1.概要
本练习学习了OpenCv-Python关于图像特征识别的一些算法,算法理解起来较为困难,但函数用起来上手比较快,主要要明白函数的输入输出的含义。
2.主要内容:
虽然算法理解不容易,但程序还算有趣,输入是一个完整的图片和一组图片碎片,如下图,然后经过算法计算,把碎片匹配到正确的位置。
|
|
|

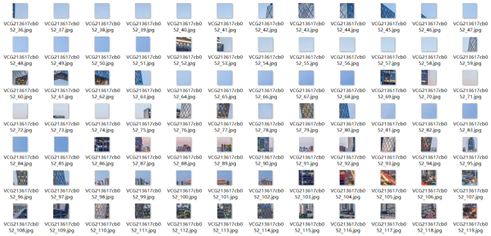
下面是算法识别结果,绿色范围内彩色的表示匹配成功,黑白的表示匹配失败
有些非特征区域或特征较少区域无法准确识别,因此有些没有匹配成功。

3.算法介绍
特征识别理解:一张图片,有的地方特征明显,例如角和边,但有的地方很难识别,例如空白区域,没有什么特征。正如下图,红色是一个角点,绿色是边,蓝色是空白,这其中,角点特征最明显。
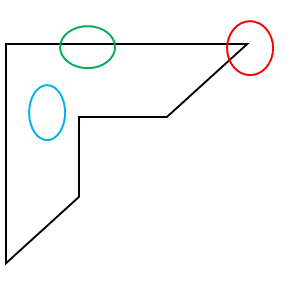
角点识别:算法很多,最基本的就是Harris Corner Detection,之后改进后成为Shi-Tomasi Corner Detector,还有五个比较经典的算法SIFT、SURF、FAST Algorithm for Corner Detection、BRIEF、ORB
特征匹配:主要有两种Basics of Brute-Force Matcher、FLANN based Matcher,他们可以在上面的角点识别之后使用。
从原理来说,对于图片,初步的理解就是使用算子对图像运算,找出结果中的特殊数值,然后对应图片中的位置。特征匹配就是线形代数的内容了,有点类似仿射变换。
4.环境配置
编程软件为Pycharm,需要安装opencv-python包,另外还用到了numpy,matplotlib可装可不装
写了两个py文件,第一个是封装的图片匹配的类,另一个是运行主程序
![]()
同目录下是待拼图的图片

