本文可以学习到以下内容:
- 免费获取全国省份、城市编码以及经纬度数
- 使用 pandas 中的 read_sql 读取 sqlite 中的数据
- 使用 pandas 中的 merge 方法合并数据
- 使用 groupgy+sort_values 方法实现统计各省人数并降序排列
项目背景
“小凡,数据库users表中有客户的资料,我需要你统计一下各省份的客户数量发给我”,经理在早会上给每个人布置任务时说道。
“收到”,小凡一边记录着一边回答到。
早会结束后,小凡接杯热水,回到工位上,打开dataworks、jupyter、datav、quickbi等工具,开始了新一天的工作…
为什么没有省份的数据呢?小凡看着要统计的数据,满脸疑问。
本来以为是简单的统计数据任务,没想到 users 表中只有城市编码数据,没有省份编码,也没有对应的省份中文名。小凡心中顿时有种不祥的预感,在钉钉上联系数据库运维人员询问情况。
运维同学说,当初在设计表的时候没有考虑到省份,所以数据库没有省份字段,让小凡自己想想办法。
小凡也很无奈,现在急切需要找到一份省份编码映射表,逛了各大论坛,找了各种博客网站,问了许多技术朋友
终于在高德地图网站上找到了需要的数据资源:
- 数据已经写入 data.db 数据库中的 adcode_lng_lat 表中
- Excel 文件《省市adcode与经纬度映射表.xlsx》存放在文件夹【数据加工厂】中
剩下的就交给代码吧!
项目代码
小凡常用的数据分析工具:
import os
import datetime
import numpy as np
import pandas as pd
from sqlalchemy import create_engine
数据放在上一级的目录下名为 data.db 的文件
# 数据库地址:数据库放在上一级目录下
db_path = os.path.join(os.path.dirname(os.getcwd()), "data.db")
engine_path = "sqlite:///" + db_path
# 创建数据库引擎
engine = create_engine(engine_path)
sql = """
select * from users
"""
df = pd.read_sql(sql, engine)
用 pandas 的 head() 方法查看前5条数据:
df.head()

新增省份编码
adcode 是城市编码,用前2位加上0000就是省份编码,比如:431081对应的省份编码是430000。
在df后面新增一列省份编码:
df = df.astype(str)
df["province_adcode"] = df["adcode"].map(lambda x:x[:2]+"0000")
获取编码映射数据
sql = """
select * from adcode_lng_lat
"""
adcode_lng_lat_df = pd.read_sql(sql, engine)
合并数据
result_df = pd.merge(df,adcode_lng_lat_df[["adcode","name"]].astype(str),left_on="province_adcode",right_on="adcode",how="left")
用pandas 中的 sample() 方法随机查看10条数据:
result_df.sample(10)
统计省份用户数
使用 groupgy+sort_values 方法实现统计各省人数并降序排列,代码如下:
province_count_df = result_df.groupby(by="name").agg(
{
"user_id":"count"}
).sort_values(by="user_id",ascending=False).reset_index()
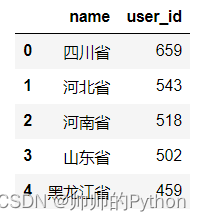
用 pandas 的 head() 方法查看前5条数据:
province_count_df.head()
使用SQL实现
- sqlite3 的字符串拼接用"||"符号实现
- sqlite3 字符串切割用 SUBSTRING(字符串,开始位置,结束位置)
select
b.name
,count(a.user_id) as users_num
from
(
select
user_id,
username,
adcode,
SUBSTRING(adcode, 1, 2) || '0000' as province_code
from
users
) as a
left join
(
select
adcode as province_code,
name
FROM
adcode_lng_lat
) as b on a.province_code = b.province_code
group by b.name
order by count(a.user_id) desc
;
源码地址
链接:https://pan.baidu.com/s/1ldj51uKEPjpXmAz3XgHiLg?pwd=cj2v
提取码:cj2v