官方文档
例子:
import pandas as pd
import numpy as np
a = pd.DataFrame(np.arange(12).reshape(3,4),columns = list("abdc"))
a =a.sort_index(axis=1,ascending=False)
a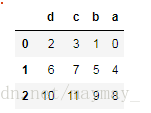
1、直接rank()
a.rank()显示了排名,方向是按照默认的放心,axis=0即 ‘index’

2、加个axis=1
a.rank(axis=1)axis=1即 ’columns’

3、加入排序的方法 method
排序前先修改下a的一个值,只是为了为了让比较效果明显点
a.iloc[[1,1],[1,2]] = 6
a
method为average,即排序是在相等分组中,为各个值分配平均排名,默认值
数字6 在排名时是2,3,4, 取2,3,4平均值3
a.rank(axis=1,method='average')
method为max,即排序是在相等分组中,为各个值取最大,默认值
数字6 在排名时是2,3,4, 取2,3,4最大值4
a.rank(axis=1,method='max')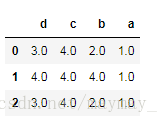
method 为min,就是取最小(例子,略)
method 为first,就是在原始数据中的出现顺序分配排名
a.rank(axis=1,method='first')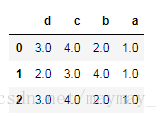
method 为dense : 类似于min,但后续增长的时候每次就增加1
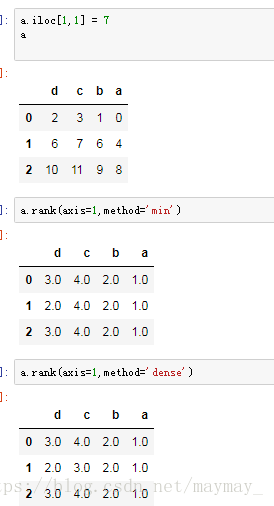
其他参数
numeric_only :Include only float, int, boolean data. Valid only for DataFrame or Panel objects 。boolean, default None
ascending:是否为升序,默认为True
na_option:用于处理NaN值
- ‘keep’:leave NA values where they are
- ‘top’:smallest rank if ascending
- ‘bottom’:smallest rank if dscending
pct:名次是否为百分数