第三部分 LLaMA的RLHF版:ChatLLaMA和ColossalChat
3.1 ChatLLaMA(英文版):类似SFT、RM、RL/PPO训练三步骤
由于LLaMA没有使用RLHF方法,初创公司 Nebuly AI开源了RLHF版的LLaMA,即ChatLLaMA
其训练过程类似 ChatGPT,而通过本博客内的《ChatGPT技术原理解析》3.1节,可知训练三个模型(SFT、RM、RL/PPO)得先准备三套数据集
- actor_training_data,即用于微调GPT3所用的数据,比如
[
{
"user_input": "here the input of the user",
"completion": "here the model completion"
}
]
actor_training_data如何而来呢,有4项途径
①使用 100% 合成数据,可以通过运行以下命令综合生成数据集:
python artifacts/generate_actor_dataset.py,注:此命令需要订阅OpenAI,生成完整数据集的davinci-003成本约为 200 美元(当然 也有免费的途径)
②使用具有辅助交互的开源数据集之一,目前支持:
Anthropic HH RLHF:这个数据集由结构化的 { question/answer pairs} 组成,包括机器人选择和拒绝的答案;
Stanford Human Preferences Dataset (SHP):这个数据集是从选定的“提问”subreddits 中挑选出来的,并且包括基于最受支持的回答的范围广泛的 { question/answer pairs} 的问题
可以运行以下命令下载数据集:
其中:python artifacts/download_dataset.py <dataset_name> --path <path_to_folder_for_download> --number_of_samples <N>
<dataset_name>对于 StanfordNLP/SHP 数据集,可以是“SHP”或“ARLHF”,对于 Anthropic/hh-rlhf 数据集,可以分别是“SHP”或“ARLHF”;
<path_to_folder_for_download>是要创建数据集的文件夹路径;
<N>是组成 reward_dataset.json 的样本数
③使用 100% 个性化数据集
用户提供自己的个性化完整数据集,数据集必须是具有以下格式的 JSON 文件:[
④创建完整的数据集,增加一些自定义数据样本,数据集可以从用户提供的一些提示+响应示例中综合生成(少数 => 10)
{
"user_input": "here the input of the user",
"completion": "here the model completion"
}
]
其中列表包含多个dictionaries,每个dictionary 对应一个数据样本,建议使用超过 1000 个数据样本来进行对actor的训练
- reward_training_data,用于训练一个奖励模型的数据,包含三部分的数据:
i) prompts,
ii) completion
iii) score of the completion assigned accordingly to the user feedback (the Human Feedback in RLHF,即对各个回答的评分score)
示例如下
[{
"user_input": "...",
"completion": "...",
"score": 1
},
...
]
同样的,奖励数据怎么来呢?有以下三种方式1 be synthetically scored using a LLM as Human Feedback
LLM 模型用于为每个entry计算分数
为此,LLM 需要一个提示模板,其中包含评估生成的文本的所有说明(比如奖励规则,什么情况下该奖 什么情况下不奖都得十分明确)。为此,您应该将key reward添加到文件中templates.json,比如:
{"reward": "Here is the template for the reward model. The rules are:\n\n1.Rule 1\n\n2. Rule 2"
}
如果未提供模板,则使用默认模板artifacts/generate_rewards.py,注:所有模板都必须保存在一个名为 .json 的 JSON 文件中templates.json获得unlabelled dataset后,您可以通过运行以下命令生成分数:
其中,<dataset_path>要评分的reward dataset的路径;python artifacts/generate_rewards.py <dataset_path> --model <model_to_use> --temperature <t> --max_tokens <n> --reward_template <path_to_file.json>
<model_to_use>用于奖励的模型,默认建议使用text-davinci-003
<temperature>用于对模型进行评分的temperature,temperature =0.1;
<max_tokens>
<reward_template>,这是包含用于生成奖励的模板的文件的路径,如果未提供路径,将使用默认模板[ { "user_input": "here type the user input", "completion": "here type the completion", "score": 4.0 }, { "user_input": "here type the user input", "completion": "random garbage", "score": 0.0 } ] - rlhf_training_data,通过RL方法不断优化迭代最优策略的数据
It can be provided in 2 different ways:
需要将key rlhf添加到templates.json文件中,其中包含有关要执行的任务的信息以及 LLM 生成所需的额外上下文,这是模板的示例(所有模板必须保存在一个名为templates.json):{
"rlhf": "Here is the template for the generating RLHF prompts. The task we want to perform is ..."
