大家好,我是微学AI,今天给大家讲一下知识图谱中利用协同过滤算法寻找相似用户。大家会看到一个新的名词:“协同过滤”,下面来介绍一下协同过滤算法。
一、协同过滤算法
协同过滤算法是一种基于用户行为分析的推荐算法。它的基本思想是利用用户之间的相似性来推荐物品,即如果两个用户喜欢同一样物品,那么他们可能会喜欢相似的其他物品。
协同过滤算法可以分为两种类型:基于用户的协同过滤算法和基于物品的协同过滤算法。
基于用户的协同过滤算法首先计算用户之间的相似度,然后利用相似度为某个用户推荐物品。
基于物品的协同过滤算法则是首先计算物品之间的相似度,然后利用相似度为某个用户推荐和他喜欢的物品相似的其他物品。
协同过滤算法的实现也有多种方法,例如基于邻居的方法、基于矩阵分解的方法等。基于邻居的方法是指利用相邻的用户或物品进行推荐,其中相邻的定义可以根据不同的相似度度量方式进行定义。基于矩阵分解的方法则是将用户和物品的评分矩阵分解成两个较低维度的矩阵,从而可以通过乘积重构评分矩阵并进行推荐。 协同过滤算法具有简单直观、可扩展性强等优点,但也存在数据稀疏、冷启动等问题。因此需要根据具体场景进行算法选择和改进,以提高推荐效果。

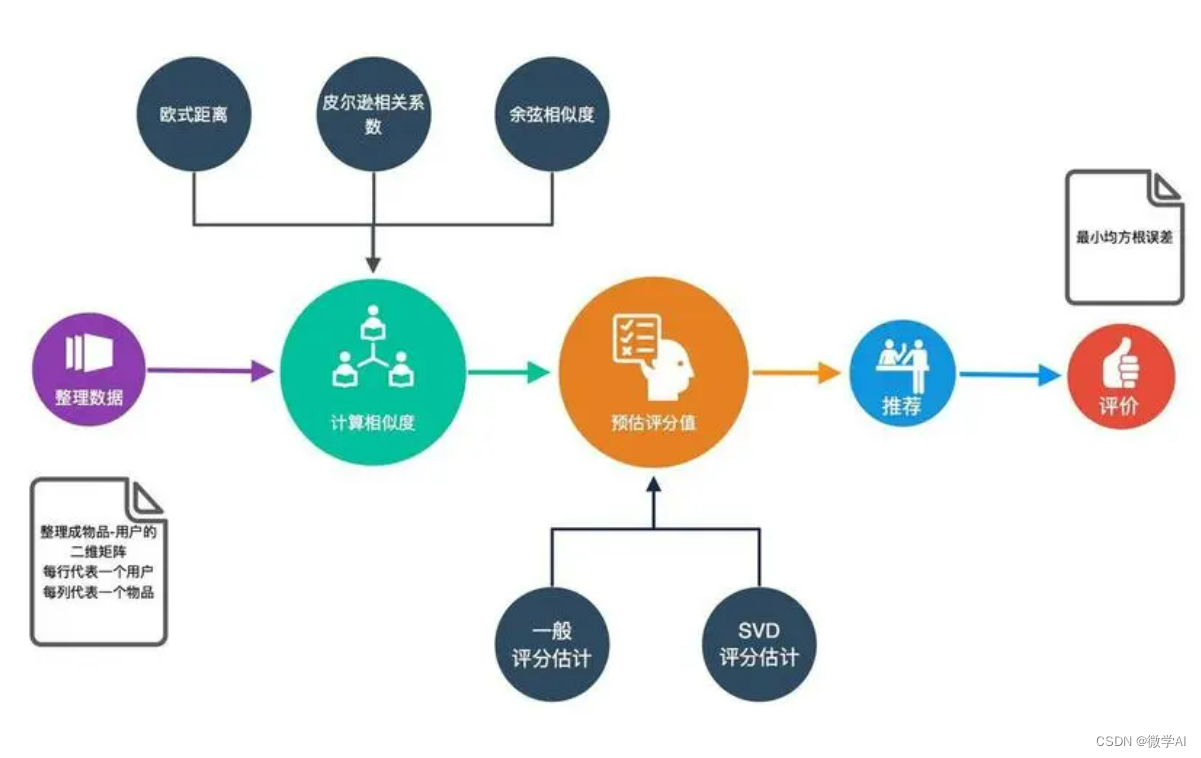
这张图可以生动形象地了解协同过滤算法的推荐过程。
二、协同过滤算法原理与操作
协同过滤算法,具体来说,对于每一个用户,算法会计算其与其他用户之间的相似度,然后根据相似度的大小,选取与其最相似的K个用户。对于每个物品,算法会找出它被前述K个最相似用户中的哪些用户喜欢过,然后将这些物品推荐给当前用户。 基于物品的协同过滤算法则是通过计算物品之间的相似度来推荐相似的物品。物品之间相似度通常也是基于余弦相似度或者皮尔逊相关系数计算得到。具体来说,对于每一个物品,算法会计算出其与其他物品之间的相似度,然后根据相似度的大小,选取与其最相似的前K个物品。对于当前用户的历史行为数据,算法会找出他曾经评价过或者购买过的物品中,与被推荐的物品最相似的前K个,并将这些物品作为推荐结果返回给用户。 需要注意的是,协同过滤算法本身是基于历史数据进行推荐,对于没有历史数据或仅有一个或两个评分的用户或物品,算法可能存在数据稀疏的问题。在面对这种情况时,需要采取特殊的算法方法或者引入其他辅助信息以解决数据稀疏带来的推荐问题。
三、代码实现
import pandas as pd
from sklearn.metrics.pairwise import cosine_similarity
def find_similar_users(user_id, ratings_df, num_users=5):
"""
基于用户的协同过滤算法,找到与给定用户最相似的用户
参数:
user_id (int): 需要找到相似用户的用户ID
ratings_df (pandas.DataFrame): 用户电影评分数据框,包含三列:userId, movieId, rating
