape=[feature_map_shape[0], feature_map_shape[1],
feature_map_shape[2], 1])
# 按通道拼接
channel_wise_pooling = tf.concat([channel_wise_avg_pooling, channel_wise_max_pooling], axis=3)
spatial_attention = slim.conv2d(channel_wise_pooling, 1, [7, 7],
padding='SAME',
activation_fn=tf.nn.sigmoid,
scope="spatial_attention_conv")
feature_map_with_attention = tf.multiply(feature_map_with_channel_attention, spatial_attention)
return feature_map_with_attention这个代码在通道注意力模块实现时,是先把两个11C的描述子拼接然后再输入到MLP,而且两个MLP层权重并没有共享,感觉有点问题。另外一份代码由于字数限制,下篇博客再放上。
我把这个模块放到我的一个手写体MNIST分类四层神经网络中的某一层中,但是感觉没有太多精确度提升,直观上感觉运行更慢了。论文中将CBAM插入到一些大型网络中,我感觉性能提升得也不是特别大。。。