}
数据集需要包含超过 1000 个提示示例(文件命名为rlhf_training_data.json):[
{
"user_input": "here the example of user input"
}
]
以下是其主函数的代码,代码结构还是很清晰的
import argparse
from chatllama.rlhf.actor import ActorTrainer
from chatllama.rlhf.config import Config
from chatllama.rlhf.dataset import BaseDataset
from chatllama.rlhf.reward import RewardTrainer
from chatllama.rlhf.trainer import RLTrainer
# Setup argument parser
parser = argparse.ArgumentParser(
prog="main.py", description="RLHF Training of ChatBots"
)
parser.add_argument("configfile", help="Path to config.yaml file")
parser.add_argument(
"-t",
"--type",
help=(
"Specify the training type. RL: Training of the model using RL."
"ACTOR: Training of the actor model. "
"REWARD: Training of the reward model."
"RL: The whole pipeline with the three training steps"
),
default="ALL",
choices=["ALL", "RL", "ACTOR", "REWARD"],
)
parser.add_argument(
"-a", "--actor", help="Specify actor model by name", default=None
)
parser.add_argument(
"-r", "--reward", help="Specify reward model by name", default=None
)
# parse arguments
args = parser.parse_args()
# load config.yaml with all the project informations
config = Config(args.configfile)
# overwrite config if specified differently
if args.actor is not None:
config.actor.model = args.actor
if args.reward is not None:
config.reward.model = args.reward
# perform the desired training
if args.type == "RL":
max_seq = min(
config.actor.max_sequence_length,
config.reward.max_sequence_length,
config.critic.max_sequence_length,
)
config.actor.max_sequence_length = max_seq
BaseDataset.clean_dataset(config)
rlhf_trainer = RLTrainer(config)
rlhf_trainer.train()
elif args.type == "ACTOR":
BaseDataset.clean_dataset(config.actor)
actor_trainer = ActorTrainer(config.actor)
actor_trainer.train()
elif args.type == "REWARD":
BaseDataset.clean_dataset(config.reward)
reward_trainer = RewardTrainer(config.reward)
reward_trainer.train()
elif args.type == "ALL":
reward_trainer = RewardTrainer(config.reward)
reward_trainer.train()
actor_trainer = ActorTrainer(config.actor)
actor_trainer.train()
rlhf_trainer = RLTrainer(config)
rlhf_trainer.train()3.2 ColossalChat:通过self-instruct技术指令微调LLaMA且加上RLHF
据介绍(介绍页面,该页面的翻译之一,代码地址),Colossal-AI 开源了基于 LLaMA-7B 模型的包含完整 RLHF 流程的类 Chat 模型复现方案 ColossalChat
- 关于数据集:包含10.4万条问答的中、英双语数据集(这是数据的开源地址)
该数据集收集并清洗了社交平台上人们的真实提问场景作为种子数据集,且利用 self-instruct 技术扩充数据(通过prompt OpenAI API),花费约 900 美元进行标注
对比其他 self-instruct 方法生成的数据集,该数据集的种子数据更加真实、丰富,生成的数据集涵盖的话题更多,该数据可以同时用于微调和 RLHF 训练,通过高质量的数据,ColossalChat 能进行更好地对话交互,同时支持中文
- 关于训练方式:类似instructGPT/ChatGPT的训练三步骤(如果忘了,务必复习下此文的3.1节)
Stage1 是supervised-fintuning,即使用上文提到的数据集进行监督微调
Stage2 训练一个奖励模型(初始化为阶段1的SFT模型),它通过模型对于同一个 prompt 的不同输出进行人工排序,根据排序结果监督训练出一个奖励模型
Stage3 是通过阶段2训练出来的奖励函数微调出一个RL模型,微调过程中通过PPO算法限制RL模型的参数更新范围(以阶段1的SFT模型的策略为参考基准,PPO算法避免与基线模型SFT的策略偏离过远)
具体而言,为两个阶段进行: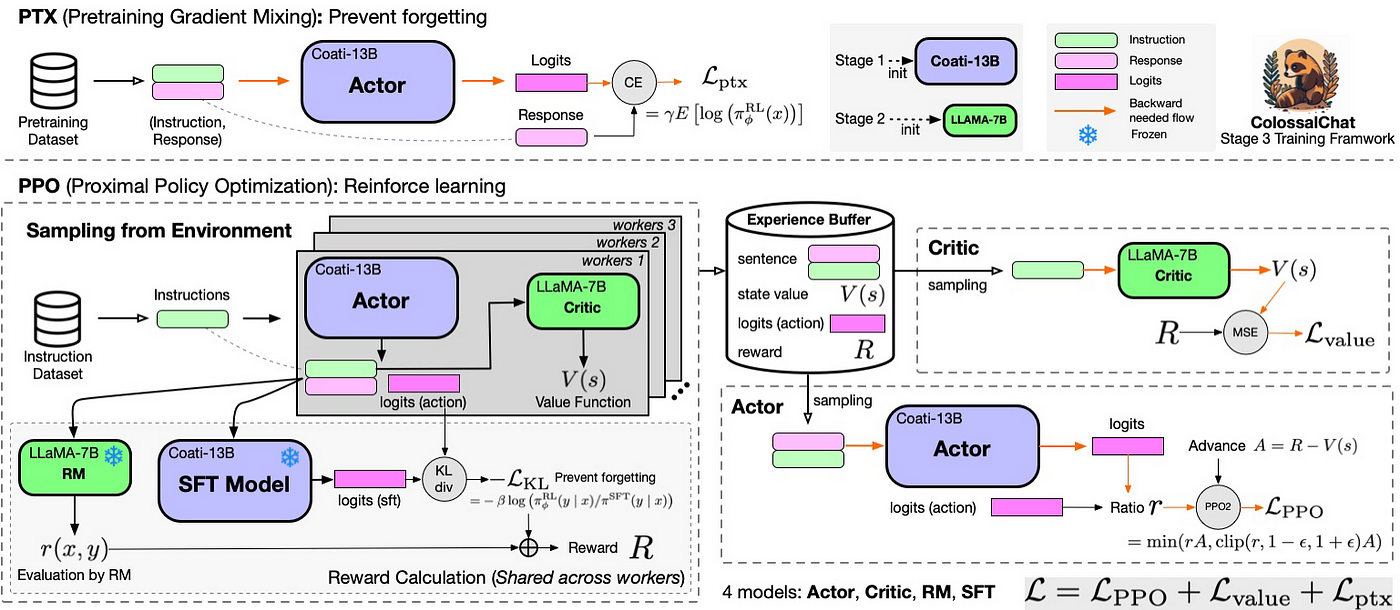
和策略损失(policy loss),类似
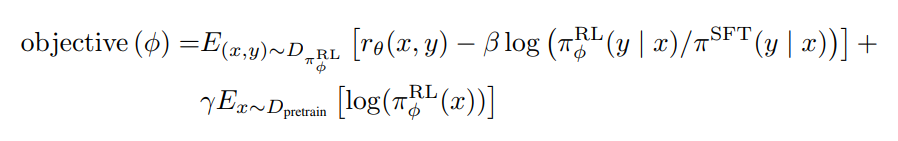
中加在最后的偏置项)
ColossalChat 计算 Actor 的现有输出response 和预训练语料的回答部分的交叉熵损失函数(calculates the cross-entropy loss between the Actor’s output response and the response part of the input corpus)
用来在 PPO 梯度中加入预训练梯度(add pre-training gradients to the PPO gradient)