num_users (int): 返回的相似用户数量,默认为5
返回:
similar_users (list): 与给定用户相似度最高的num_users个用户的ID和相似度,按照相似度从高到低排名
"""
# 构建用户-电影评分矩阵
user_movie_matrix = ratings_df.pivot_table(index='userId', columns='movieId', values='rating', fill_value=0)
# 计算相似度矩阵
sim_matrix = cosine_similarity(user_movie_matrix)
# 获取给定用户的相似度向量
user_sim_vector = sim_matrix[user_id-1]
# 获取所有用户的相似度向量
all_sim_vectors = sim_matrix[:,user_id-1]
# 构建相似度DataFrame
sim_df = pd.DataFrame({'userId': ratings_df['userId'].unique(), 'similarity': all_sim_vectors})
# 根据相似度从高到低排序,排除自己
sim_df = sim_df[sim_df['userId'] != user_id].sort_values(by='similarity', ascending=False).head(num_users)
# 返回相似用户列表
similar_users = list(zip(sim_df['userId'], sim_df['similarity']))
return similar_users
ratings_df = pd.read_csv('ratings.csv')
similar_users = find_similar_users(2, ratings_df, num_users=8)
ratings_df = pd.read_csv('ratings.csv')
similar_users = find_similar_users(2, ratings_df, num_users=8)
for i in similar_users:
print(f'用户id:{i[0]},相似度:{i[1]}')运行结果:
用户id:7,相似度:0.9849057238849922
用户id:5,相似度:0.5686318341859367
用户id:1,相似度:0.5387724584403655
用户id:4,相似度:0.45127214755828327
用户id:3,相似度:0.35855967894562796
用户id:6,相似度:0.3521566452468871
相似的用户按照顺序排序下来。
欢迎大家持续关注,谢谢!