基本的导入如下
import numpy as np
import cv2 as cv5.代码解析
首先介绍Conner_match_transfer这个文件
代码不多,结构如下,然后分别介绍每个部分
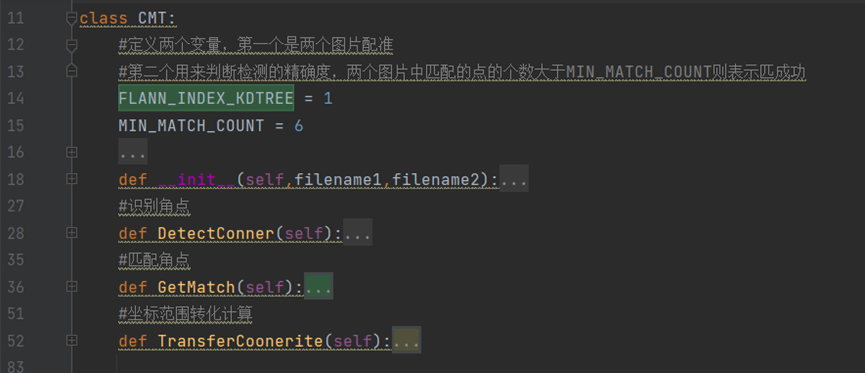
这个类导入了opencv-python包,主要进行以下三个过程的运算,对应其中的三个主要的函数
0.先看类结构,定义全局变量,定义构造函数
class CMT:
#定义两个变量,第一个是两个图片配准
#第二个用来判断检测的精确度,两个图片中匹配的点的个数大于MIN_MATCH_COUNT则表示匹成功
FLANN_INDEX_KDTREE = 1
MIN_MATCH_COUNT = 6
def __init__(self,filename1,filename2):
self.chiledMatchGBG=cv.imread(filename1)
self.chiledMatch=cv.imread(filename1, 0)
self.parntMatch=cv.imread(filename2, 0)
self.kp1 = None#待匹配的图片角点检测结果
self.kp2 = None#匹配参照图片角点检测结果
self.des1=None#待匹配的图片角点检测详细信息
self.des2=None#匹配参照图片角点检测详细信息
self.matchs=None#匹配成功的角点个数1.分别寻找两个图形的角点
本程序用的是sift算法,也可以尝试其他算法,步骤为构建对象-角点识别
def DetectConner(self):
#创建SIFT角点识别对象,是opencv内置的一个方法
sift = cv.SIFT_create()
# find the keypoints and descriptors with SIFT
#按照默认选项进行角点识别,返回角点和角点详细信息
self.kp1, self.des1 = sift.detectAndCompute(self.chiledMatch, None)
self.kp2, self.des2 = sift.detectAndCompute(self.parntMatch, None)2.匹配两个图形的角点
def GetMatch(self):
#构建用于FlannBasedMatcher的角点匹配参数
index_params = dict(algorithm=CMT.FLANN_INDEX_KDTREE, trees=5)
search_params = dict(checks=50)
#初始化FlannBasedMatcher匹配对象
flann = cv.FlannBasedMatcher(index_params, search_params)
#生成匹配结果
matches = flann.knnMatch(self.des1, self.des2, k=2)
# store all the good matches as per Lowe's ratio test.
#筛选出匹配精度较高的点
good = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good.append(m)
self.matchs=good3.匹配精度判断,若精度符合要求,则计算两个图像坐标转换矩阵,返回图片1对应于图片2中的坐标位置
def TransferCoonerite(self):
#若匹配精度高的点大于MIN_MATCH_COUNT,就几乎可以确定图片随便所在参照图片的位置
if len(self.matchs) > CMT.MIN_MATCH_COUNT:
#print(self.matchs)
#遍历所有的匹配结果,提取kp1中的点坐标,并构建np
src_pts = np.float32([ self.kp1[m.queryIdx].pt for m in self.matchs]).reshape(-1, 1, 2)
dst_pts = np.float32([ self.kp2[m.trainIdx].pt for m in self.matchs]).reshape(-1, 1, 2)
#生成匹配点的坐标转化矩阵
M, mask = cv.findHomography(src_pts, dst_pts, cv.RANSAC, 5.0)
matchesMask = mask.ravel().tolist()
#下面的代码进行图片碎片范围的提取,然后把范围坐标转化到参照图片的坐标系中,主要用M矩阵
h, w = self.chiledMatch.shape
pts = np.float32([[0, 0], [0, h - 1], [w - 1, h - 1], [w - 1, 0]]).reshape(-1, 1, 2)
dst = cv.perspectiveTransform(pts, M)
centerpoint=[int((dst[0,0,1]+dst[1,0,1])/2),int((dst[0,0,0]+dst[2,0,0])/2)]
halfH=int(h/2)
halfW=int(w/2)
while(centerpoint[0]<halfH or centerpoint[1]<halfW):
centerpoint[0]+=1
centerpoint[1]+=1
#得到坐标范围转化结果
rowandcol=((centerpoint[0]-halfH),centerpoint[0]+(h-halfH),centerpoint[1]-halfW,centerpoint[1]+(w-halfW))
#把parntMatch从单通道转化三三通道图像,便于后续贴图
self.parntMatch=cv.cvtColor(self.parntMatch,cv.COLOR_GRAY2RGB)
#返回结果,第一个是参照图片,第二个是图片碎片,第四个是碎片所在参照图片的位置(矩形),第五个是图片碎片所在参照图片的精确范围(可能不是矩形,识别畸变)
return (self.parntMatch,self.chiledMatchGBG,rowandcol,dst)
else:
#print("Not enough matches are found - {}/{}".format(len(self.matchs), CMT.MIN_MATCH_COUNT))
return False
matchesMask = None然后介绍Fast_PinTu.py这个文件,他主要是调用上面那个类,循环所有的图片碎片,然后把图片匹配的结果贴到原图上面。
from Conner_match_transfer import CMT
import numpy as np
import cv2 as cv
resluteparnt=None #用上一步贴过图的参照图片作为下一步的输入
k=0#记录贴图的图片个数
for i in range(1,188):
strname=''
if i<10:
strname='0'+str(i)
else:
strname=str(i)
#match1 = CMT('Pintu/Cereal/VCG211401617064_' + strname + '.jpg', 'Pintu/Cereal/VCG211401617064.jpg')
match1 = CMT('Pintu/ShangHai/VCG213617cb052_'+strname+'.jpg', 'Pintu/ShangHai/VCG213617cb052.jpg')
match1.DetectConner()
match1.GetMatch()
reslute=match1.TransferCoonerite()
if isinstance(reslute,tuple):
if k==0:
resluteparnt=reslute[0]
rowandcol=reslute[2]
chiledMatchGBG=reslute[1]
dst=reslute[3]
try:
resluteparnt[rowandcol[0]:rowandcol[1], rowandcol[2]:rowandcol[3]] = chiledMatchGBG
img2 = cv.polylines(resluteparnt, [np.int32(dst)], True, (0, 255, 0), 1, cv.LINE_AA)
resluteparnt = img2
print('正在识别第' + str(i) + '个,成功')
except Exception as e:
continue
k = k + 1
else:
print('正在识别第' + str(i) + '个,失败')
print(type(resluteparnt))
#显示图片imshow的第一个参数是窗口名称,第二个是np类型的图片矩阵
cv.imshow('Matcher',resluteparnt)
cv.waitKey(0)运行Fast_PinTu.py就可以得到上面的结果,从结果来看,图片中建筑密集区域识别效果较好,建筑边缘由于特征点不够可能无法正确识别,天空因为没有角点,几乎无法识别。