以保持语言模型比如GPT2原有的核心性能(maintain the language model’s original performance and prevent forgetting),防止忘了最早从哪里出发的(GPT2
最后将策略损失、价值损失和 PTX 损失加和(the policy loss, value loss, and PTX loss are summed up),进行反向传播和参数更新 - 关于代码实现
首先通过ColossalAI/applications/Chat/coati/trainer/sft.py,训练一个SFT模型
import math import time from abc import ABC from typing import Optional import loralib as lora import torch import torch.distributed as dist import wandb from coati.models.loss import GPTLMLoss from torch import nn from torch.optim import Adam, Optimizer from torch.optim.lr_scheduler import LambdaLR from torch.utils.data import DataLoader from torch.utils.data.distributed import DistributedSampler from tqdm import tqdm from transformers.tokenization_utils_base import PreTrainedTokenizerBase from transformers.trainer import get_scheduler from colossalai.logging import get_dist_logger from .strategies import Strategy from .utils import is_rank_0 class SFTTrainer(ABC): """ Trainer to use while training reward model. Args: model (torch.nn.Module): the model to train strategy (Strategy): the strategy to use for training optim(Optimizer): the optimizer to use for training train_dataloader: the dataloader to use for training eval_dataloader: the dataloader to use for evaluation batch_size (int, defaults to 1): the batch size while training max_epochs (int, defaults to 2): the number of epochs to train optim_kwargs (dict, defaults to {'lr':1e-4}): the kwargs to use while initializing optimizer """ def __init__( self, model, strategy: Strategy, optim: Optimizer, train_dataloader: DataLoader, eval_dataloader: DataLoader = None, batch_size: int = 1, max_epochs: int = 2, accimulation_steps: int = 8, ) -> None: super().__init__() self.strategy = strategy self.epochs = max_epochs self.train_dataloader = train_dataloader self.eval_dataloader = eval_dataloader self.model = strategy.setup_model(model) if "DDP" in str(self.strategy): self.model = self.model.module self.optimizer = strategy.setup_optimizer(optim, self.model) self.accimulation_steps = accimulation_steps num_update_steps_per_epoch = len(train_dataloader) // self.accimulation_steps max_steps = math.ceil(self.epochs * num_update_steps_per_epoch) self.scheduler = get_scheduler("cosine", self.optimizer, num_warmup_steps=math.ceil(max_steps * 0.03), num_training_steps=max_steps) def fit(self, logger, log_interval=10): wandb.init(project="Coati", name=time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) wandb.watch(self.model) total_loss = 0 # epoch_bar = tqdm(range(self.epochs), desc='Epochs', disable=not is_rank_0()) step_bar = tqdm(range(len(self.train_dataloader) // self.accimulation_steps * self.epochs), desc=f'steps', disable=not is_rank_0()) for epoch in range(self.epochs): # process_bar = tqdm(range(len(self.train_dataloader)), desc=f'Train process for{epoch}', disable=not is_rank_0()) # train self.model.train() for batch_id, batch in enumerate(self.train_dataloader): prompt_ids = batch["input_ids"].to(torch.cuda.current_device()) p_mask = batch["attention_mask"].to(torch.cuda.current_device()) labels = batch["labels"].to(torch.cuda.current_device()) # prompt_ids = prompt_ids.squeeze(1).cuda() # p_mask = p_mask.squeeze(1).cuda() # prompt_logits = self.model(prompt_ids, attention_mask=p_mask, labels=labels) outputs = self.model(prompt_ids, attention_mask=p_mask, labels=labels) loss = outputs.loss prompt_logits = outputs.logits if loss >= 2.5: logger.warning(f"batch_id:{batch_id}, abnormal loss: {loss}") loss = loss / self.accimulation_steps self.strategy.backward(loss, self.model, self.optimizer) total_loss += loss.item() # gradient accumulation if (batch_id + 1) % self.accimulation_steps == 0: self.strategy.optimizer_step(self.optimizer) self.optimizer.zero_grad() self.scheduler.step() wandb.log({ "loss": total_loss / self.accimulation_steps, "lr": self.scheduler.get_last_lr()[0], "epoch": epoch, "batch_id": batch_id }) total_loss = 0 step_bar.update() # if batch_id % log_interval == 0: # logger.info(f'Train Epoch {epoch}/{self.epochs} Batch {batch_id} Rank {dist.get_rank()} loss {loss.item()}') # wandb.log({"loss": loss.item()}) # process_bar.update() # eval if self.eval_dataloader is not None: self.model.eval() with torch.no_grad(): loss_sum = 0 num_seen = 0 for batch in self.eval_dataloader: prompt_ids = batch["input_ids"].to(torch.cuda.current_device()) p_mask = batch["attention_mask"].to(torch.cuda.current_device()) labels = batch["labels"].to(torch.cuda.current_device()) # prompt_ids = prompt_ids.squeeze(1).cuda() # p_mask = p_mask.squeeze(1).cuda() outputs = self.model(prompt_ids, attention_mask=p_mask, labels=labels) loss = outputs.loss # prompt_logits = outputs.logits loss_sum += loss.item() num_seen += prompt_ids.size(0) loss_mean = loss_sum / num_seen if dist.get_rank() == 0: logger.info(f'Eval Epoch {epoch}/{self.epochs} loss {loss_mean}') # epoch_bar.update() def save_model(self, path: str, only_rank0: bool = False, tokenizer: Optional[PreTrainedTokenizerBase] = None) -> None: self.strategy.save_model(model=self.model, path=path, only_rank0=only_rank0, tokenizer=tokenizer)
其次,通过ColossalAI/applications/Chat/coati/trainer/rm.py 训练一个奖励模型from abc import ABC from datetime import datetime from typing import Optional import pandas as pd import torch import torch.distributed as dist from torch.optim import Optimizer, lr_scheduler from torch.utils.data import DataLoader, Dataset, DistributedSampler from tqdm import tqdm from transformers.tokenization_utils_base import PreTrainedTokenizerBase from .strategies import Strategy from .utils import is_rank_0 class RewardModelTrainer(ABC): """ Trainer to use while training reward model. Args: model (torch.nn.Module): the model to train strategy (Strategy): the strategy to use for training optim(Optimizer): the optimizer to use for training loss_fn (callable): the loss function to use for training train_dataset (Dataset): the dataset to use for training valid_dataset (Dataset): the dataset to use for validation eval_dataset (Dataset): the dataset to use for evaluation batch_size (int, defaults to 1): the batch size while training max_epochs (int, defaults to 2): the number of epochs to train """ def __init__( self, model, strategy: Strategy, optim: Optimizer, loss_fn, train_dataset: Dataset, valid_dataset: Dataset, eval_dataset: Dataset, batch_size: int = 1, max_epochs: int = 1, ) -> None: super().