原理:
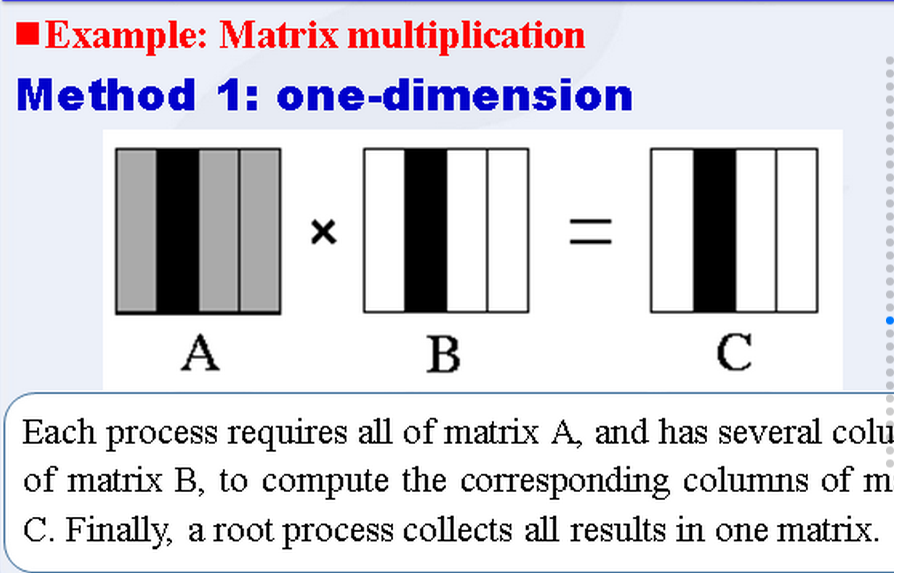
如图所示,将一个矩阵每一列分配给各个子进程,然后在进程内部将一列与另一个矩阵相乘,最后将根进程收集结果并进行输出。
代码如下:
#include <stdio.h>
#include "mpi.h"
#include <string.h>
#include <stdlib.h>
#include <math.h>
#include <time.h>
//生成随机矩阵
int **generate_matrix(int size)
{
int num = 0,m;
int **matrix;
matrix = (int **)malloc(sizeof(int *) * size);
for(m = 0; m < size; m++)
matrix[m] = (int *)malloc(sizeof(int) * size);
int i,j;
srand(time(NULL) + rand());
for(i = 0; i < size; i++)
{
for(j = 0; j < size; j++)
{
matrix[i][j]= rand() % 20;
}
}
return matrix;
}
//输出矩阵
void print_matrx(int **a,int size)
{
int i,j;
for(i = 0; i < size; i++)
{
for(j = 0; j < size; j++)
{
printf("%d ",a[i][j]);
}
printf("\n");
}
printf("\n");
}
//矩阵相乘
int * Multiplication(int **a,int b[],int size)
{
int *result;
result = (int *)malloc(sizeof(int) * size);
int i,m,n,sum = 0;
for(m = 0; m < size; m++)
{
for(n = 0; n < size; n++)
{
sum += a[n][m] * b[n];
}
result[m] = sum;
sum = 0;
}
return result;
}
int main(int argc,char **argv)
{
int size,rank,dest;
MPI_Comm comm = MPI_COMM_WORLD;
MPI_Status status;
MPI_Init(&argc,&argv);
MPI_Comm_size(comm,&size);
MPI_Comm_rank(comm,&rank);
int **matrix1;
int **matrix2;
int send_buff[size*size];
matrix1 = generate_matrix(size);
matrix2 = generate_matrix(size);
if(rank == 0)
{
printf("matrix1 is :\n");
print_matrx((int **)matrix1,size);
printf("matrix2 is :\n");
print_matrx((int **)matrix2,size);
int j,k,tmp = 0;
for(j = 0; j < size; j++)
for(k = 0; k < size; k++)
{
send_buff[tmp] = matrix1[j][k];
tmp++;
}
}
int rbuf[size];
int final_buff[size];
int *result;
result = (int *)malloc(sizeof(int) * size);
//Multiplication((int**)matrix,)
//分发列
MPI_Scatter(send_buff,size,MPI_INT,rbuf,size,MPI_INT,0,comm);
// if(rank == 1)
// {
// printf("rank 1 colounm\n");
// int m;
// for(m = 0; m < size; m++)
// {
// printf("%d ",rbuf[m]);
// }
// }
result = Multiplication((int **)matrix2,rbuf,size);
MPI_Barrier(comm);//等待所有进程计算结束
int *recv_buff;
if(rank == 0)
recv_buff = (int*)malloc(sizeof(int)*size*size);
MPI_Barrier(comm);
// if(rank == 0)
// {
// printf("result is :\n");
// int m;
// for(m = 0; m < size; m++)
// {
// printf("%d ",result[m]);
// }
// printf("\n");
// }
// if(rank == 1)
// {
// int m;
// for(m = 0; m < size; m++)
// {
// printf("%d ",result[m]);
// }
// printf("\n");
// }
// if(rank == 2)
// {
// int m;
// for(m = 0; m < size; m++)
// {
// printf("%d ",result[m]);
// }
// printf("\n");
// }
// printf("size is %d\n",size);
MPI_Gather(result,size,MPI_INT,recv_buff,size,MPI_INT,0,comm);//收集各列数据
//根进程进行输出
if(rank == 0)
{
printf("\nresult is :\n");
int m,n,tmp = 0;
for(m = 0; m < size; m++)
{
for(n = 0;n < size;n++)
{
printf("%d ",recv_buff[tmp]);
tmp++;
}
printf("\n");
}
printf("\n");
}
//MPI_Alltoall(result,size,MPI_INT,final_buff,size,MPI_INT,comm);
//
// if(rank == 0)
// {
// int m;
// for(m = 0; m < size; m++)
// {
// printf("%d ",final_buff[m]);
// }
// }
MPI_Finalize();
return 0;
}
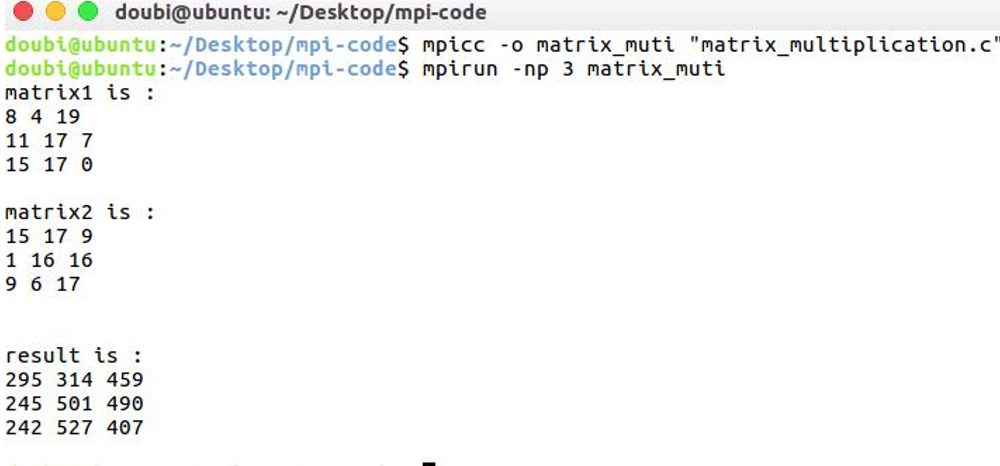
运行结果:
如图所示,根据进程数,随机生成两个数组,得到相应的结果: