从官网down源码YOLOv6:
https://github.com/meituan/YOLOv6
基本环境操作和YOLOv5一致,但数据集的放置和处理和YOLOv5有点不同
1.新建一个yaml文件
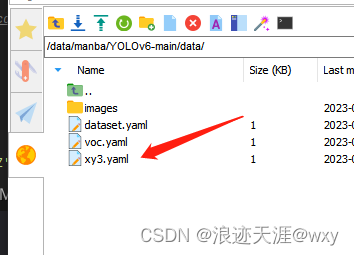 yaml里面存放数据集的访问路径;
yaml里面存放数据集的访问路径;
# COCO 2017 dataset http://cocodataset.org
train: /data/manba/YOLOv6-main/xy3/images/train2017 # 118287 images
val: /data/manba/YOLOv6-main/xy3/images/val2017 # 5000 images
# number of classes
nc: 2
# whether it is coco dataset, only coco dataset should be set to True.
is_coco: False
# class names
names: ["unripe strawberry","ripe strawberry" ]
记住labels要和train2017在同一目录下
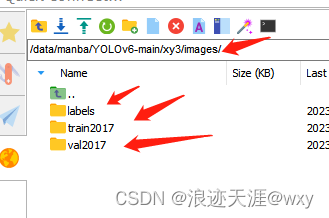
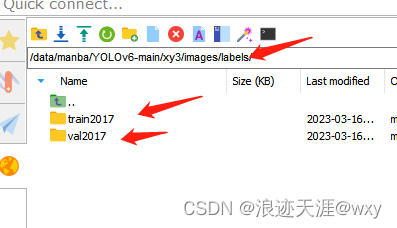
不然总是访问不到labels,其次就是YOLOv6也是txt格式,如果是xml,首先得把的转换成txt,转换脚本和划分数据集脚本如下:
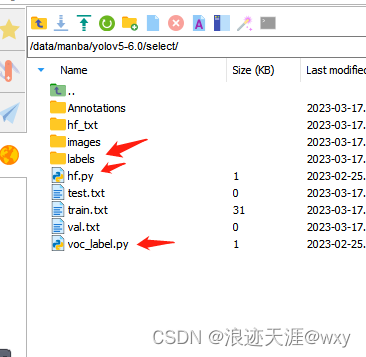 划分脚本
划分脚本
# -*- coding: utf-8 -*-
import os
import random
trainval_percent = 1
train_percent = 1
xmlfilepath = 'Annotations'
txtsavepath = 'images'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('hf_txt/trainval.txt', 'w')
ftest = open('hf_txt/test.txt', 'w')
ftrain = open('hf_txt/train.txt', 'w')
fval = open('hf_txt/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
转换脚本
# -*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
sets = ['train', 'val', 'test']
classes = ["person"]
abs_path = os.getcwd()
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open('Annotations/%s.xml' % (image_id),encoding='utf-8')
out_file = open('labels/%s.txt' % (image_id), 'w',encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
cls = obj.find('name').text
if cls not in classes:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for image_set in sets:
if not os.path.exists('labels/'):
os.makedirs('labels/')
image_ids = open('hf_txt/%s.txt' % (image_set)).read().strip().split()
list_file = open('%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write(abs_path + '/images/%s.png\n' % (image_id))
convert_annotation(image_id)
list_file.close()