__init__() self.strategy = strategy self.epochs = max_epochs train_sampler = None if dist.is_initialized() and dist.get_world_size() > 1: train_sampler = DistributedSampler(train_dataset, shuffle=True, seed=42, drop_last=True) self.train_dataloader = DataLoader(train_dataset, shuffle=(train_sampler is None), sampler=train_sampler, batch_size=batch_size) self.valid_dataloader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=True) self.eval_dataloader = DataLoader(eval_dataset, batch_size=batch_size, shuffle=True) self.model = strategy.setup_model(model) self.loss_fn = loss_fn self.optimizer = strategy.setup_optimizer(optim, self.model) self.scheduler = lr_scheduler.CosineAnnealingLR(self.optimizer, self.train_dataloader.__len__() // 100) def eval_acc(self, dataloader): dist = 0 on = 0 cnt = 0 self.model.eval() with torch.no_grad(): for chosen_ids, c_mask, reject_ids, r_mask in dataloader: chosen_ids = chosen_ids.squeeze(1).to(torch.cuda.current_device()) c_mask = c_mask.squeeze(1).to(torch.cuda.current_device()) reject_ids = reject_ids.squeeze(1).to(torch.cuda.current_device()) r_mask = r_mask.squeeze(1).to(torch.cuda.current_device()) chosen_reward = self.model(chosen_ids, attention_mask=c_mask) reject_reward = self.model(reject_ids, attention_mask=r_mask) for i in range(len(chosen_reward)): cnt += 1 if chosen_reward[i] > reject_reward[i]: on += 1 dist += (chosen_reward - reject_reward).mean().item() dist_mean = dist / len(dataloader) acc = on / cnt self.model.train() return dist_mean, acc def fit(self): time = datetime.now() epoch_bar = tqdm(range(self.epochs), desc='Train epoch', disable=not is_rank_0()) for epoch in range(self.epochs): step_bar = tqdm(range(self.train_dataloader.__len__()), desc='Train step of epoch %d' % epoch, disable=not is_rank_0()) # train self.model.train() cnt = 0 acc = 0 dist = 0 for chosen_ids, c_mask, reject_ids, r_mask in self.train_dataloader: chosen_ids = chosen_ids.squeeze(1).to(torch.cuda.current_device()) c_mask = c_mask.squeeze(1).to(torch.cuda.current_device()) reject_ids = reject_ids.squeeze(1).to(torch.cuda.current_device()) r_mask = r_mask.squeeze(1).to(torch.cuda.current_device()) chosen_reward = self.model(chosen_ids, attention_mask=c_mask) reject_reward = self.model(reject_ids, attention_mask=r_mask) loss = self.loss_fn(chosen_reward, reject_reward) self.strategy.backward(loss, self.model, self.optimizer) self.strategy.optimizer_step(self.optimizer) self.optimizer.zero_grad() cnt += 1 if cnt == 100: self.scheduler.step() dist, acc = self.eval_acc(self.valid_dataloader) cnt = 0 if is_rank_0(): log = pd.DataFrame([[step_bar.n, loss.item(), dist, acc]], columns=['step', 'loss', 'dist', 'acc']) log.to_csv('log_%s.csv' % time, mode='a', header=False, index=False) step_bar.update() step_bar.set_postfix({'dist': dist, 'acc': acc}) # eval dist, acc = self.eval_acc(self.eval_dataloader) if is_rank_0(): log = pd.DataFrame([[step_bar.n, loss.item(), dist, acc]], columns=['step', 'loss', 'dist', 'acc']) log.to_csv('log.csv', mode='a', header=False, index=False) epoch_bar.update() step_bar.set_postfix({'dist': dist, 'acc': acc}) step_bar.close() def save_model(self, path: str, only_rank0: bool = False, tokenizer: Optional[PreTrainedTokenizerBase] = None) -> None: self.strategy.save_model(model=self.model, path=path, only_rank0=only_rank0, tokenizer=tokenizer)
