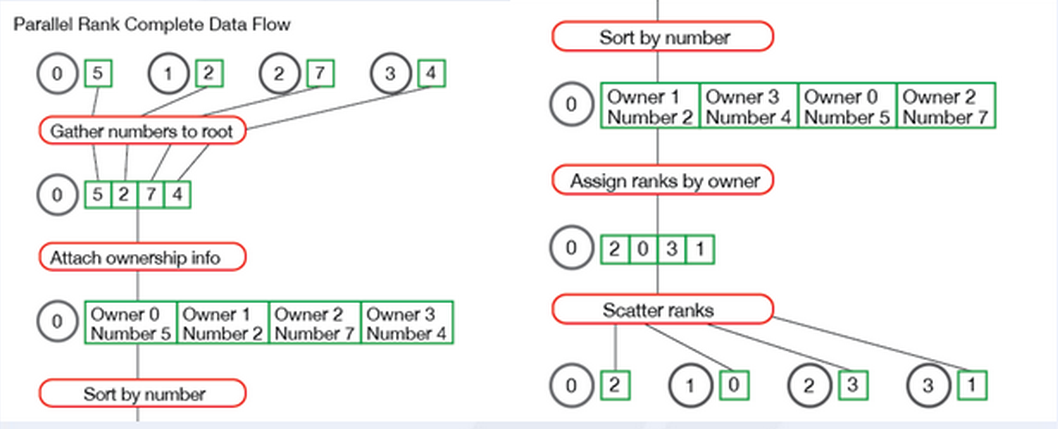
原理:
如图所示,假设每一个进程代表一个节点,在集群中,由于每台设备的性能不同,那么获取集群中每台设备的速度就显得尤为必要,了解每台设备的情况可以更加高效地进行任务分配。
现在,每个进程都拥有一个随机数,我们需要将其收集上来并进行排序,然后将对应的排名顺序分发给各个子进程,这样每个子进程都可以知道自己在整个系统中的排名。
代码如下:
#include <stdio.h>
#include "mpi.h"
#include <string.h>
#include <stdlib.h>
#include <math.h>
#include <time.h>
#define PI 3.1415926
typedef struct
{
int rank;
int val;
} DIC;
//定义 进程-随机数结构体
int main(int argc,char **argv)
{
int size,rank,dest;
MPI_Comm comm = MPI_COMM_WORLD;
MPI_Status status;
MPI_Init(&argc,&argv);
MPI_Comm_size(comm,&size);
MPI_Comm_rank(comm,&rank);
//////////////////////////
int sbuf, rank_buf[size],*rbuf;
if(rank == 0)
{
rbuf = (int*)malloc(sizeof(int)*size);
}
srand(time(NULL)+rank);
sbuf = rand() % 100;//生成随机数
MPI_Gather(&sbuf,1,MPI_INT,rbuf,1,MPI_INT,0,comm);//收集每个进程的数据
/////////////////////////
int rank_buff[size],rcv_rank_buf[1];
DIC dic[size];
if(rank == 0)
{
for(int j = 0; j < size; j++)
{
dic[j].rank = j;
dic[j].val = rbuf[j];
printf("rank is %d , val is %d \n",j,rbuf[j]);
}
/////////////////////////////////////////
int tmp;
for(int m = 0; m < size - 1; m++)
for(int n = 0; n < size - 1 - m; n++)
{
if(rbuf[n] > rbuf[n+1])
{
tmp = rbuf[n];
rbuf[n] = rbuf[n+1];
rbuf[n+1] = tmp;
}
}
//对收集上来的数据进行排序
for(int x = 0; x < size; x++)
{
for(int y = 0; y < size; y++)
{
if(rbuf[x] == dic[y].val)
{
rank_buff[(dic[y].rank)] = x;
dic[y].val = -1;
//printf("rank %d is %d\n",dic[y].rank,x);
break;
}
}
}
}
//分发到各个子进程
MPI_Scatter(rank_buff,1,MPI_INT,rcv_rank_buf,1,MPI_INT,0,comm);
printf("Process %d rank %d\n",rank,rcv_rank_buf[0]);
MPI_Finalize();
return 0;
}
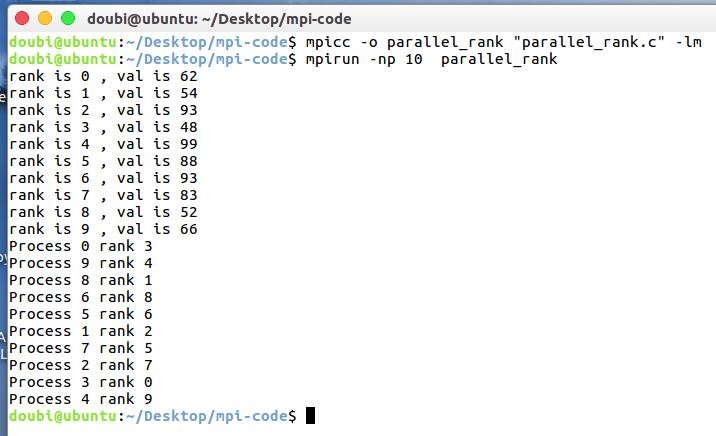
运行结果:
如图所示,开十个进程,上半部分为初始的数据,下半部分为每个进程的排名。