最后,通过ColossalAI/applications/Chat/coati/trainer/ppo.py to start PPO trainingfrom typing import Any, Callable, Dict, List, Optional import torch import torch.nn as nn from coati.experience_maker import Experience, NaiveExperienceMaker from coati.models.base import Actor, Critic from coati.models.generation_utils import update_model_kwargs_fn from coati.models.loss import PolicyLoss, ValueLoss from coati.replay_buffer import NaiveReplayBuffer from torch.optim import Optimizer from transformers.tokenization_utils_base import PreTrainedTokenizerBase from .base import Trainer from .callbacks import Callback from .strategies import Strategy class PPOTrainer(Trainer): """ Trainer for PPO algorithm. Args: strategy (Strategy): the strategy to use for training actor (Actor): the actor model in ppo algorithm critic (Critic): the critic model in ppo algorithm reward_model (nn.Module): the reward model in rlhf algorithm to make reward of sentences initial_model (Actor): the initial model in rlhf algorithm to generate reference logits to limit the update of actor actor_optim (Optimizer): the optimizer to use for actor model critic_optim (Optimizer): the optimizer to use for critic model kl_coef (float, defaults to 0.1): the coefficient of kl divergence loss train_batch_size (int, defaults to 8): the batch size to use for training buffer_limit (int, defaults to 0): the max_size limitaiton of replay buffer buffer_cpu_offload (bool, defaults to True): whether to offload replay buffer to cpu eps_clip (float, defaults to 0.2): the clip coefficient of policy loss value_clip (float, defaults to 0.4): the clip coefficient of value loss experience_batch_size (int, defaults to 8): the batch size to use for experience generation max_epochs (int, defaults to 1): the number of epochs of training process tokenier (Callable, optional): the tokenizer to use for tokenizing the input sample_replay_buffer (bool, defaults to False): whether to sample from replay buffer dataloader_pin_memory (bool, defaults to True): whether to pin memory for data loader callbacks (List[Callback], defaults to []): the callbacks to call during training process generate_kwargs (dict, optional): the kwargs to use while model generating """ def __init__(self, strategy: Strategy, actor: Actor, critic: Critic, reward_model: nn.Module, initial_model: Actor, actor_optim: Optimizer, critic_optim: Optimizer, kl_coef: float = 0.1, ptx_coef: float = 0.9, train_batch_size: int = 8, buffer_limit: int = 0, buffer_cpu_offload: bool = True, eps_clip: float = 0.2, value_clip: float = 0.4, experience_batch_size: int = 8, max_epochs: int = 1, tokenizer: Optional[Callable[[Any], dict]] = None, sample_replay_buffer: bool = False, dataloader_pin_memory: bool = True, callbacks: List[Callback] = [], **generate_kwargs) -> None: experience_maker = NaiveExperienceMaker(actor, critic, reward_model, initial_model, kl_coef) replay_buffer = NaiveReplayBuffer(train_batch_size, buffer_limit, buffer_cpu_offload) generate_kwargs = _set_default_generate_kwargs(strategy, generate_kwargs, actor) super().__init__(strategy, experience_maker, replay_buffer, experience_batch_size, max_epochs, tokenizer, sample_replay_buffer, dataloader_pin_memory, callbacks, **generate_kwargs) self.actor = actor self.critic = critic self.actor_loss_fn = PolicyLoss(eps_clip) self.critic_loss_fn = ValueLoss(value_clip) self.ptx_loss_fn = nn.CrossEntropyLoss(ignore_index=-100) self.ptx_coef = ptx_coef self.actor_optim = actor_optim self.critic_optim = critic_optim def training_step(self, experience: Experience) -> Dict[str, float]: self.actor.train() self.critic.train() # policy loss num_actions = experience.action_mask.size(1) action_log_probs = self.actor(experience.sequences, num_actions, attention_mask=experience.attention_mask) actor_loss = self.actor_loss_fn(action_log_probs, experience.action_log_probs, experience.advantages, action_mask=experience.action_mask) # ptx loss if self.ptx_coef != 0: ptx = next(iter(self.pretrain_dataloader))['input_ids'].to(torch.cuda.current_device()) label = next(iter(self.pretrain_dataloader))['labels'].to(torch.cuda.current_device())[:, 1:] attention_mask = next(iter(self.pretrain_dataloader))['attention_mask'].to(torch.cuda.current_device()) ptx_log_probs = self.actor.get_base_model()(ptx, attention_mask=attention_mask)['logits'][..., :-1, :] ptx_loss = self.ptx_loss_fn(ptx_log_probs.view(-1, ptx_log_probs.size(-1)), label.view(-1)) actor_loss = ptx_loss * self.ptx_coef + actor_loss * (1 - self.ptx_coef) self.strategy.backward(actor_loss, self.actor, self.actor_optim) self.strategy.optimizer_step(self.actor_optim) self.actor_optim.zero_grad() # value loss values = self.critic(experience.sequences, action_mask=experience.action_mask, attention_mask=experience.attention_mask) critic_loss = self.critic_loss_fn(values, experience.values, experience.reward, action_mask=experience.action_mask) self.strategy.backward(critic_loss, self.critic, self.critic_optim) self.strategy.optimizer_step(self.critic_optim) self.critic_optim.zero_grad() return {'reward': experience.reward.mean().item()} def _set_default_generate_kwargs(strategy: Strategy, generate_kwargs: dict, actor: Actor) -> None: origin_model = strategy._unwrap_actor(actor) new_kwargs = {**generate_kwargs} # use huggingface models method directly if 'prepare_inputs_fn' not in generate_kwargs and hasattr(origin_model, 'prepare_inputs_for_generation'): new_kwargs['prepare_inputs_fn'] = origin_model.prepare_inputs_for_generation if 'update_model_kwargs_fn' not in generate_kwargs: new_kwargs['update_model_kwargs_fn'] = update_model_kwargs_fn return new_kwargs def save_model(self, path: str, only_rank0: bool = False, tokenizer: Optional[PreTrainedTokenizerBase] = None) -> None: self.strategy.save_model(model=self.actor, path=path, only_rank0=only_rank0, tokenizer=tokenizer)在获得最终模型权重后,还可通过量化降低推理硬件成本,并启动在线推理服务,仅需单张约 4GB 显存的 GPU 即可完成 70 亿参数模型推理服务部署